

Text similarity measurement method based on semantic document expression
A similarity measurement and text technology, applied in the field of text similarity measurement based on semantic document expression, can solve the problems of not considering text semantics, grammatical meaning, large errors, ignoring the relationship between words and word positions, etc., to achieve outstanding substantive characteristics, The effect of simple structure and wide application prospect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
[0063] like figure 1 As shown, the present invention provides a text similarity measurement method based on semantic document expression, comprising the following steps:
[0064] S1. Obtain the first text and the second text to be compared, perform word segmentation preprocessing on the sentences of each text, and remove punctuation marks;
[0065] S2. After the first text and the second text are preprocessed, each word is obtained and mapped to generate a word vector, and the word vector is matched with the convolutional neural network model CNN and the bidirectional long-short-term memory cycle network model BiLSTM;
[0066] S3. Process each text through the convolutional neural network model CNN and the bidirectional long-short-term memory cycle network model BiLSTM, and extract the CNN sentence semantic feature vector and the BiLSTM sentence semantic feature vector of each text;
[0067] S4. For each sentence semantic feature of each text, use the attention mechanism mode...
Embodiment 2
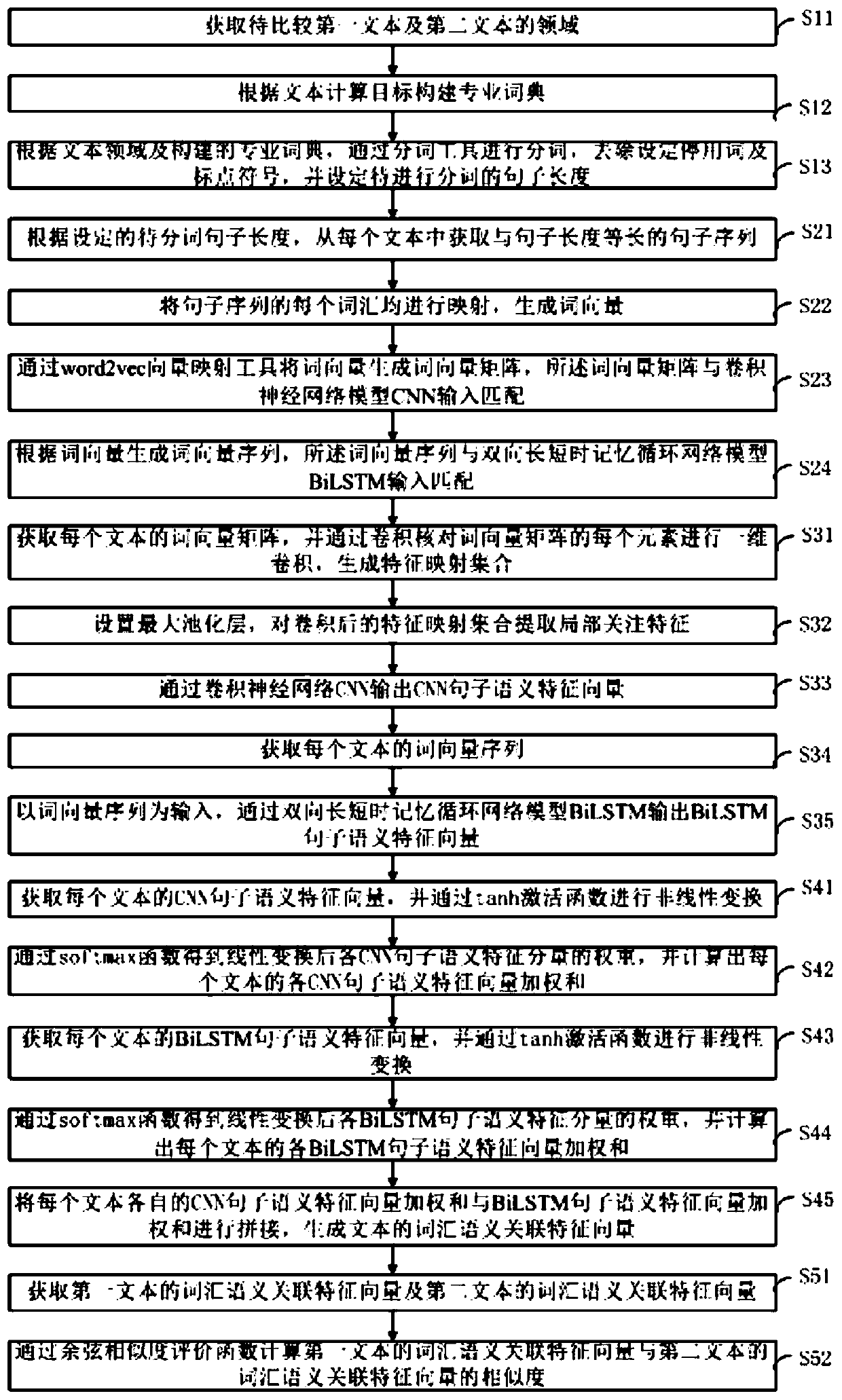
[0070] like figure 2 As shown, the present invention provides a text similarity measurement method based on semantic document expression, comprising the following steps:
[0071] S1. Obtain the first text and the second text to be compared, perform word segmentation preprocessing on the sentences of each text, and remove punctuation marks; the specific steps are as follows:
[0072] S11. Obtaining fields of the first text and the second text to be compared;
[0073] S12. Construct a professional dictionary according to the text calculation target;
[0074] S13. According to the text field and the professional dictionary constructed, word segmentation is carried out by the word segmentation tool, stop words and punctuation marks are removed, and the length of the sentence to be segmented is set; the word segmentation tool adopts a stuttering word segmentation tool;
[0075] S2. After the first text and the second text are preprocessed, each word is obtained and mapped, and a...
