

Short video classification method based on multi-modal feature complete representation
A classification method and short video technology, applied in video data clustering/classification, video data retrieval, video data indexing, etc., to achieve the effect of improving accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
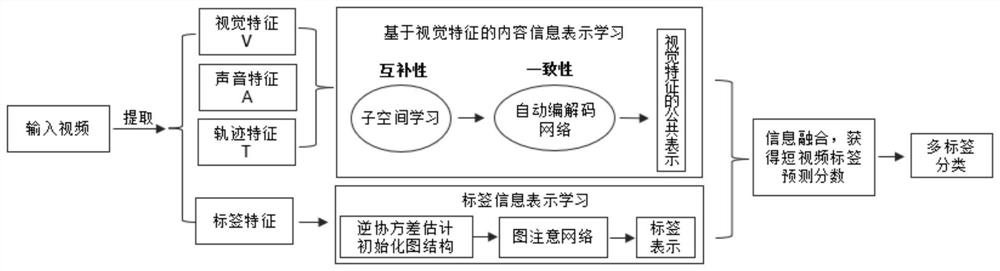
[0027] The embodiment of the present invention provides a short video classification method based on the complete representation of multimodal features, which makes full use of the content information and label information of the short video, see figure 1 , the method includes the following steps:
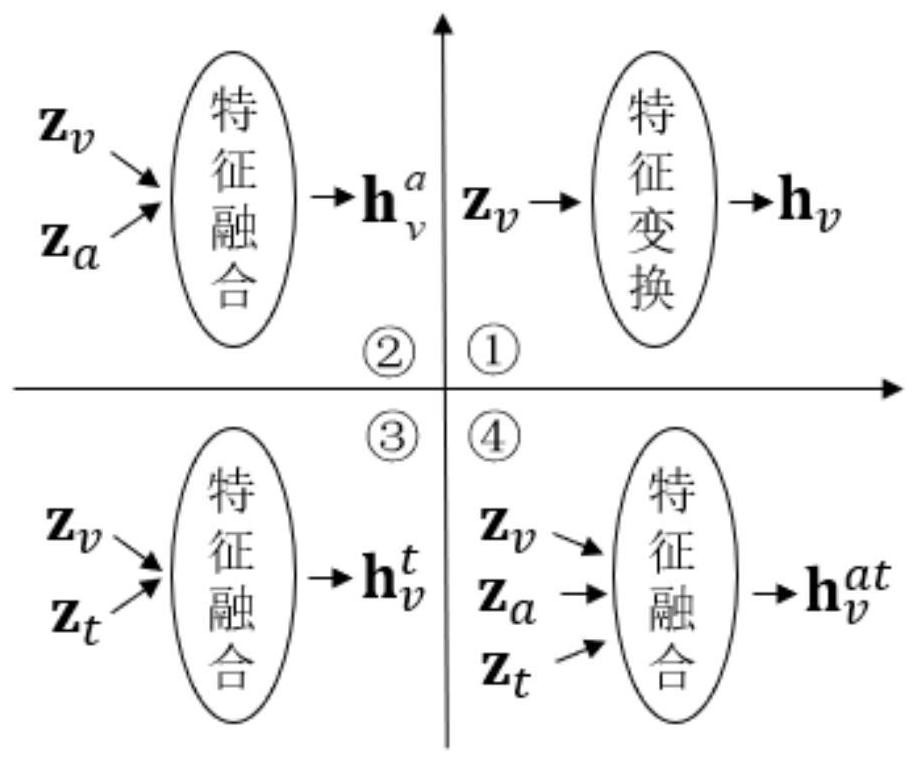
[0028] 101: For content information, according to experience, the semantic feature representation of visual modality is very important in short video multi-label classification tasks. Therefore, a representation learning based on visual modality features is proposed, mainly based on visual modality features, from The modality-missing perspective constructs four subspaces, learns information complementarity between modalities, and obtains latent representations of two types of visual modality features. Considering the consistency of visual modality feature information, in order to obtain a more compact representation of visual modality features, the latent representations of two typ...
Embodiment 2
[0039] The scheme in embodiment 1 is further introduced below in conjunction with calculation formula and examples, see the following description for details:
[0040] 201: The model inputs a complete short video, and extracts three modal features of vision, audio and track respectively;
[0041] For the visual modality, extract key frames, and use the classic image feature extraction network ResNet (residual network) for all video key frames, and then do the average (AvePooling) operation to obtain the visual modality feature X v The overall characteristics of z v :
[0042]
[0043] Among them, ResNet(·): residual network, AvePooling(·): average operation, X v : the original visual features of the short video, βv: the network parameters to be learned, visual modality z v The dimension is d v .
[0044] For the audio mode, draw the sound spectrogram, and use "CNN+LSTM (convolutional neural network + long short-term memory network)" to extract the sound features of t...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More