CTR estimation method and system based on fm algorithm
An algorithm and model technology, applied in the computer field, can solve the problems of lack of generalization, difficulty in implementation, and high complexity, and achieve the effect of enhancing generalization ability.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

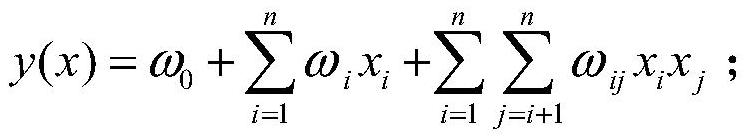
Examples
Embodiment 1
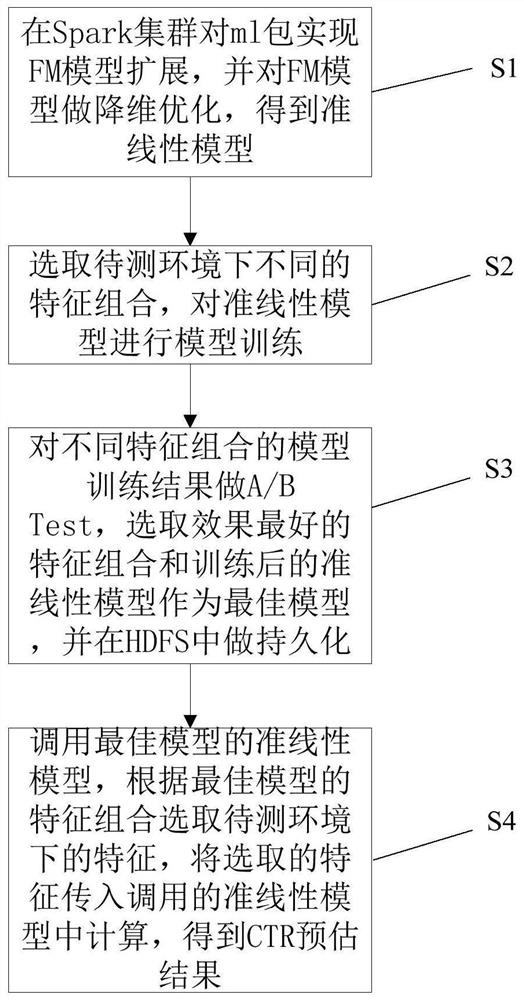
[0040] A CTR estimation method based on FM algorithm, see figure 1 ,include:
[0041] S1: Extend the FM model to the ml package in the Spark cluster, and perform dimensionality reduction optimization on the FM model to obtain a quasi-linear model;
[0042] Specifically, Spark clusters can be used to build large-scale, low-latency data analysis applications. Spark enables in-memory distributed datasets, which can optimize iterative workloads in addition to being able to provide interactive queries. Spark is implemented in the Scala language, which uses Scala as its application framework, and the language features of Scala have also made most of Spark's success.
[0043] Step S1 refers to the machine learning library implemented by Spark, which makes the actual machine learning scalable and easy to use. In step S1, while relying on Spark to implement the FM algorithm, it also considers Spark’s official recommendation to implement the DataFrame API instead of the RDD API, beca...
Embodiment 2
[0054] Embodiment 2 On the basis of Embodiment 1, the following content is added:
[0055] The FM model is the sum of the linear model objective function and the cross combination feature, and the objective function of the FM model is as follows:
[0056]
[0057] Quadratic parameter ω ij A symmetric matrix W is formed, and the symmetric matrix W is decomposed into W=V T V, the jth column of V is the hidden vector of the jth dimension feature, each parameter ω ij =i ,v j >, so the FM model can be transformed into:
[0058]
[0059] where ω 0 ∈R,V∈R n×k , R is a real number, R n×k is a matrix of n×k, n is the number of sample features, k is the length of the hidden vector, where k is much larger than n, i, j are variables, x i is the value of the i-th feature, v i for x i Hidden vector of , ω 0 and ω i are the parameters of the FM model.
[0060] In terms of time complexity, the time complexity of direct calculation should be O(kn 2 ), since all pairwise inte...
Embodiment 3
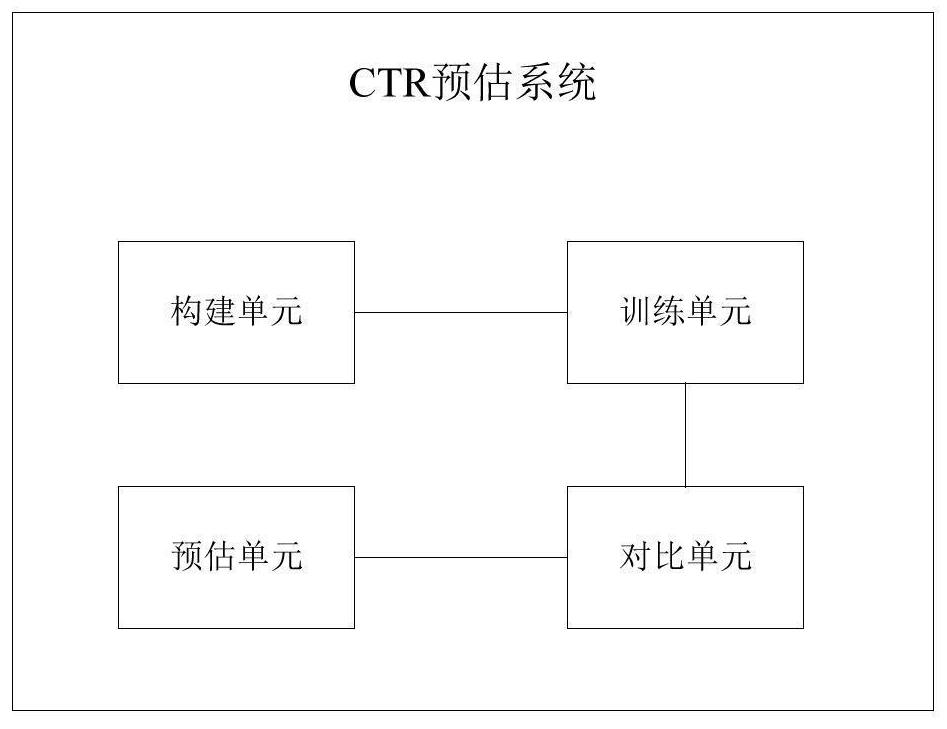
[0067] A CTR estimation system based on FM algorithm, see figure 2 ,include:
[0068] Construction unit: used to implement the FM model extension of the ml package in the Spark cluster, and perform dimensionality reduction optimization on the FM model to obtain a quasi-linear model;
[0069] Training unit: used to select different feature combinations in the environment to be tested, and perform model training on the linear model;
[0070] Comparison unit: do A / B Test on the model training results of different feature combinations, select the best feature combination and the trained quasi-linear model as the best model, and persist it in HDFS;
[0071] Estimation unit: used to call the quasi-linear model of the best model, select the features in the environment to be tested according to the feature combination of the best model, and pass the selected features into the called quasi-linear model for calculation to obtain the CTR prediction result.
[0072] Further, the object...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com