Methods and systems for external connection of tables of database
An external connection and database technology, applied in the database field, can solve the problems of inability to directly use the broadcast appearance and reduce the execution efficiency, so as to reduce the amount of transmission and calculation, improve the efficiency of execution, and reduce the amount of network transmission.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0030] The detailed features and advantages of the present invention are described in detail below in the specific embodiments, the content of which is sufficient to enable any person skilled in the art to understand the technical content of the present invention and implement it accordingly, and according to the specification, claims and drawings disclosed in this specification , those skilled in the art can easily understand the related objects and advantages of the present invention.
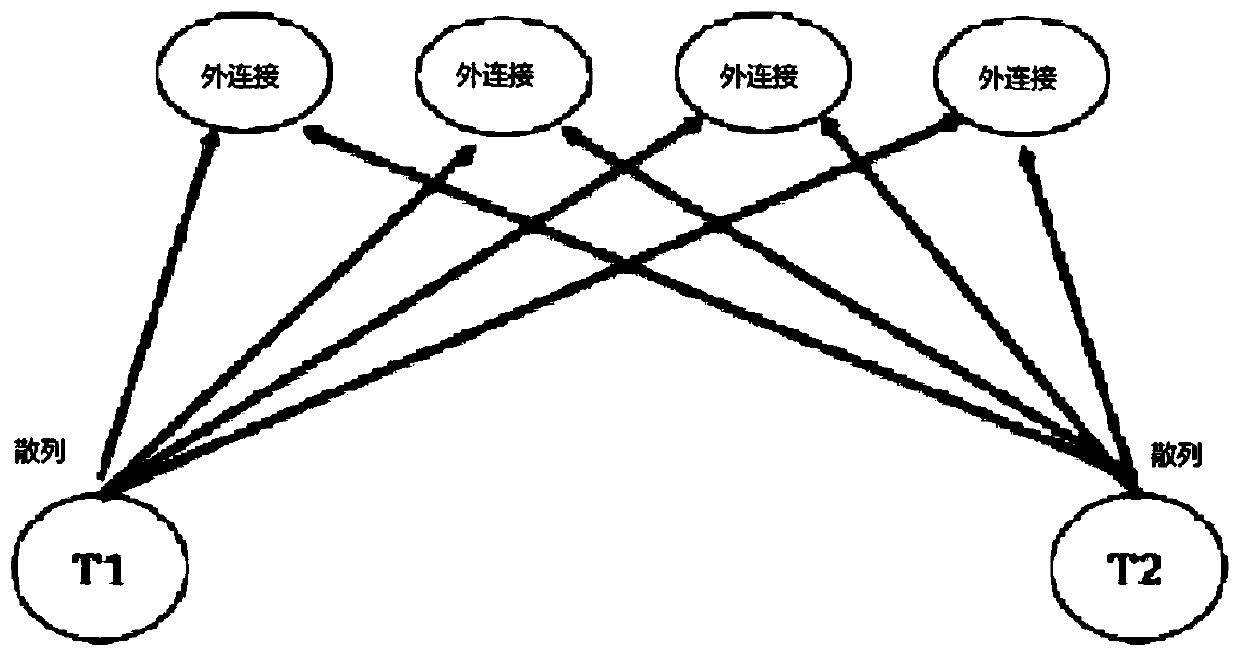
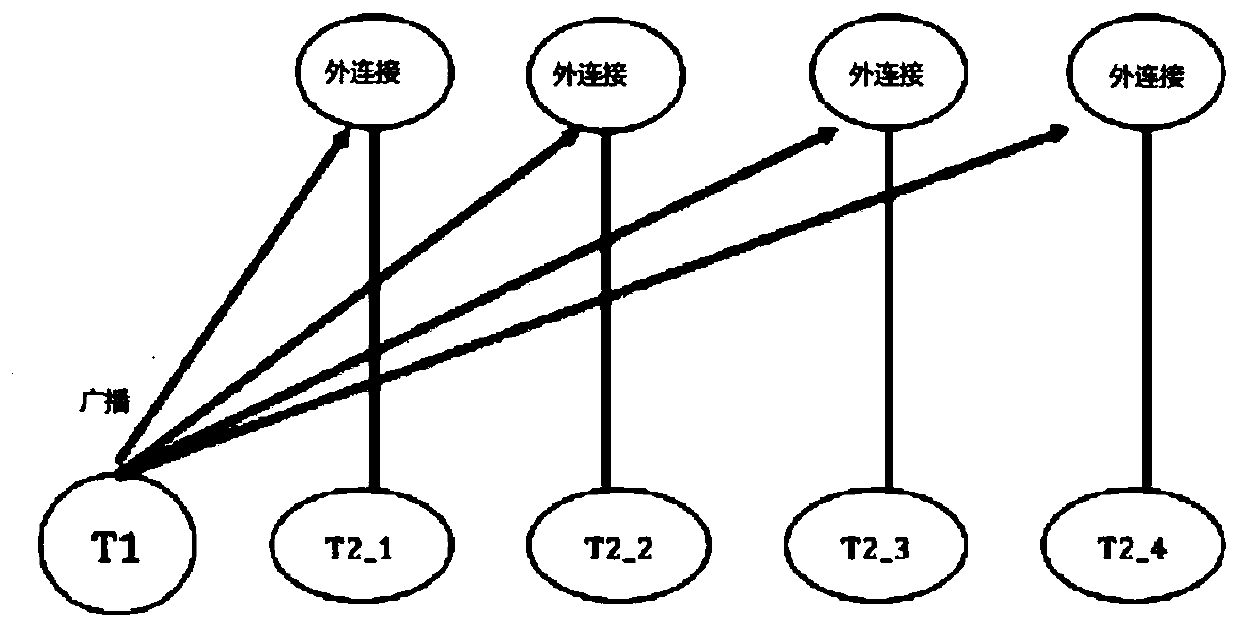
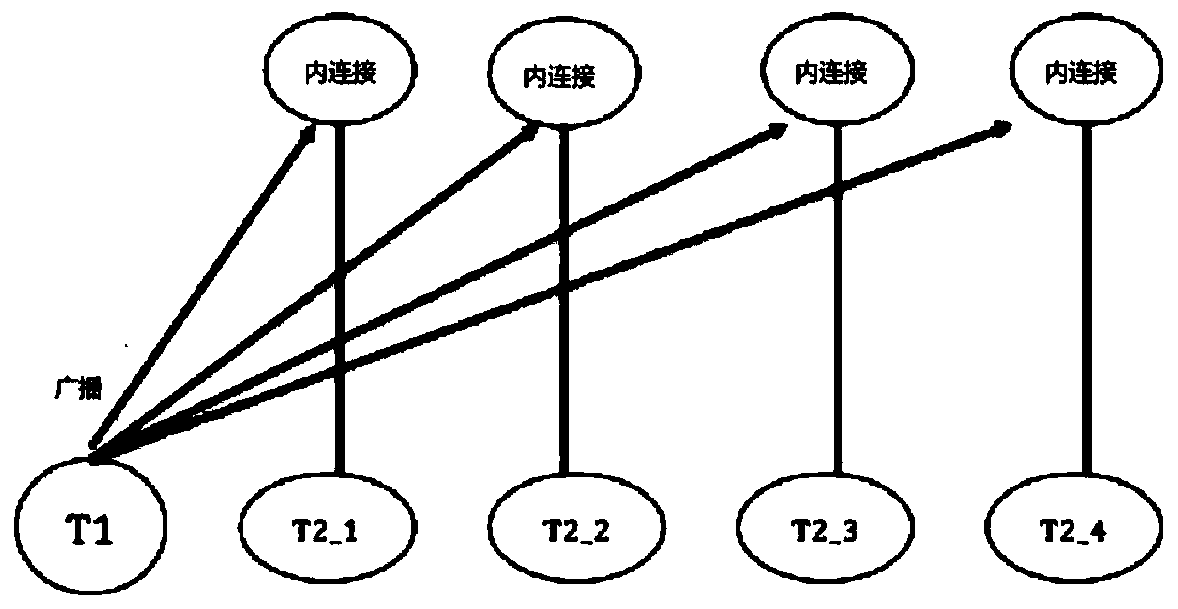
[0031] In the following, some terms used in this application are first introduced, and then referred to figure 1 and figure 2 Introduce some implementation methods of distributed outer joins, and then refer to image 3 Introduce the execution mode of the distributed outer join according to the embodiment of the present invention, finally refer to Figure 4 A method for outer-joining a first table of a database to a second table according to an embodiment of the present invention is introdu...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More