

A PDF document content text paragraph aggregation method based on a neural network
A neural network and document technology, applied in the field of neural network-based aggregation of PDF document content text paragraphs, can solve a large number of human resources and other problems, and achieve the effects of saving labor costs, facilitating reuse, and improving efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
[0020] In order to facilitate the understanding and implementation of the present invention by those of ordinary skill in the art, the present invention will be further described in detail with reference to the accompanying drawings and embodiments. It should be understood that the implementation examples described here are only used to illustrate and explain the present invention, and are not intended to limit this invention.
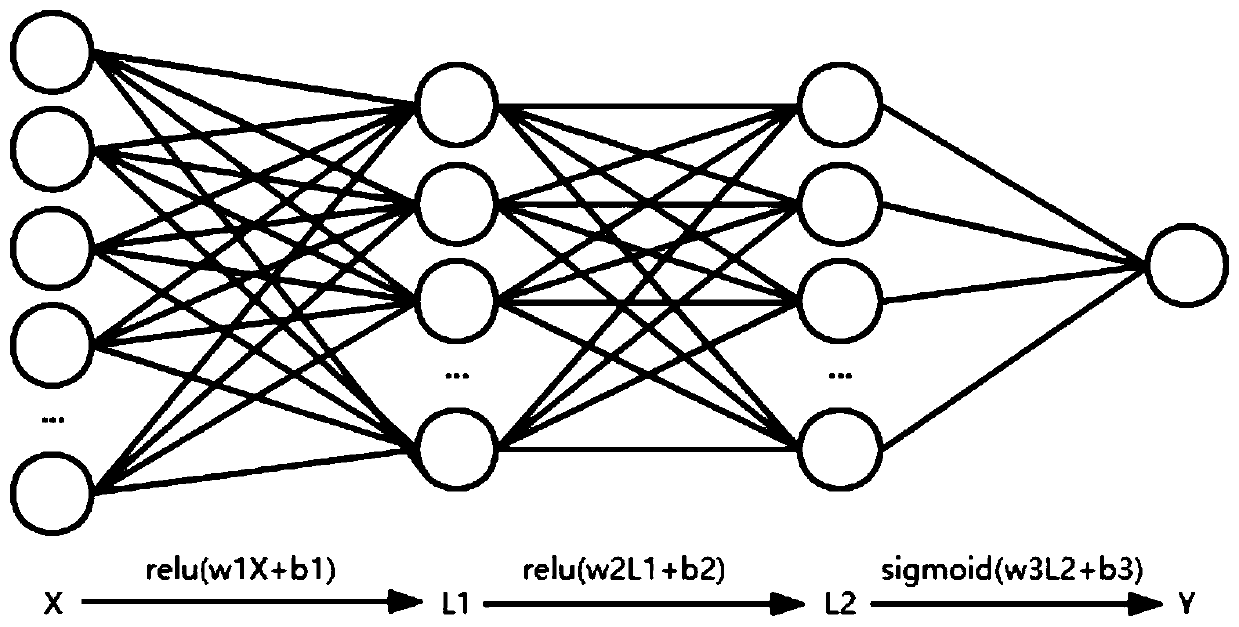
[0021] Please see figure 1 , A method for aggregating text paragraphs of PDF document content based on neural network provided by the present invention includes the following steps:
[0022] Step 1: For a number of PDF documents, extract the line text information features of each PDF document;
[0023] In this embodiment, the line text information features include line left margin, line right margin, number of characters, line maximum character height, line minimum character height, line maximum character width, line minimum character width, line maximum char...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More