

integrated automatic lexical analysis method and system for ancient Chinese texts
An analysis method and automatic word technology, applied in special data processing applications, instruments, electronic digital data processing, etc., can solve the problems of low accuracy, slow training speed, and difficulty in lexical analysis in ancient Chinese, and achieve simple operation, The effect of high efficiency and shortening of training time
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image



Examples
Embodiment 1
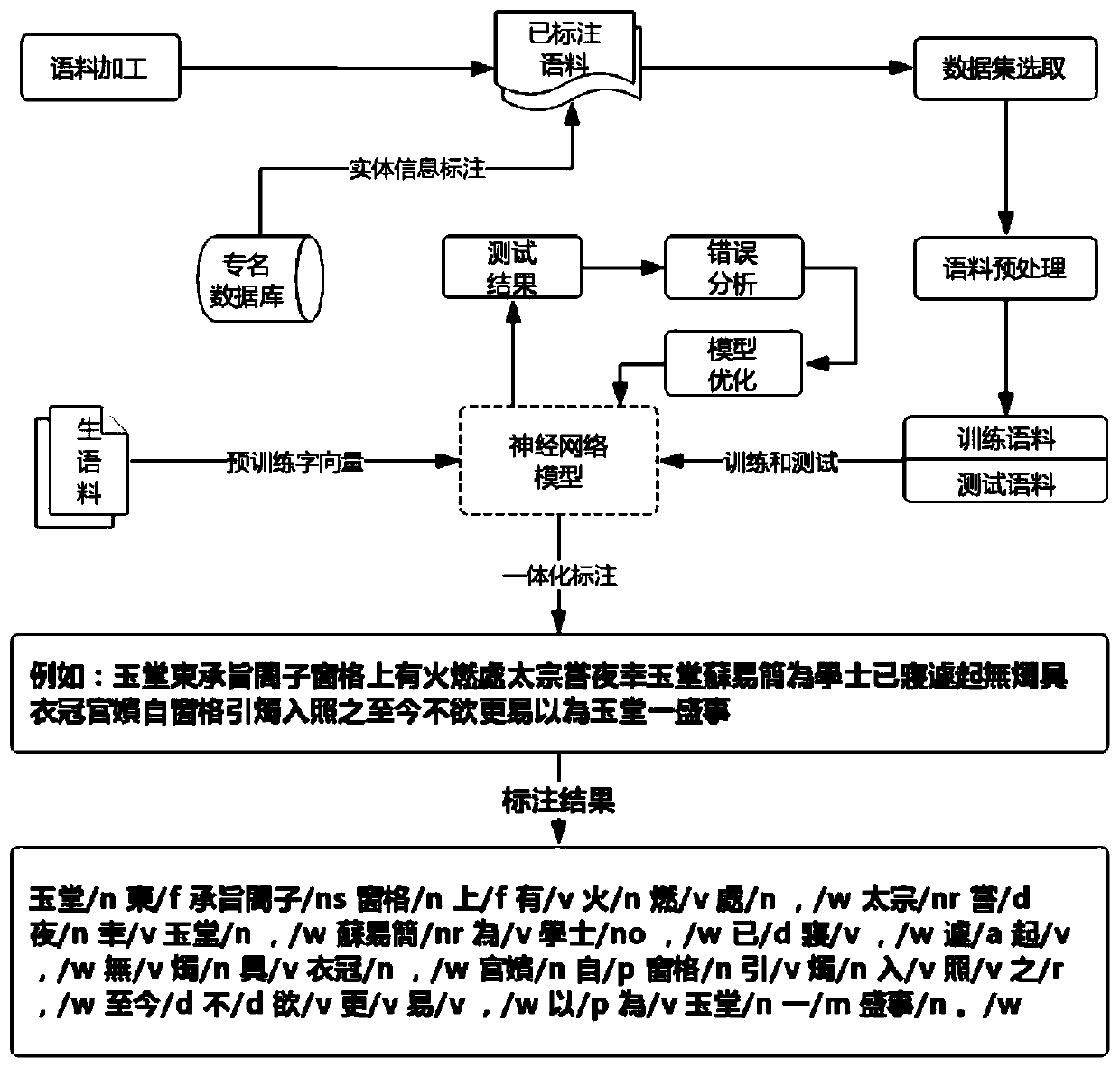
[0037] Such as figure 1 As shown, ancient Chinese documents are written in traditional characters, and most of the ancient texts do not have sentence segmentation information. This brings great inconvenience to the reading and research of ancient Chinese.
[0038] Table 1 uses OCR (optical character recognition) technology to figure 1 The scanned text is as follows:
[0039]
[0040] To conduct an integrated lexical analysis of this electronic document, the specific tasks are as follows:
[0041] (1) Automatically segment the text;
[0042] (2) Automatically segment the text;
[0043] (3) Determine the part of speech of words, such as nouns, verbs, etc.;
[0044] (4) Identify named entities such as person names and place names in ancient Chinese.
[0045] The present invention uses an integrated analysis method to synchronize the above tasks, and automatically annotates the results figure 2 Shown. Each word is separated by " / ", followed by the part-of-speech tag of the word, and each s...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More