

Crawler system based on HTTP proxy and implementation method thereof
A crawler system and implementation method technology, applied in the information field, can solve problems such as being unsuitable for large-scale data acquisition, unable to cope with webpage font anti-crawling measures, and unsuitable for large-scale data crawling, etc., so as to simplify browser operations and improve Concealment, the effect of preventing detection by websites
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0044] The present invention will be described in detail below in conjunction with specific embodiments. The following examples will help those skilled in the art to further understand the present invention, but do not limit the present invention in any form. It should be noted that those skilled in the art can make several changes and improvements without departing from the concept of the present invention. These all belong to the protection scope of the present invention.
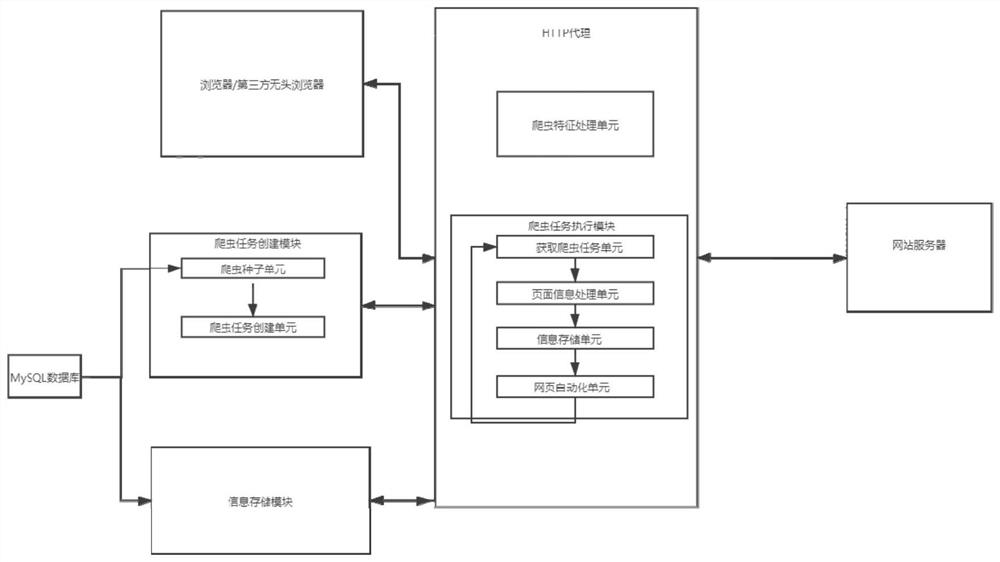
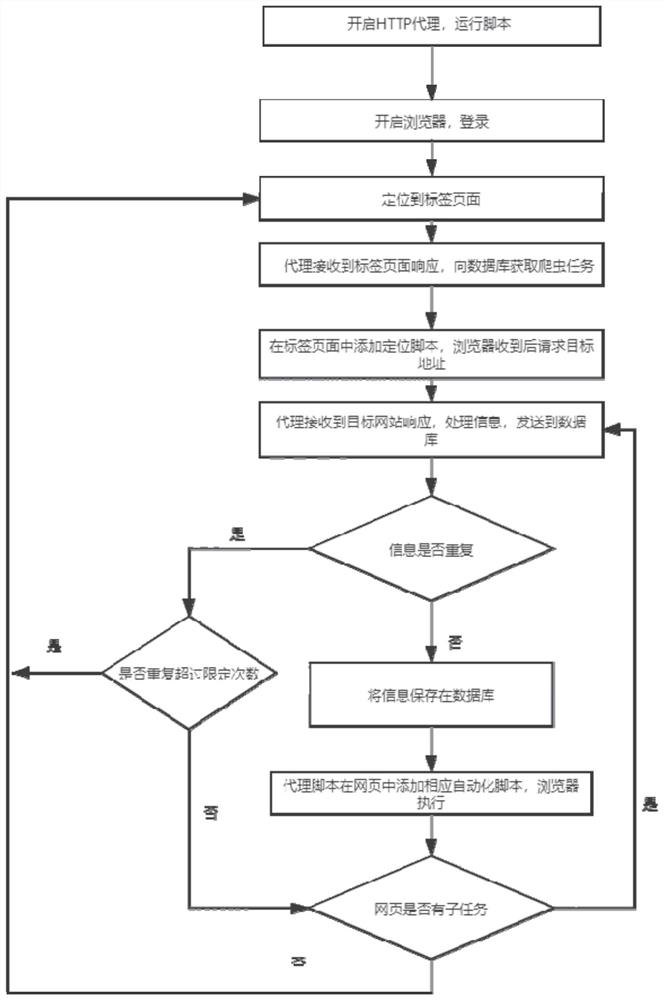
[0045] The object of the present invention is to provide an HTTP proxy-based crawler system and its implementation method, aiming at solving the problems of weak concealment and many manual operations in the existing crawler system.
[0046] In the present invention, the HTTP agent mainly refers to a common agent, and what this agent plays is the role of a middleman. For the client connected to it, it is the server; for the server to be connected, it is the client. end. It is responsible for transmitti...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More