

English handwriting identification method based on improved VGG-16 model
A VGG-16, English technology, applied in the field of computer vision, can solve the problems of imperfect handwriting identification theory, high degree of writing diversification, single structure, etc., and achieve the effect of rapid network stabilization, saving training time, and rapid convergence
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
[0033] A kind of English handwriting identification method based on improved VGG-16 model, the method comprises the following steps:
[0034] 101: Collect a dataset of English documents from different handwritings of different people;
[0035] 102: Segment the obtained handwritten English handwriting document into words to obtain a data set composed of English words, and construct a training sample set and a test sample set based on the data set;
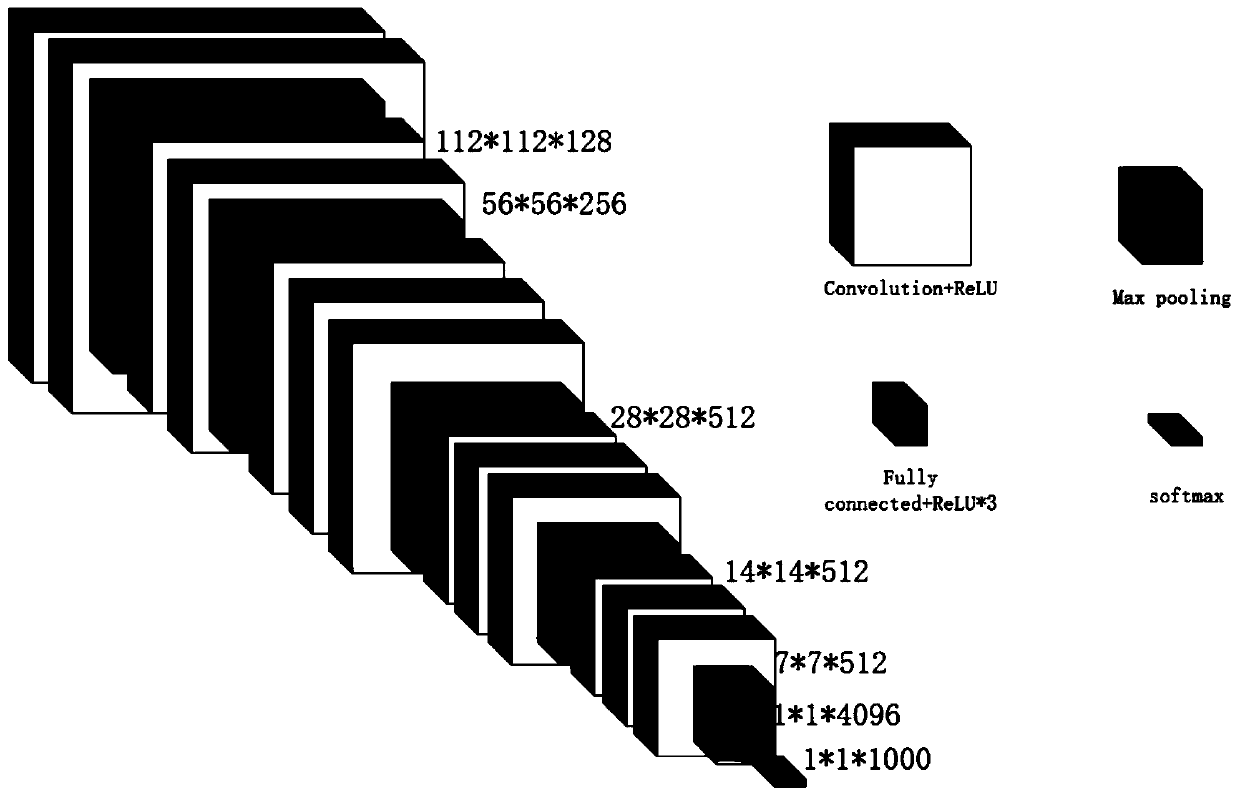
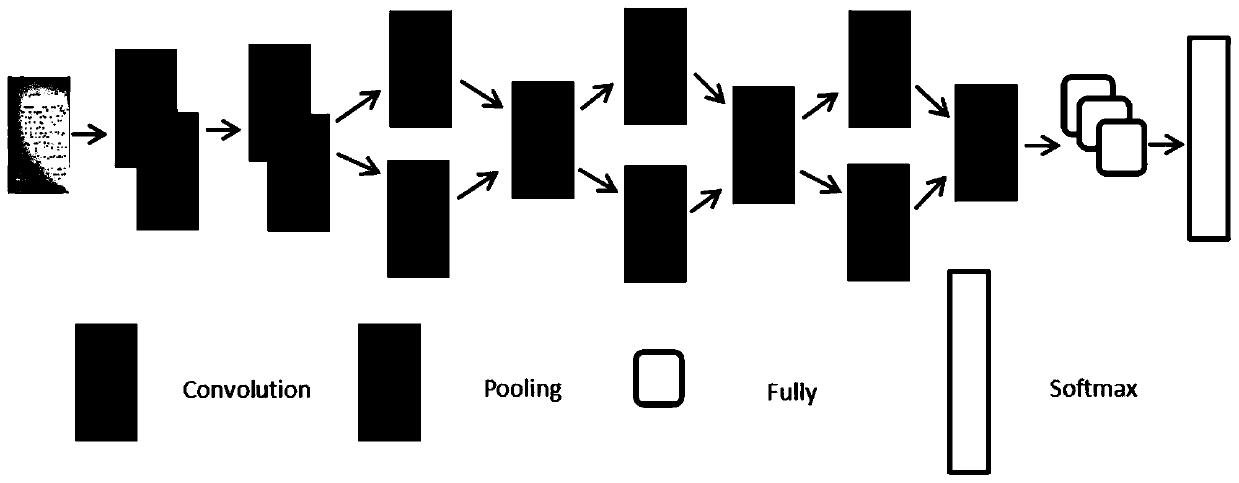
[0036] 103: Based on the VGG-16 model, improve the VGG-16 model and construct a convolutional neural network. The improved VGG-16 model includes 2 traditional convolutional layers, 3 composite convolutional layers, 5 pooling layers and 3 fully connected layers;
[0037] 104: Input a training sample set, extract character features, and perform classification training; wherein, the sizes of the training sample set and the test sample set are both 320*320 pixels;
[0038] 105: Use the trained neural network to automatically identify ...
Embodiment 2
[0044] The following is combined with specific examples, calculation formulas, Figure 1-Figure 4 , Table 1 further introduces the scheme in Embodiment 1, see the following description for details:
[0045] 201: Obtain a training sample set and a test sample set for each English word;
[0046] First, the orthorectification is performed on the handwritten English document image, and then the single English word is segmented into rows and columns by the projection method to obtain the English word data set. Among them, the relevant texts of 130 people's handwritten English documents are collected as a data set, and each person writes an English document, including about 240 words, such as figure 1 As shown, classify tagged image information. Finally, the total number of words in the training sample set is 26,000, and the total number of words in the test sample set is 2,600. Normalize the size of the segmented English word image to 320*320 pixels, and set the data type to the...
Embodiment 3
[0073] Combine below Figure 5 , and Table 2-Table 4, the scheme in Embodiment 1 and 2 is further introduced, see the following description for details:
[0074] In order to verify the effectiveness of the method for English handwriting identification, it was tested, and the test results are as follows:
[0075] In the embodiment of the present invention, two evaluation standards, Mean Average Precision (MAP) and Hard top-k, are used to quantitatively evaluate the handwriting identification results of English handwriting.
[0076] 1) The formula for calculating the average accuracy rate:
[0077]
[0078] Among them, m represents the number of handwriting materials in the query database, n represents the handwriting materials to be queried, and R represents the total number of documents in the database that are the same as the i-th handwriting; P(k) represents the identification accuracy of the first k results, that is, the top k results The ratio of the number of related...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More