

High-dimensional multi-label data flow classification method based on online sequence kernel extreme learning machine
A kernel extreme learning machine, multi-label technology, applied in the field of multi-label data stream classification problem, can solve the problems of difficult to detect feature drift and concept drift, difficult to obtain data, and low accuracy of classification algorithms
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
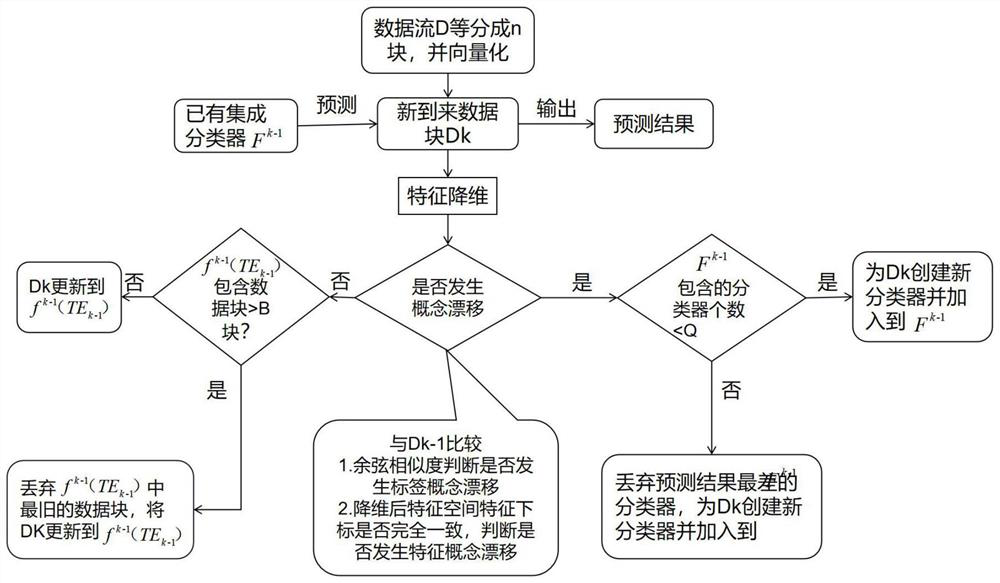
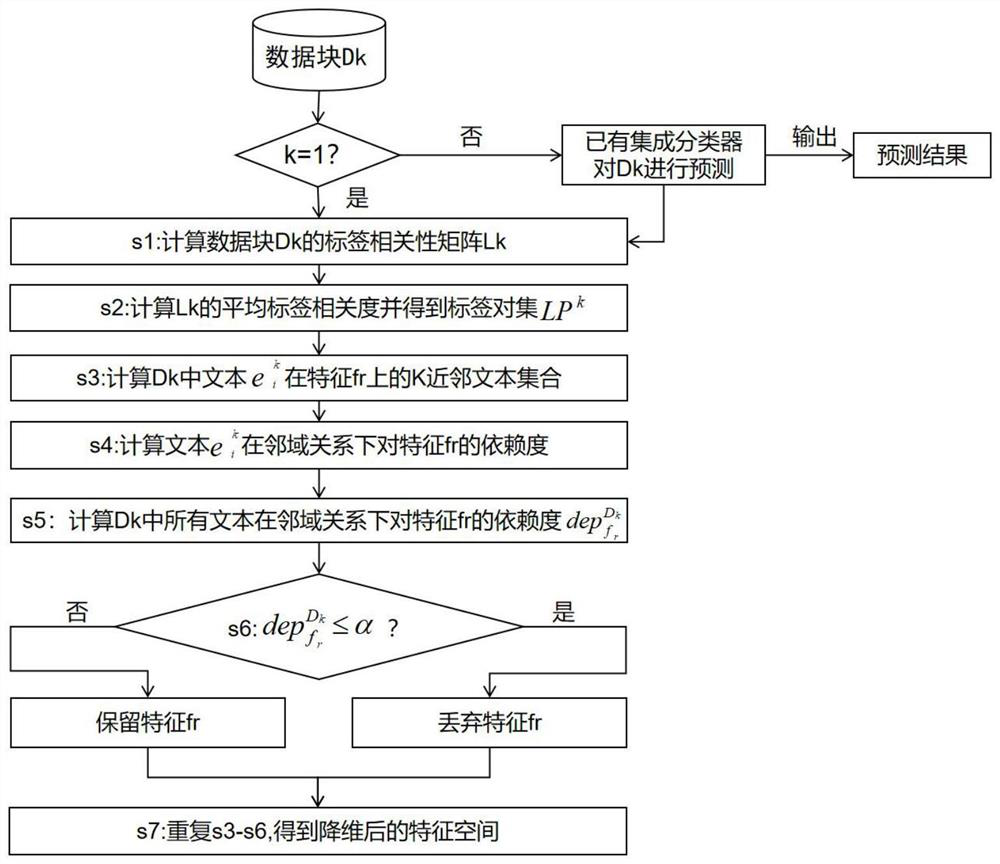
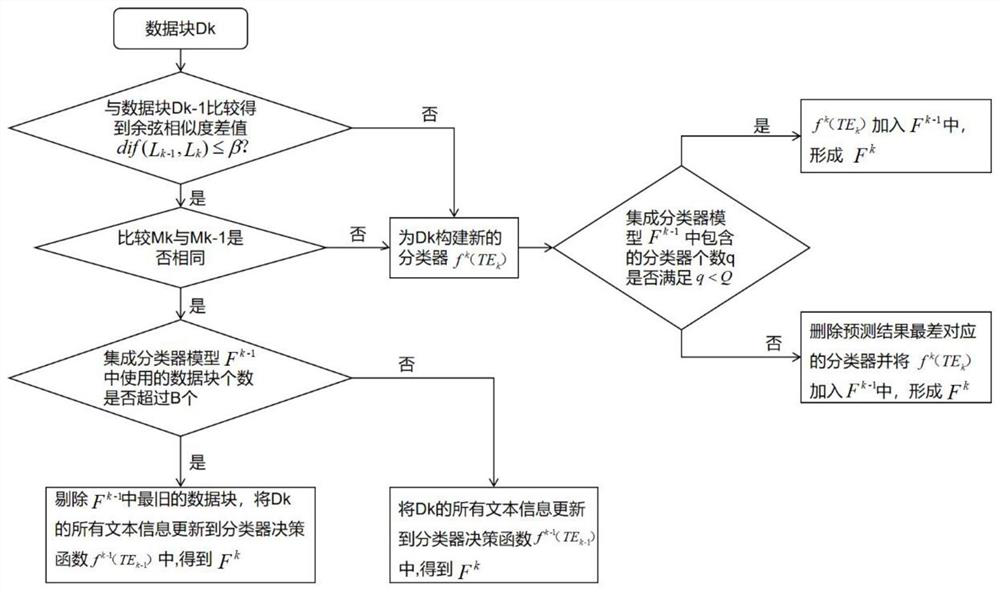
[0056] In this example, if figure 1 As shown, a high-dimensional multi-label data stream classification method based on online sequence kernel extreme learning machine can be used to classify network news in browsers, sort out appropriate tags for complicated news, facilitate user retrieval, and provide readers It is widely used to provide prediction work, recommend news for browsers, etc. Specifically, it is carried out according to the following steps:
[0057] Step 1: Construct the BoW model based on the external corpus, and use the sliding window mechanism to divide the multi-label text data stream into data blocks and then vectorize:
[0058] Step 1.1: Given a set of multi-label text data stream D={d 1 , d 2 ,...,d m ,...,d |D|}, m=1, 2, ..., |D|, |D| indicates the total number of texts in the multi-label text data stream D, d m Represents the mth text in the multi-label text data stream D, and has: d m ={W m ,V m}, W m with V m respectively represent the mth te...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More