

Document key information extraction method based on zero sample learning
A key information and sample learning technology, applied in the field of computer vision, can solve the problems of increased parameter capacity, large amount of data, insufficient resource time, etc., to achieve the effect of reducing resources and time, improving prediction speed, and strong generalization ability.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment
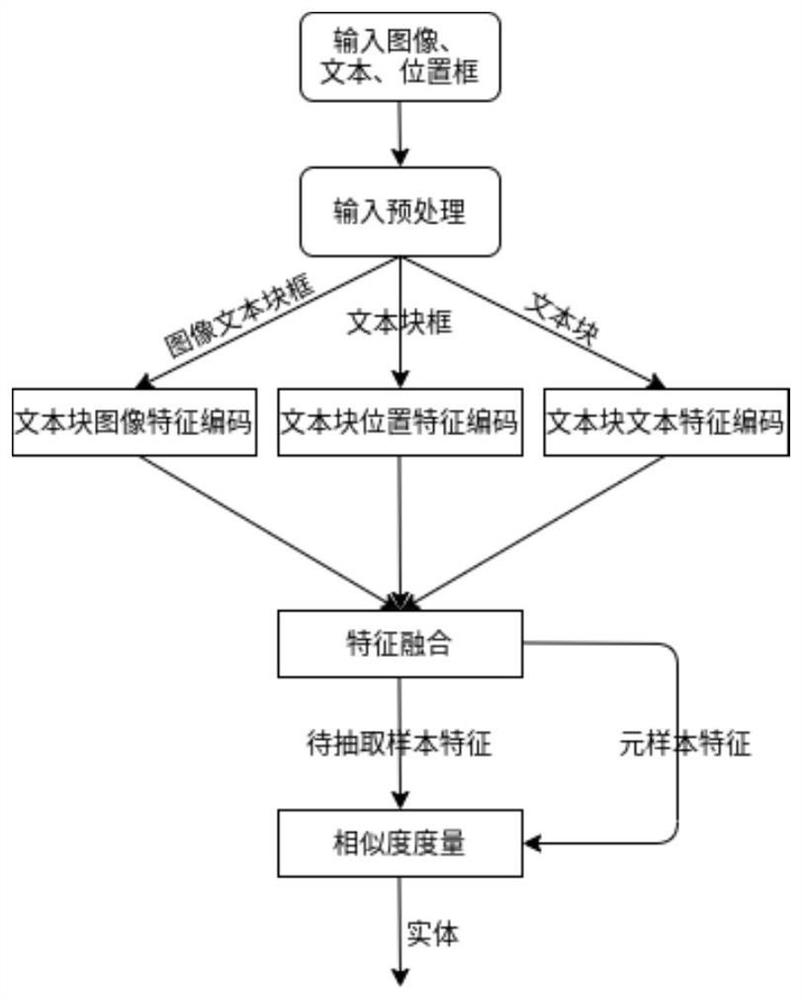
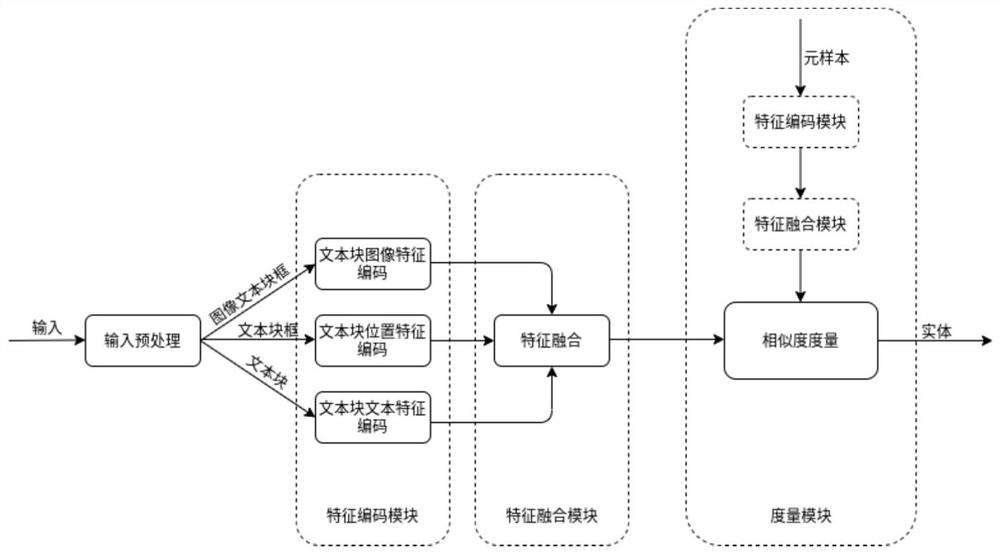
[0069] Before preprocessing, a sample is selected as a meta-sample, which is the benchmark for subsequent similarity measurement. Since we are dealing with samples of fixed templates, we can randomly select one of the labeled samples of the same type of template as the meta-sample of this type of template. Such as Figures 1 to 2 As shown, it specifically includes the following steps:
[0070] Step 1: Input Preprocessing
[0071] This step performs preprocessing operations on the input, which includes images, text block boxes, and text.
[0072] For the input image, the most important thing is to normalize the size of the aspect ratio and fill the boundary with 0, so that the size of the image can support the convolution and downsampling operations required by the neural network in the encoding module, and maximize the Both global and local feature information are preserved. During training, the image preprocessing stage also needs to complete the necessary data enhancemen...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More