

Target detection and distribution method and device based on multi-agent reinforcement learning
A reinforcement learning, multi-agent technology, applied in the field of simulation, can solve the problem of slow convergence of combat behavior model optimization
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

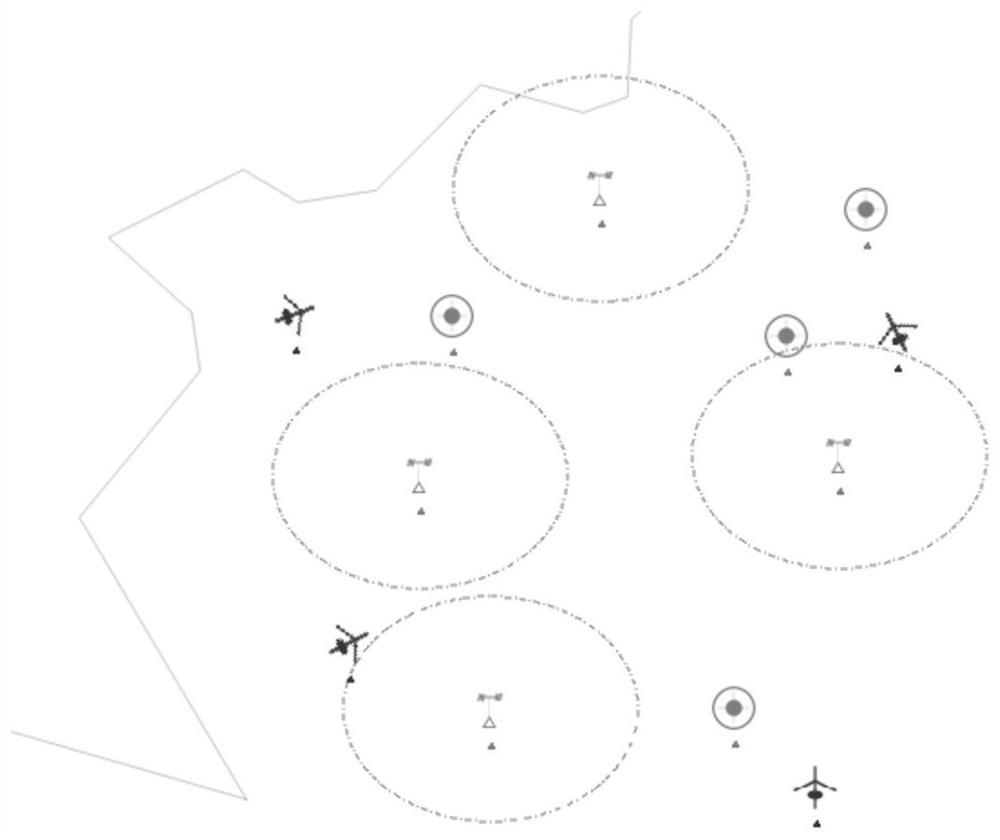
Examples
Embodiment Construction
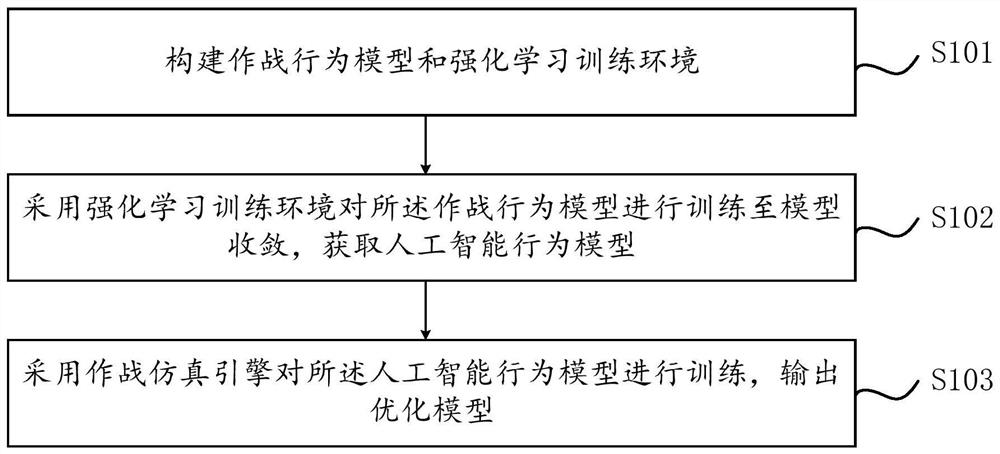
[0051]In order to make the objectives, technical solutions and advantages of the present invention clearer, the technical solutions of the present invention will be described in detail below. Obviously, the described embodiments are only some, but not all, embodiments of the present invention. Based on the embodiments of the present invention, all other implementations obtained by those of ordinary skill in the art without creative work fall within the protection scope of the present invention.
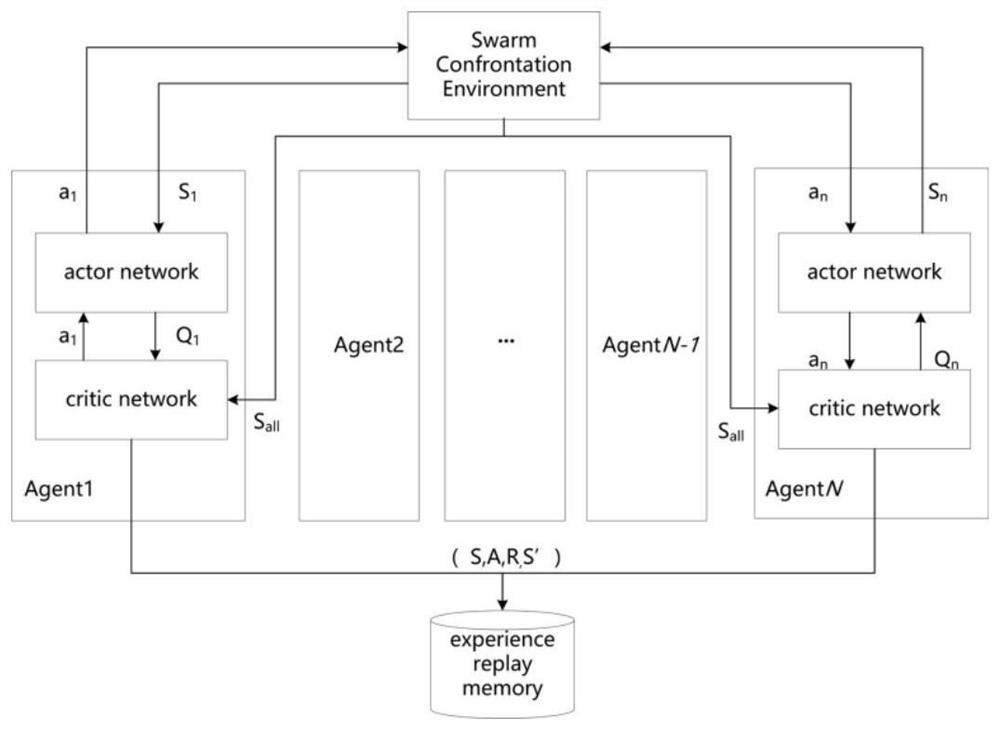
[0052] Inspired by the MADDPG (Multi-Agent Deep Deterministic Policy Gradient) multi-agent algorithm, a series of improvements have been made to the policy gradient algorithm, making it suitable for complex multi-agent scenarios that traditional algorithms cannot handle. The MADDPG algorithm has the following three characteristics:
[0053] 1. The optimal strategy obtained by learning can only use local information to give the optimal action in application.
[0054] 2. There is no n...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More