Embodiment 3
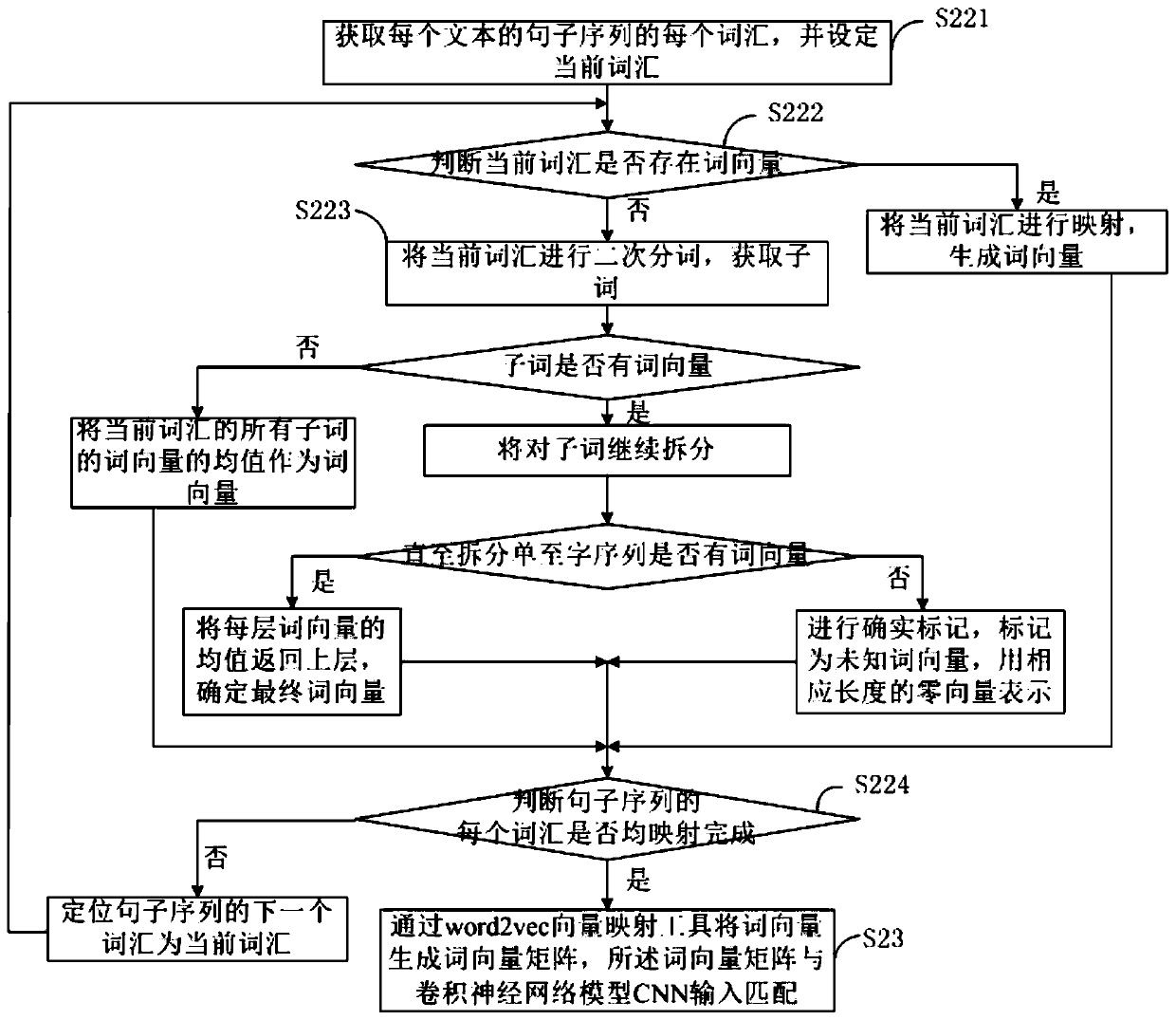
[0096] like image 3 As shown, in the above-mentioned embodiment 2, the specific steps of step S22 are as follows:
[0097] S221. Obtain each vocabulary of the sentence sequence of each text, and set the current vocabulary;
[0098] S222. Determine whether there is a word vector in the current vocabulary;
[0099] If so, map the current vocabulary to generate a word vector, and enter step S224;
[0100] If not, enter step S223;
[0101] S223. Segment the current vocabulary twice to obtain subwords, and use the mean value of the word vectors of all subwords in the current vocabulary as the word vector;
[0102] If the subword still has no word vector, the subword will continue to be split, and the mean value of each layer of word vector will be returned to the upper layer;
[0103] If there is still no word vector after splitting into a single-word sequence, it will be marked as an unknown word vector and represented by a zero vector of corresponding length;
[0104] S224....
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More