

A Spark-Based Anti-skew Data Fragmentation Method
A technology for data sharding and data output, applied in the field of data engines, it can solve the problem of anti-skew mechanism, inability to handle shard skew, etc., and achieve the effect of sharding load
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0098] The present invention will be further described below in conjunction with examples.
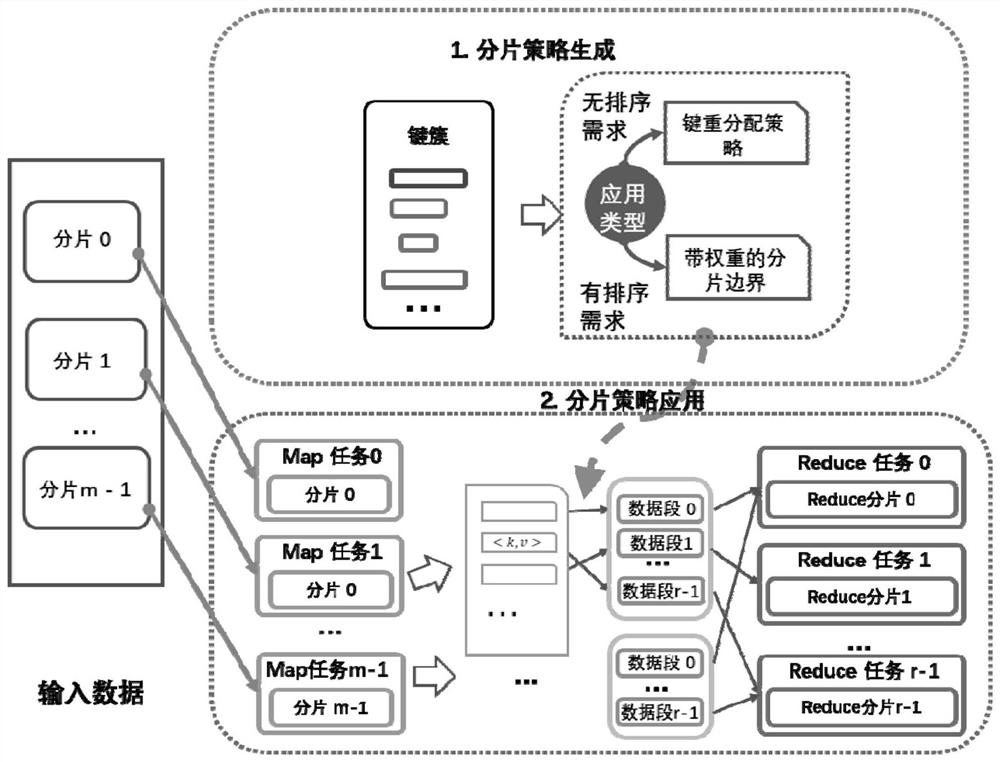
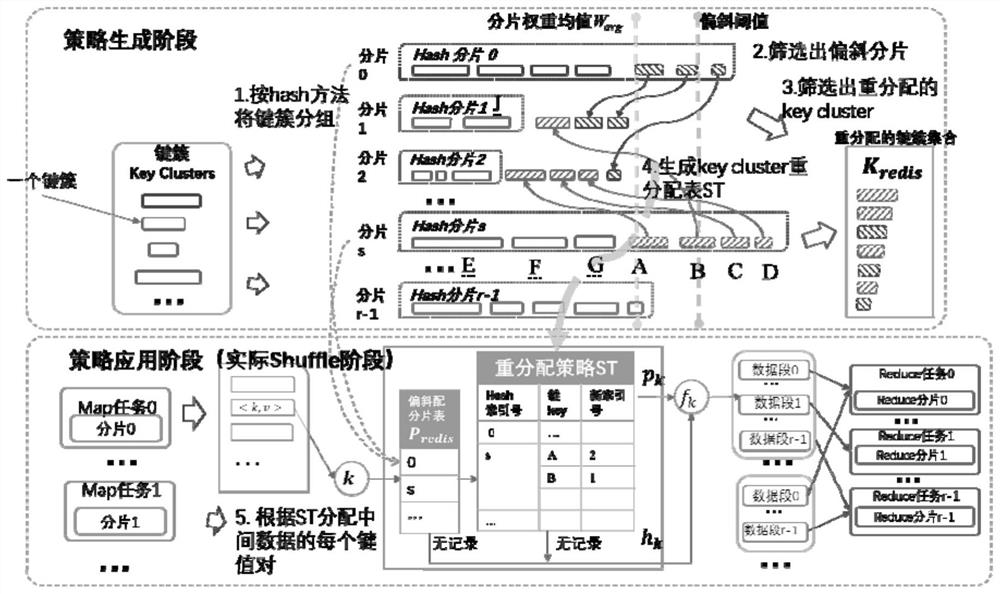
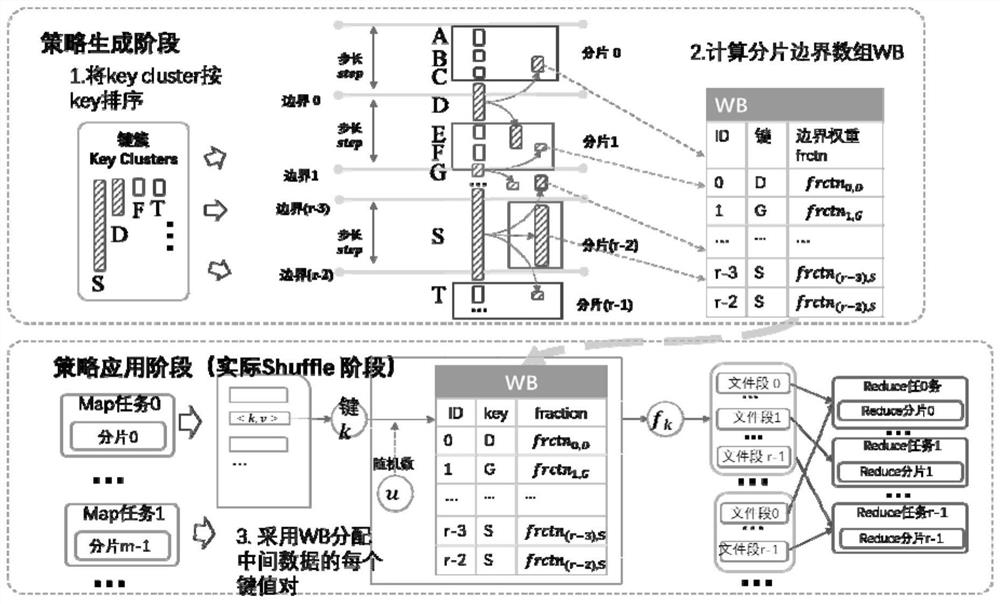
[0099] The anti-skew data sharding method based on Spark provided by the present invention can formulate a suitable sharding strategy according to the distribution of intermediate data key clusters (key cluster) and the type of Spark application. Such as figure 1 As shown, the whole process is divided into two parts, the generation of fragmentation strategy and the application of fragmentation strategy. Among them, for different types of Spark applications, different methods are used in policy generation and application. For operations with sorting requirements, use the range sharding algorithm strategy based on key cluster segmentation to generate a weighted boundary array; for other operations, use the hash algorithm strategy based on key cluster redistribution to generate skewed sharding tables and Redistribution policy table. When the sharding strategy is generated, it is only s...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More