Image title automatic generation method based on multi-modal attention
An attention, multi-modal technology, applied in the intersection of computer vision and natural language processing, can solve the problem that semantic information does not have strict alignment relationship, the number of categories is limited, does not contain, etc., to alleviate visual features and semantic features. Alignment problems, solving visual and semantic alignment problems, and improving quality
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
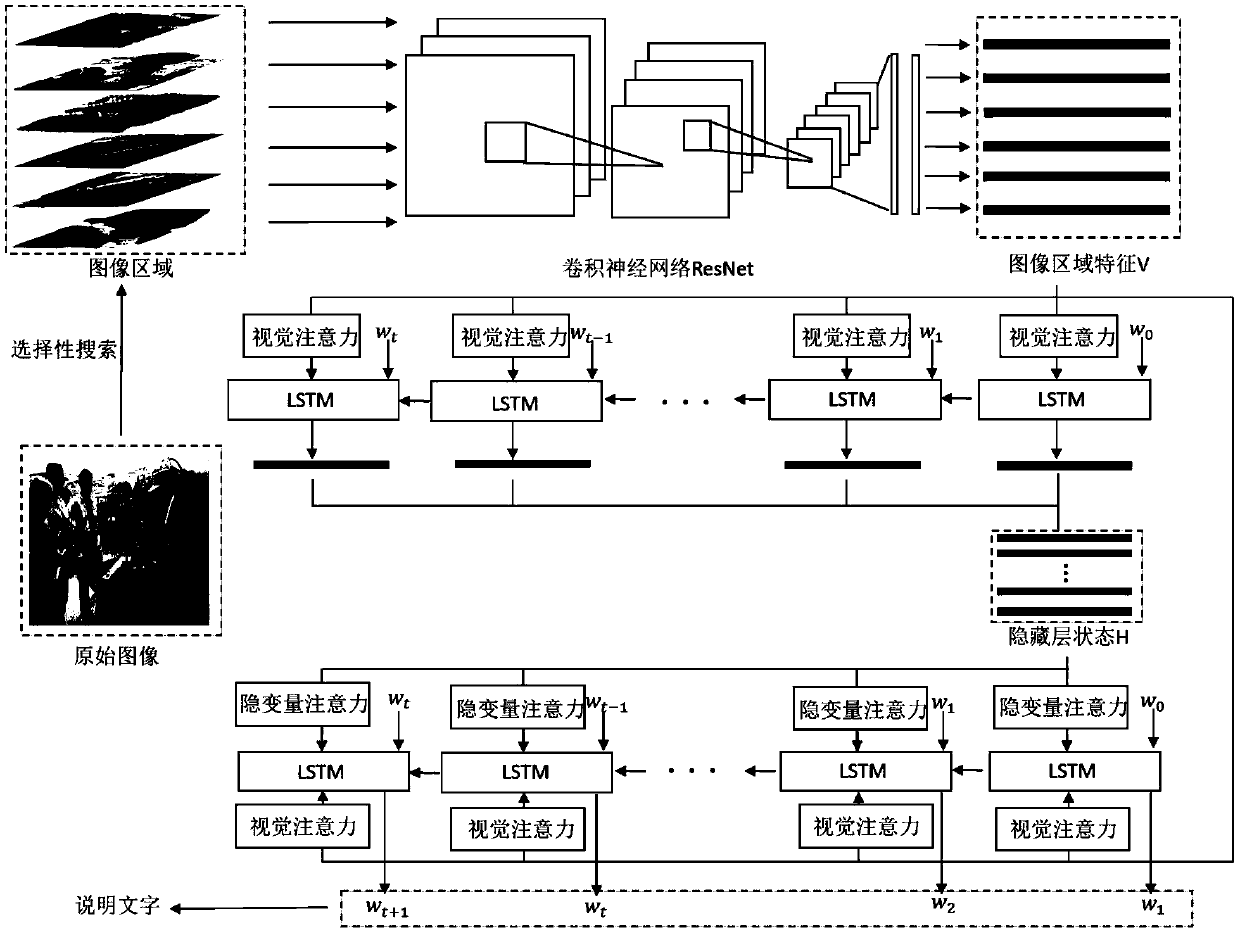
[0019] The present invention provides a method for automatically generating image captions based on multimodal attention. The specific embodiments discussed are merely illustrative of implementations of the invention, and do not limit the scope of the invention. Embodiments of the present invention will