Text-based entity recognition method and related device
A technology of entity recognition and text, which is applied in the field of entity recognition, can solve problems such as long calculation time, unreliable feature selection, and low recognition accuracy, and achieve the effect of small actual calculation amount, improved accuracy rate, and enhanced representation ability
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
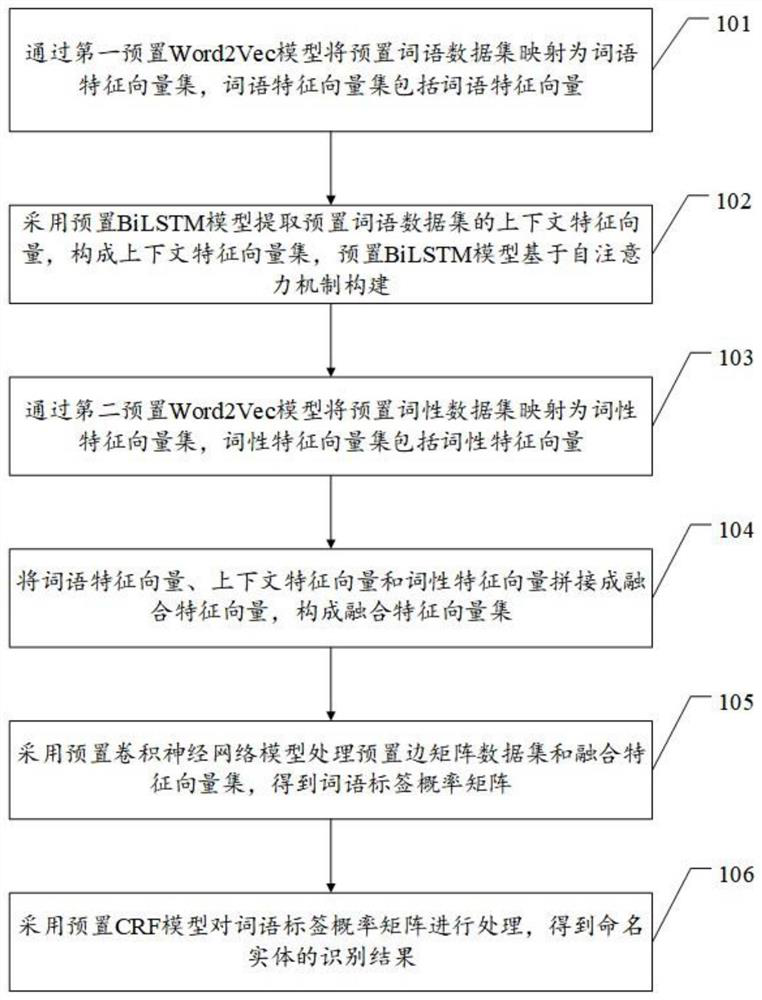
[0050] For ease of understanding, see figure 1 , Embodiment 1 of a text-based entity recognition method provided by the present application, including:
[0051] Step 101: Map the preset word data set into a word feature vector set through the first preset Word2Vec model, and the word feature vector set includes the word feature vector.
[0052]The first preset Word2Vec model can be regarded as a word vector model, and it is an unsupervised model. According to the input word data set, the word vector is learned, or the word data set is mapped to a word vector set. The specific processing process is actually Words are randomly initialized as vectors of several dimensions, and text information is converted into digital information; Word vectors with the same semantic meaning are similar, and word vectors with different semantic meanings are different through word learning in documents. The output dimension of the Word2Vec model can be set according to the actual situation.
[0...
Embodiment 2
[0064] For ease of understanding, see figure 2 , the present application provides a second embodiment of a text-based entity recognition method, including:
[0065] Step 201, using a crawler to obtain a large amount of text data to form an initial text data set.
[0066] Step 202: Filter the initial text data set by using a preset Dirichlet topic model to obtain a filtered text data set.
[0067] Use crawlers to obtain a large amount of text data, and the initial text data set is denoted as T 1 , process the initial text dataset T by presetting the Dirichlet topic model 1 , each text acquires 5 topics, and judges whether the 5 topics contain keywords for future descriptions, which is convenient for predicting and identifying future named entities, and if there are, it will be filtered as a reserved text data set T 2 , otherwise the text data is discarded.
[0068] Step 203 , using a preset word segmentation tool to sequentially perform trigger word type screening and synt...
PUM
 Login to view more
Login to view more Abstract
Description
Claims
Application Information
 Login to view more
Login to view more - R&D Engineer
- R&D Manager
- IP Professional
- Industry Leading Data Capabilities
- Powerful AI technology
- Patent DNA Extraction
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic.
© 2024 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap