

Self-adaptive training method and system for acoustic model
A training method and technology for acoustic models, applied in the field of adaptive training methods and systems for acoustic models, can solve problems such as damage to seed model information, reduce overfitting, reduce overfitting, and improve recognition rates. Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
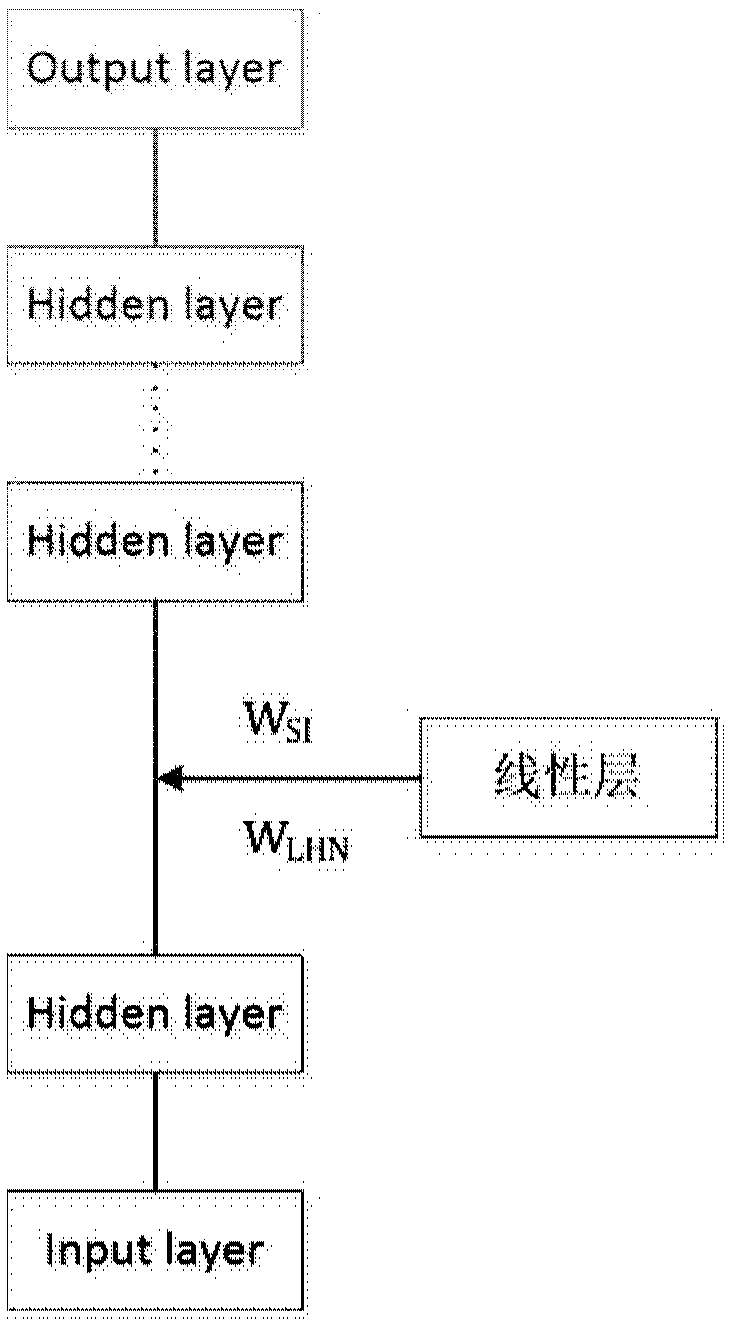
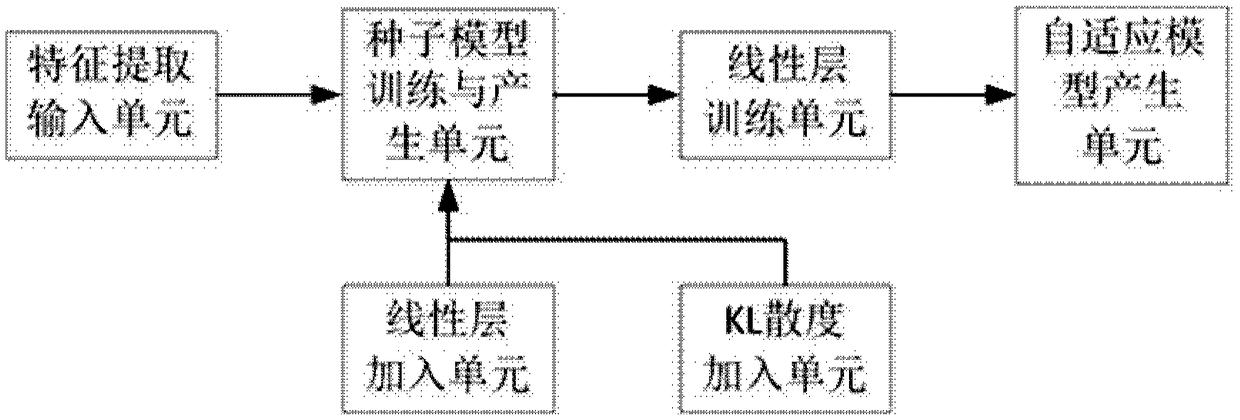
[0040] This disclosure provides an adaptive training method and system for an acoustic model, combining the advantages of LHT and KL divergence, using adaptive data to retrain the neural network model, to achieve the purpose of slowing down the mismatch between training data and scene data, and ensuring Improve the accuracy of the model during the adaptation process.
[0041] Before describing a solution to a problem, it is helpful to define some specific vocabulary definitions.
[0042] KLD Kullback-Leibler divergence KL divergence
[0043] LHT Linear Hidden Transformations linear hidden transformation
[0044] HMM Hidden Markov Model Hidden Markov Model
[0045] DNN Deep Neural Networks Deep Neural Networks
[0046] In order to make the purpose, technical solutions and advantages of the present disclosure clearer, the present disclosure will be further described in detail below in conjunction with specific embodiments and with reference to the accompanying drawings.
[0...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More