

Video annotation method based on multiple modes
A multi-modal, video technology, applied in the fields of computer vision and video annotation, can solve the problems of complex video files, reduce the quality of aggregated features, and not consider the importance of frames to videos, and achieve accurate aggregation results and improve accuracy. Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

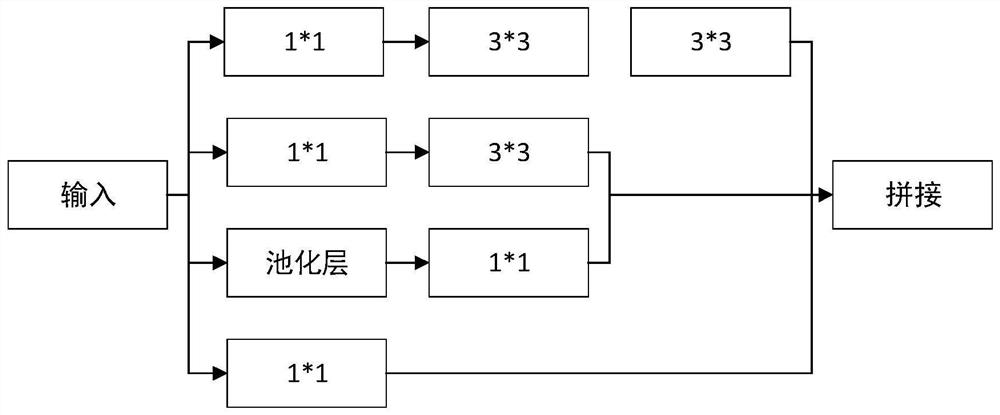
Examples
Embodiment Construction
[0058] In order to make the objectives, technical solutions and advantages of the present invention clearer, the following further describes the present invention in detail with reference to the accompanying drawings and embodiments. It should be understood that the specific embodiments described here are only used to explain the present invention, but not to limit the present invention. In addition, the technical features involved in the various embodiments of the present invention described below can be combined with each other as long as they do not conflict with each other.
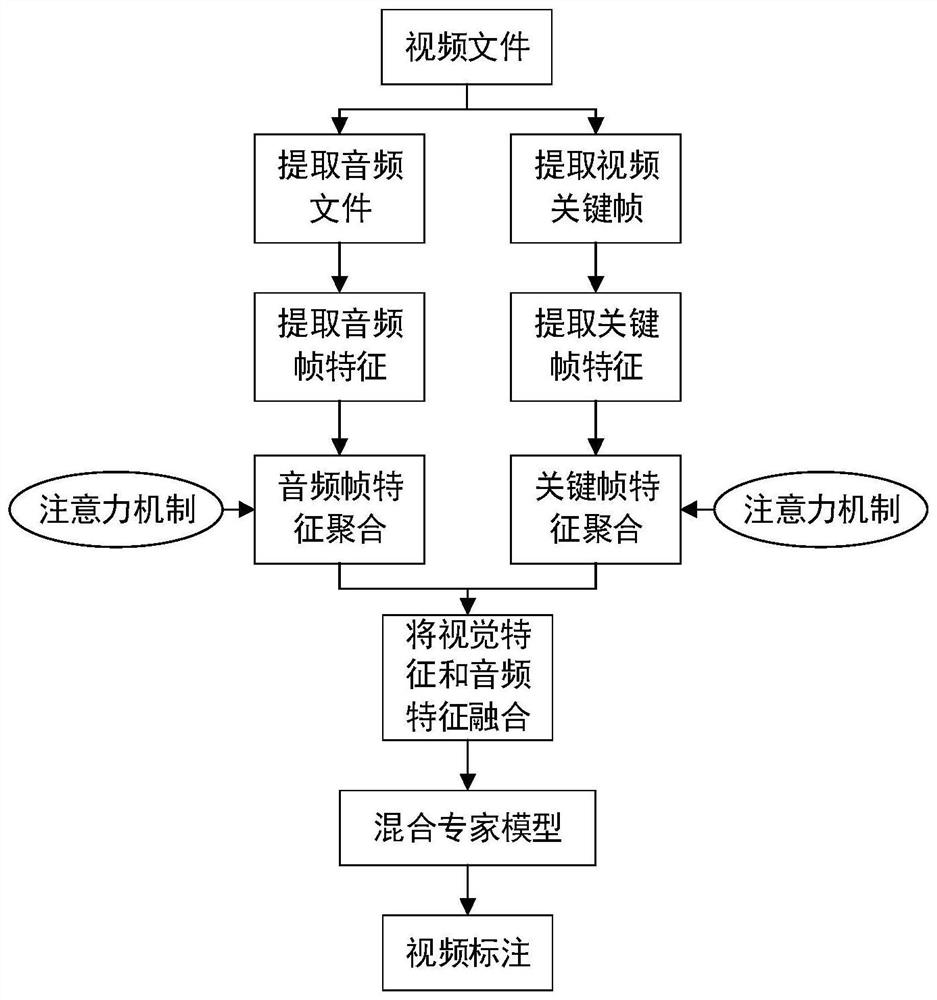
[0059] Such as figure 1 As shown, the embodiment of the present invention provides a multi-modality-based video tagging method, including:
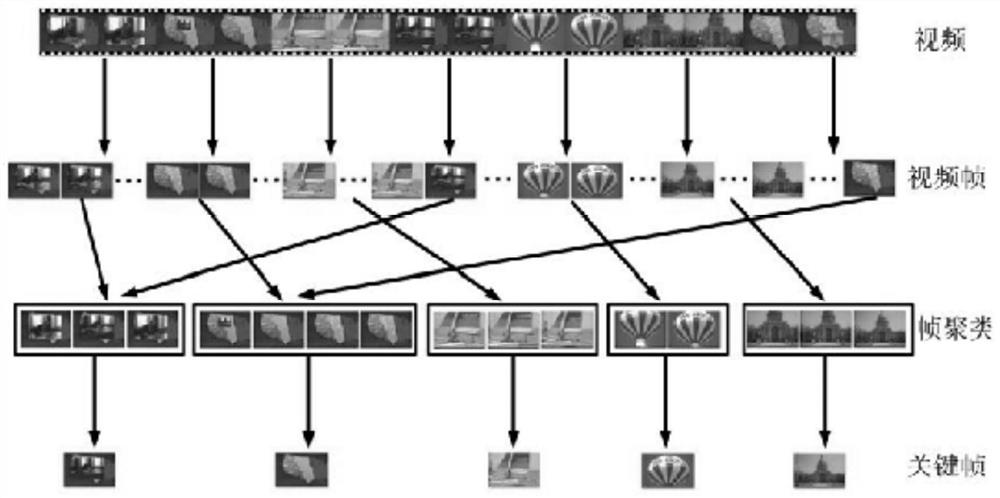
[0060] S1. Extract the key frames of the video through the clustering method;
[0061] The key frame extraction process is as figure 2 As shown, specifically including:
[0062] S1.1. Taking the first frame of the video as the first category, calculate the color histog...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More