

A highly scalable distributed indexing method for big data of new urban rail trains
An urban rail train and big data technology, applied in database indexing, structured data retrieval, digital data information retrieval, etc., can solve the problem that the key-value model database does not support auxiliary indexing, etc., to improve data retrieval efficiency and high scalability , the effect of low latency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0040] The technical solution of the present invention will be further described in conjunction with specific implementation and examples.
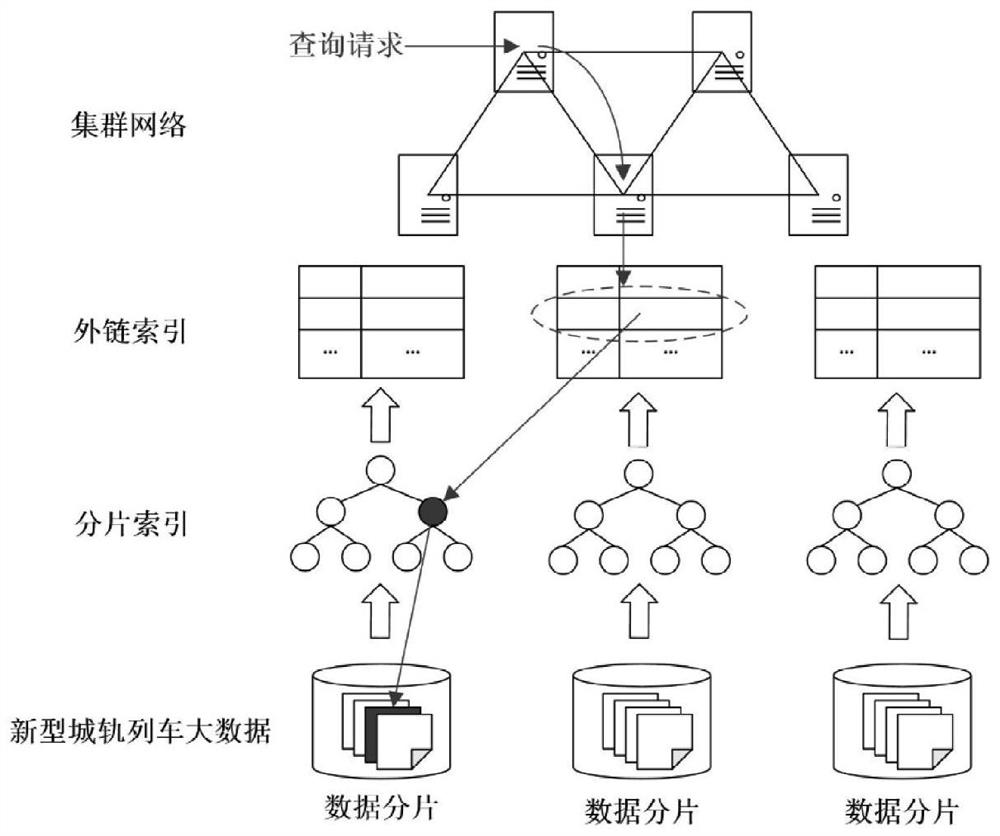
[0041] like figure 1 , specific embodiments of the present invention and its implementation process are as follows:
[0042]Step 1: Use server clusters to store and build a database for the big data of new urban rail trains, connect the nodes in the server clusters to form a server cluster with a graph topology, and then divide the entire value space of the secondary key into several communities Each small interval is used as a secondary key index range, and each server is allocated a secondary key index range according to the interconnection relationship of the server cluster nodes.
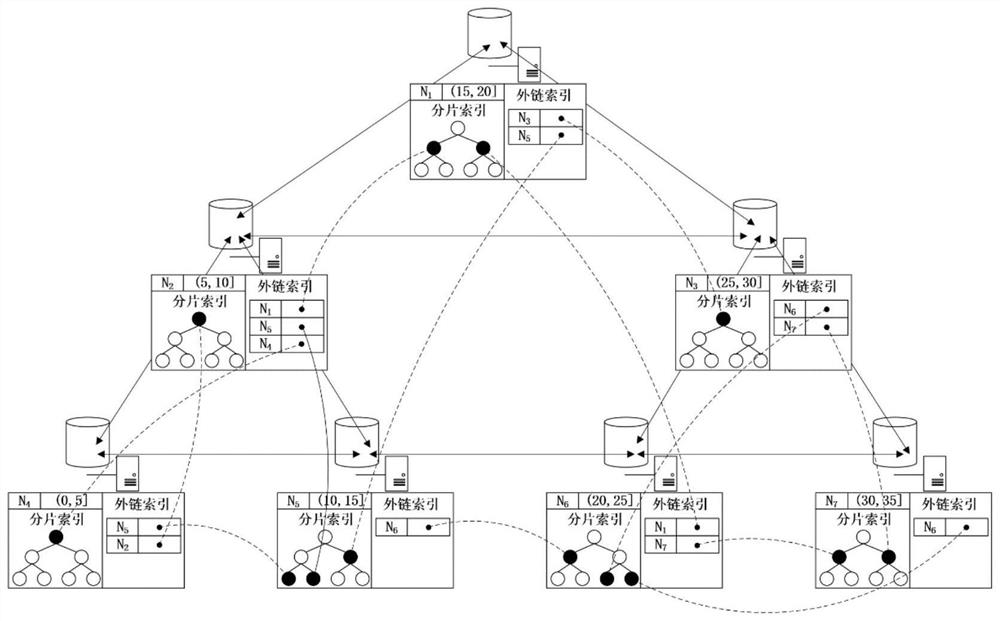
[0043] Such as figure 2 In the example shown, there are 7 servers in the cluster. First, build a binary tree containing 7 nodes, and correspond the servers to the nodes of the binary tree one by one. And divide the entire index interval (0,35] of the se...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More