

A software defect prediction method based on less sample data learning
A software defect prediction and sample data technology, applied in software testing/debugging, computer parts, instruments, etc., can solve the problems of model performance dependence, high algorithm complexity, defect historical data, etc., to achieve good prediction results and stable performance Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

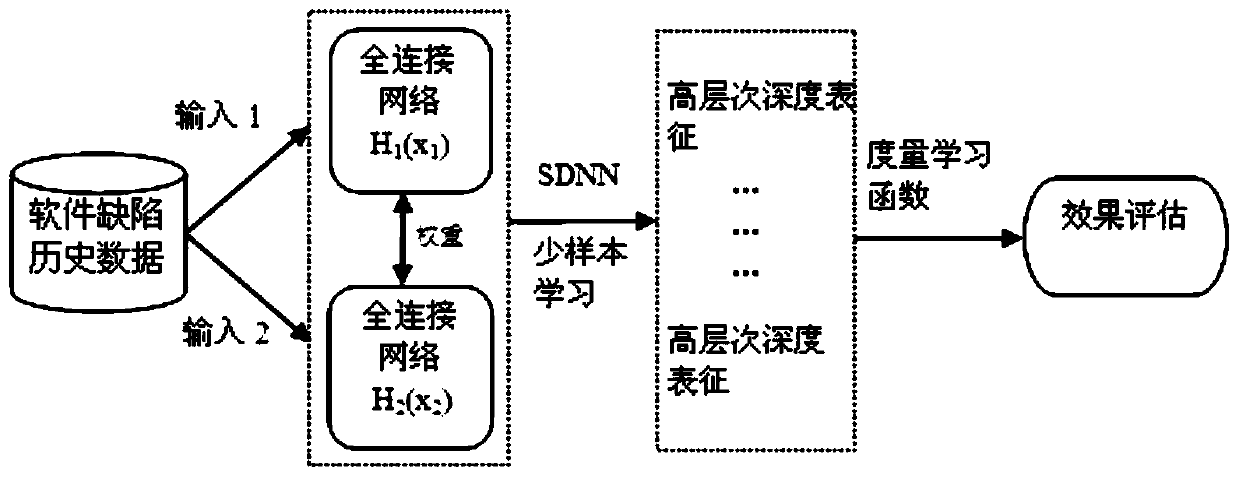
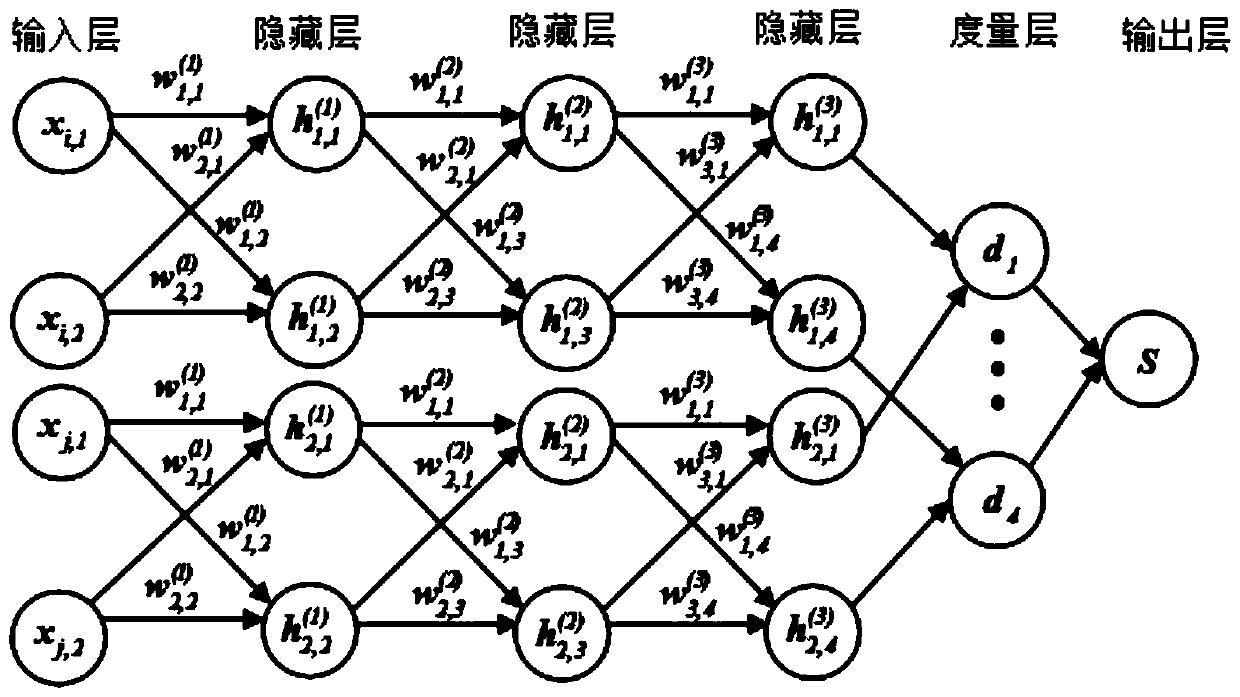
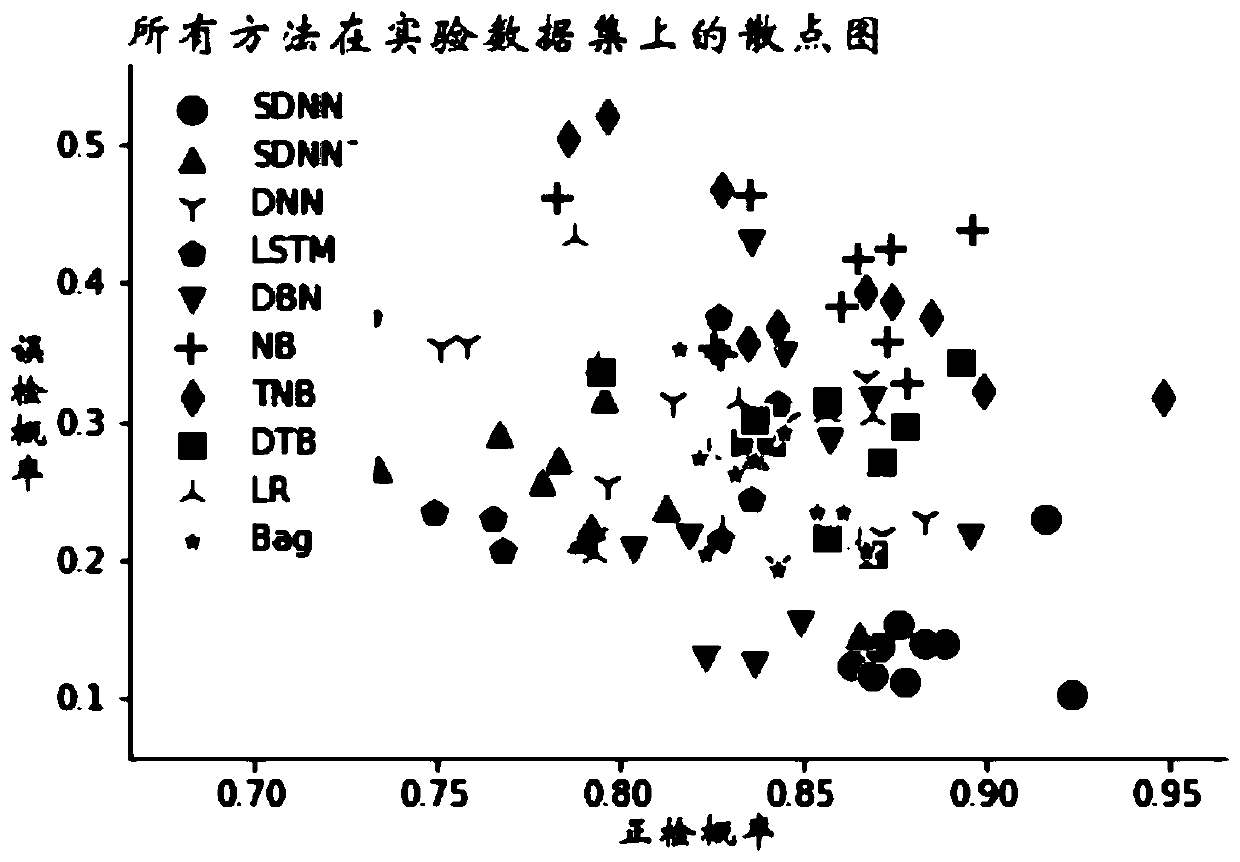
Examples
specific Embodiment
[0052] (1) Experimental data
[0053] The NASA data warehouse contains many different software defect data sets. The experiment extracts 10 data sets from the warehouse for experimental analysis. They are AR1, AR4, AR6, CM1, KC1, KC2, MW1, PC1, PC3 and PC4. The extraction principle is that all experimental data come from public machine learning databases, making the invented method easy to verify and apply; and the selected data sets have the same measurement indicators, and the experimental data can be used directly without losing any measurement information during the experiment .
[0054] Note that the attribute dimensions of these data sets are not uniform, the minimum dimension is 21, the maximum dimension is 57, and their classes are also unbalanced, the minimum imbalance degree is 3, and the maximum imbalance degree is 12. Moreover, the instances of each dataset are limited, with a minimum of 87 and a maximum of 2032. Therefore, it is difficult for conventional machin...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More