be described in detail below in conjunction with the accompanying drawings, a method for automatically generating image titles based on multimodal attention, the specific steps are as follows:
[0020] (1) Image preprocessing
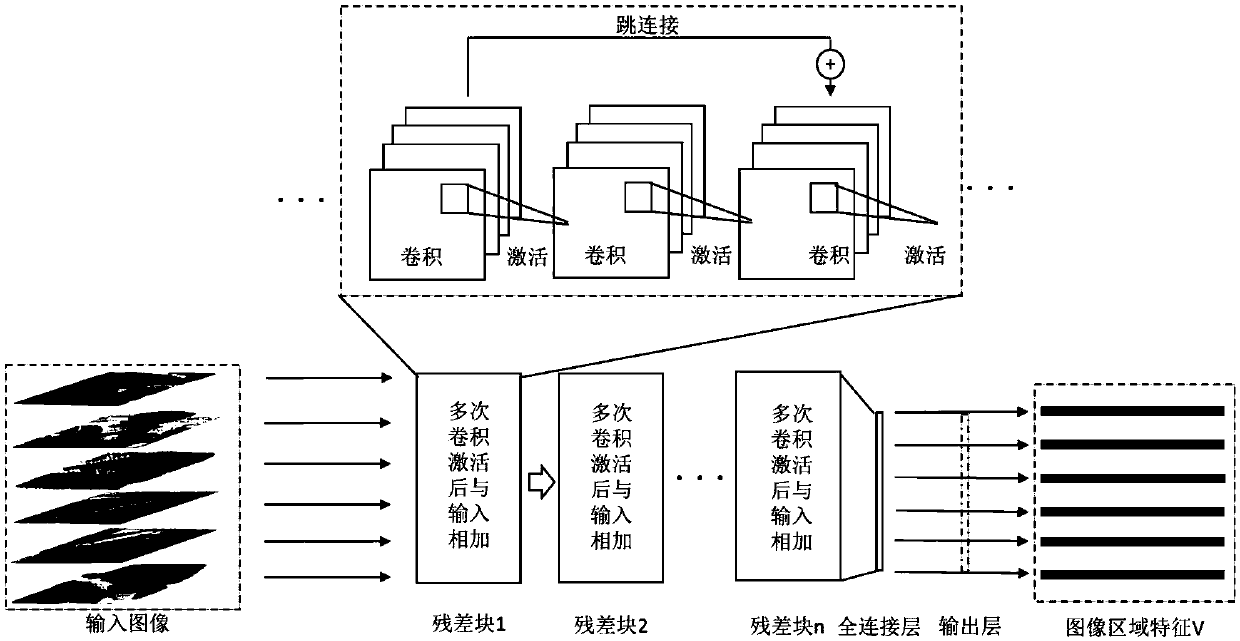
[0021] Image regions containing objects are extracted from the original image using a selective search algorithm. The size of these image regions is different, and it is not suitable for subsequent feature extraction through the ResNet convolutional neural network. Therefore, the present invention scales the extracted image area so that its size can meet the requirements, and meanwhile normalizes the image pixel values.
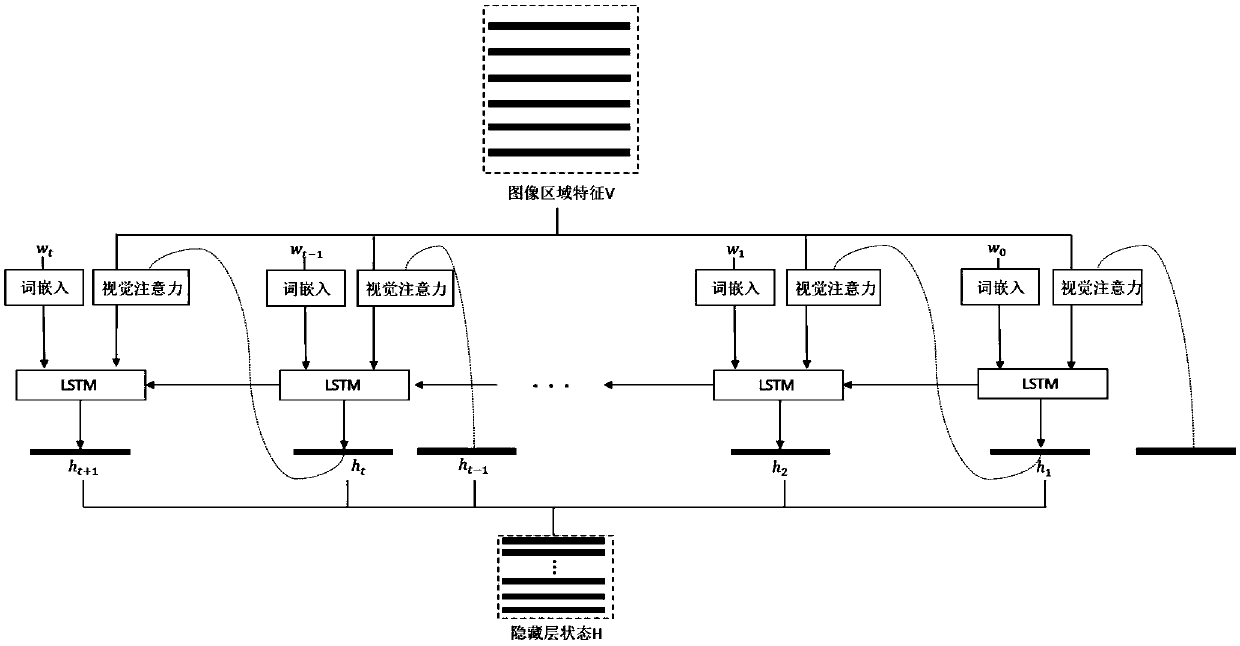
[0022] (2) Extraction of image ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - Generate Ideas
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com