

End-to-end speech recognition model based on multi-level identification and modeling method
A speech recognition model and modeling method technology, applied in speech recognition, speech analysis, instruments, etc., can solve the problems of non-pronunciation, uneven distribution of samples, and inability to consider the synergistic pronunciation of speech, so as to achieve the effect of improving the accuracy rate
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
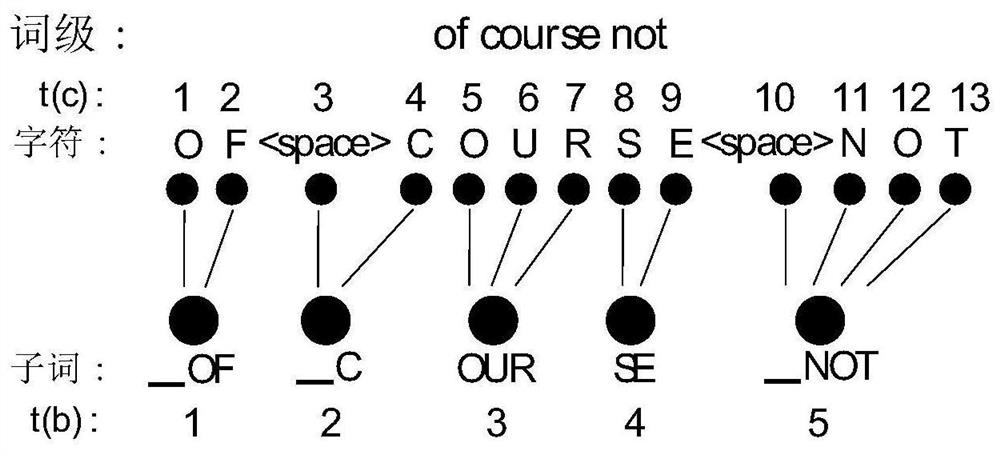
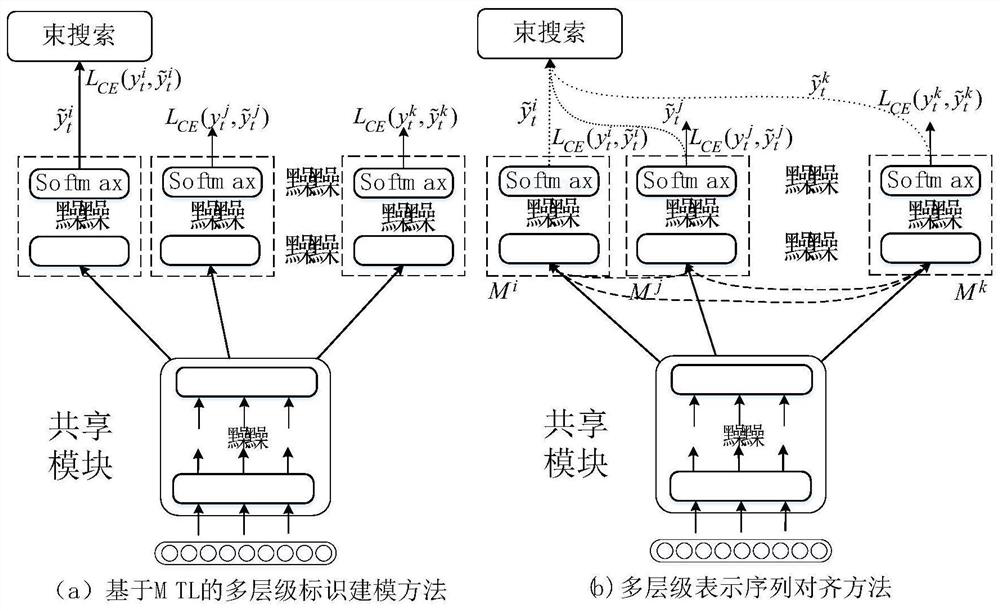
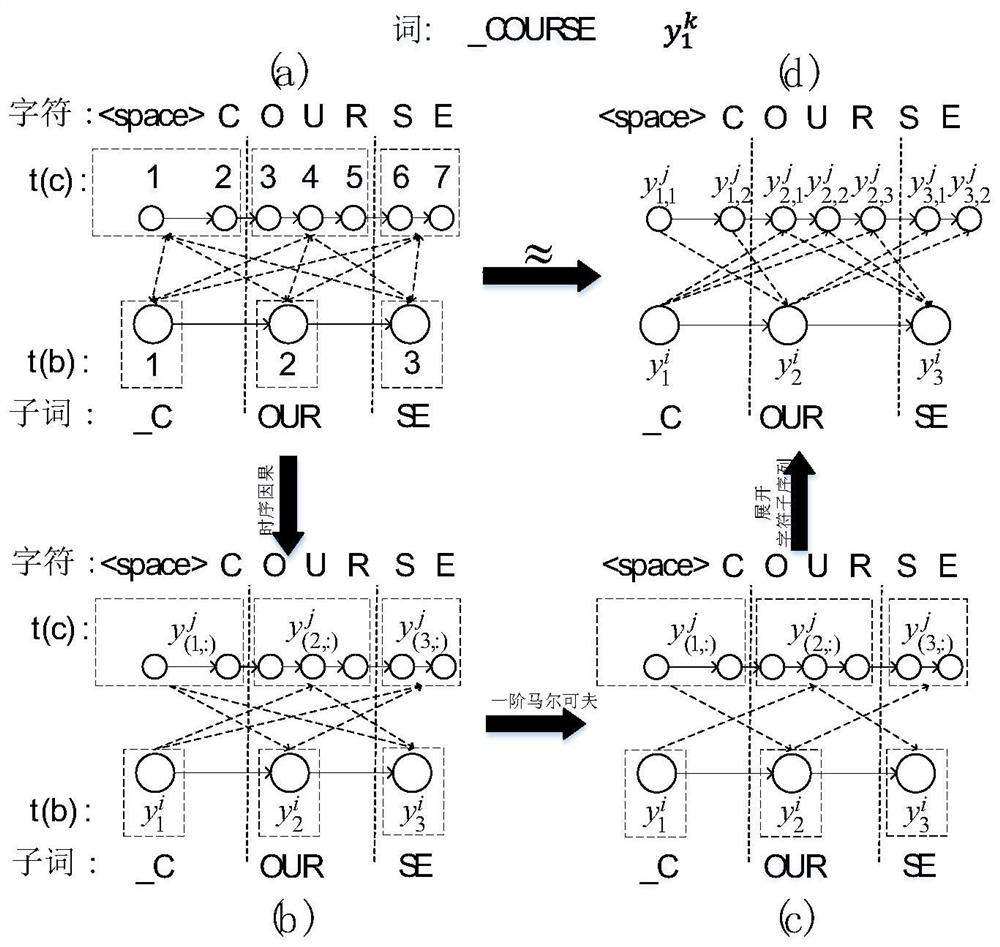
[0036]Picking one of the multi-level text sequences for end-to-end speech recognition modeling is not the only choice, let alone the optimal choice. The multiple text sequences selected in the end-to-end modeling of speech recognition are recorded as multiple-granularity target sequences. The present invention considers that selecting multiple text sequences together for end-to-end speech recognition modeling can achieve better results, and proposes a multi-granularity sequence alignment method (Multi-Granularity Sequence Alignment, MGSA).
[0037] The end-to-end ASR system as a whole can be divided into two parts: the model training stage (training stage) and the decoding inference stage (inference stage). The MGSA method proposed in this patent will respectively use multi-level identification information to optimize the ASR system in these two stages. First, in the model structure, the end-to-end ASR decoder module will sequentially generate multi-level text sequences, and ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More