

Method and system for core process knowledge intelligent pushing based on multi-model fusion
A technology knowledge, multi-model technology, applied in the computer field, can solve problems such as large amount of similarity calculation, difficulty in expressing files and queries, errors in corpus, etc., and achieve the effect of improving the classification effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
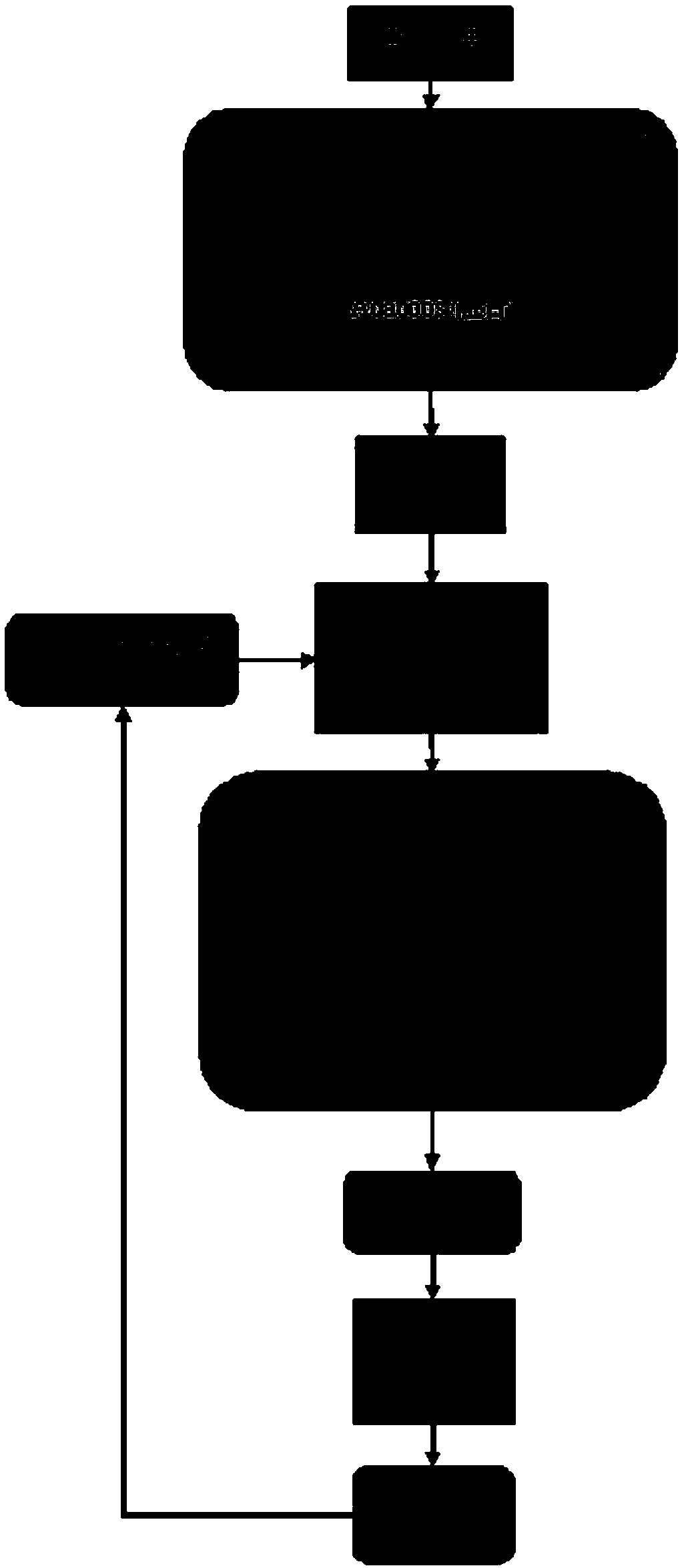
[0126] see figure 1 , an intelligent push method for core process knowledge based on multi-model fusion, comprising the following steps:
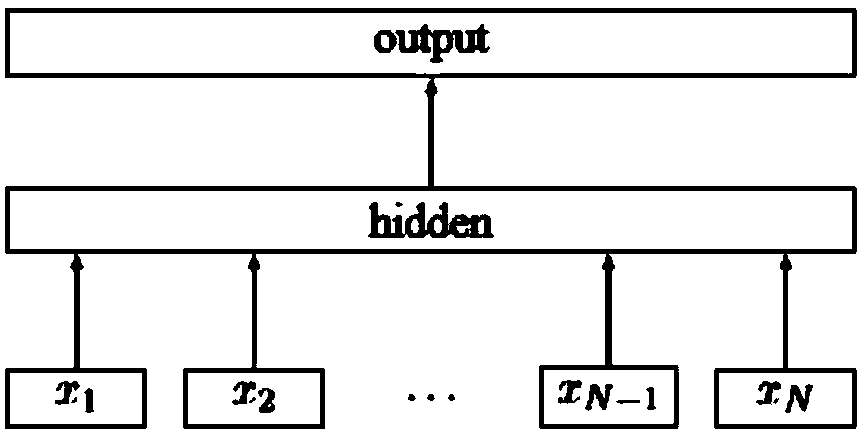
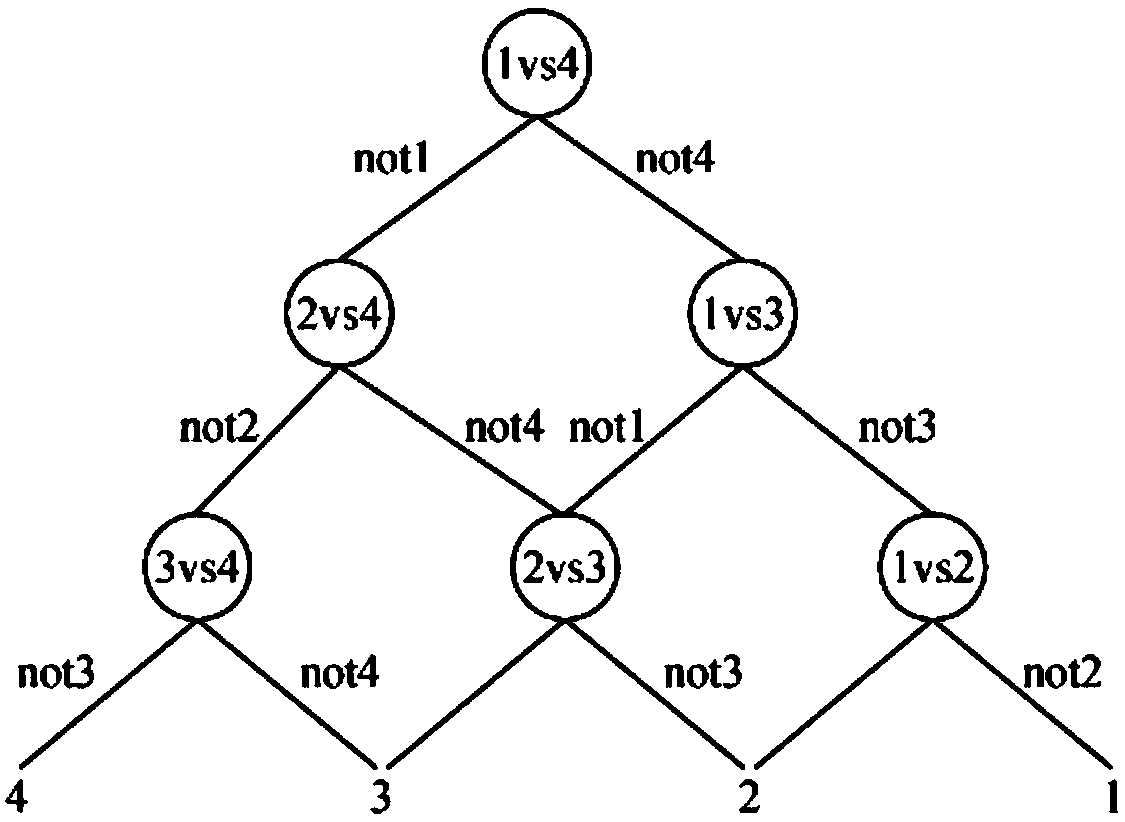
[0127] 1) Text classification: all texts are preprocessed, and then the processed text is input into a classifier for pre-classification to obtain text category information, which is a model vector representation of the category as a whole; the text of this embodiment is the source of corpus data: Tsinghua public Chinese dataset, download address: https: / / ctwdataset.github.io / downloads.html . In step 1), the Adaboost algorithm is used to fuse a variety of different types of basic classifiers to form a final classifier, and the processed data is input into the final classifier for pre-classification to obtain category information; different types of basic classifiers include the Jaccard coefficient-Knn model , fastText deep learning model, Rocchio model, multi-classification SVM model; The steps of using Adaboost algorithm to fuse mul...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More