Multi-core clustering method for rapidly processing missing heterogeneous data
A technology of heterogeneous data and multi-source heterogeneous data, applied in multi-core clustering, multi-core clustering field dealing with missing heterogeneous data, can solve problems such as effective information discount and consistent data distribution
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image



Examples
Embodiment Construction
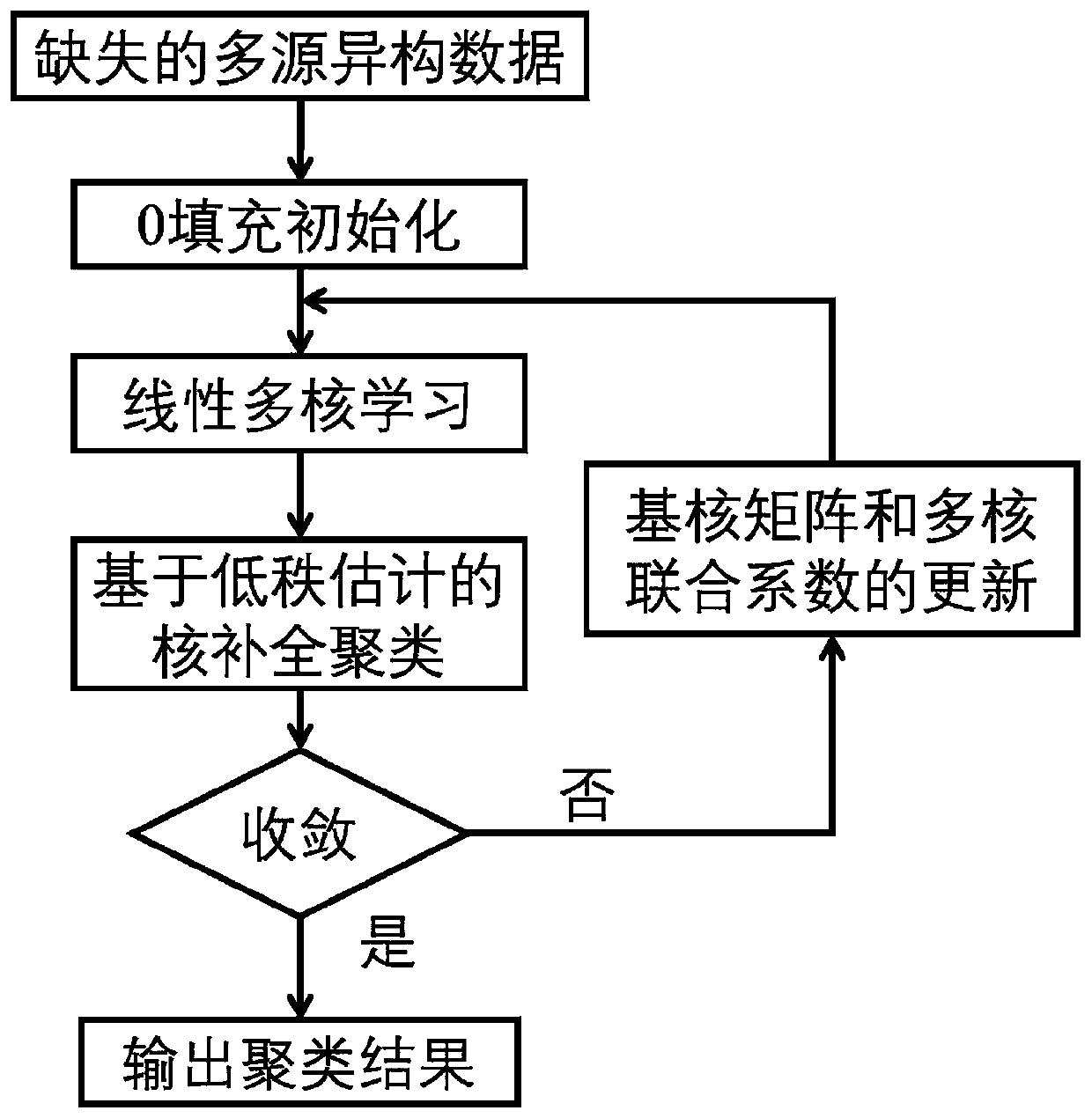
[0037] The specific embodiment of the present invention is described in detail below in conjunction with accompanying drawing:
[0038] Such as figure 1 shown. The input of the present invention is multi-source heterogeneous data with partial missing values, and the flow of the multi-core clustering method for quickly processing missing heterogeneous data mainly includes four steps: the first step is to perform 0 on the missing multi-source heterogeneous data Fill initialization; the second step is to use multiple basic kernel functions to perform multi-core learning on the initialized multi-source heterogeneous data to generate a multi-kernel matrix; the third step is to perform multi-kernel clustering on the generated multi-kernel matrix to generate pseudo-labels; then, Use low-rank estimation to update the missing values of each base kernel matrix that makes up the multi-kernel matrix; the fourth step is to learn the multi-kernel joint coefficients based on the clusterin...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More