

Video description method based on high-order low-rank multi-modal attention mechanism
A video description, multi-modal technology, applied in the field of computer vision, can solve the problems of ignoring multi-modal feature correlation information, the impact of video description accuracy, etc., to achieve good application value, improve efficiency, and improve accuracy.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

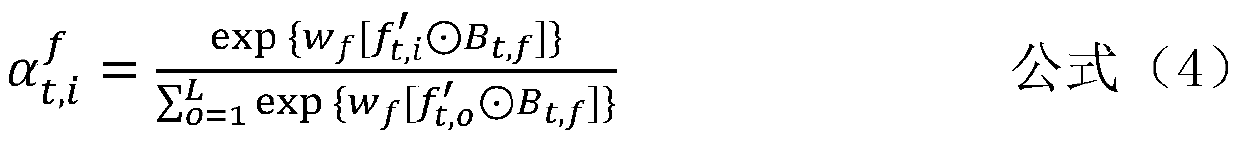
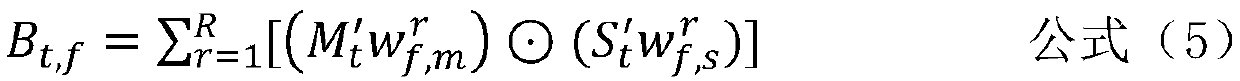
Examples
Embodiment Construction
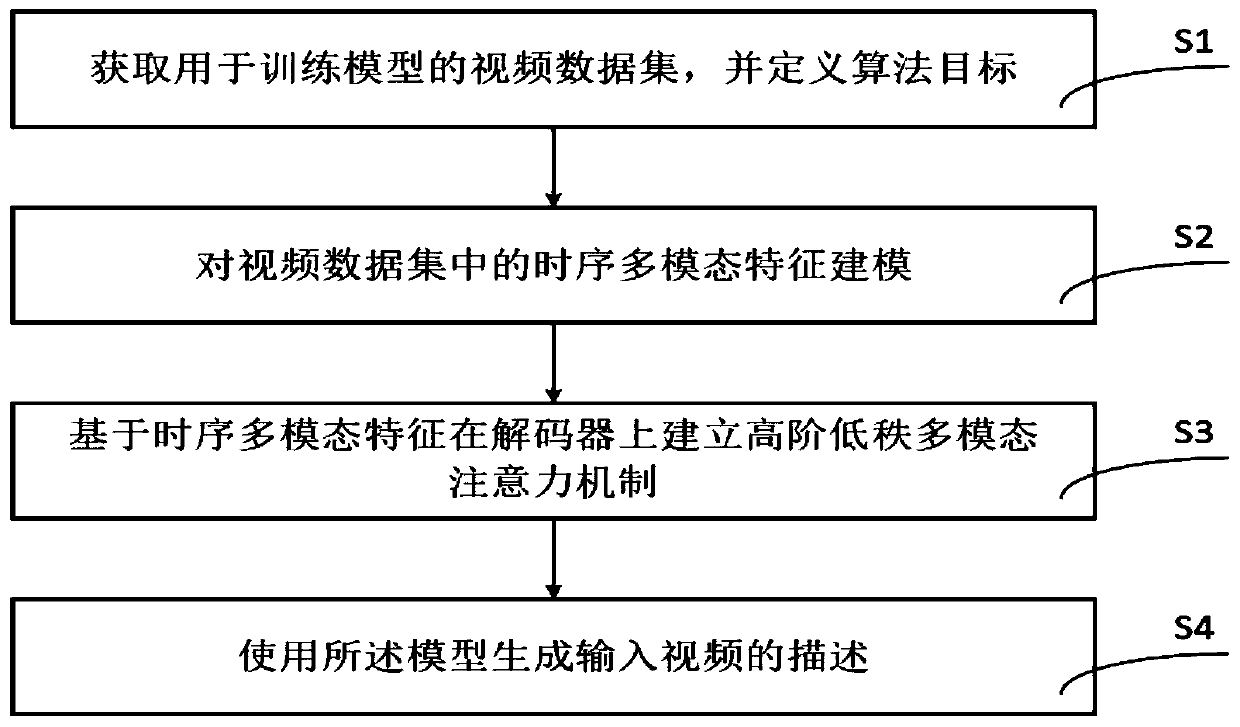
[0047]In order to make the object, technical solution and advantages of the present invention clearer, the present invention will be further described in detail below in conjunction with the accompanying drawings and embodiments. It should be understood that the specific embodiments described here are only used to explain the present invention, not to limit the present invention.
[0048] On the contrary, the invention covers any alternatives, modifications, equivalent methods and schemes within the spirit and scope of the invention as defined by the claims. Further, in order to make the public have a better understanding of the present invention, some specific details are described in detail in the detailed description of the present invention below. The present invention can be fully understood by those skilled in the art without the description of these detailed parts.
[0049] refer to figure 1 , in a preferred embodiment of the present invention, the video description g...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More