

Visual semantic embedding method and system based on data enhancement
A semantic and data technology, applied in the field of visual semantic embedding method and system based on data enhancement, to achieve good generalization ability and improve the effect of convergence speed
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
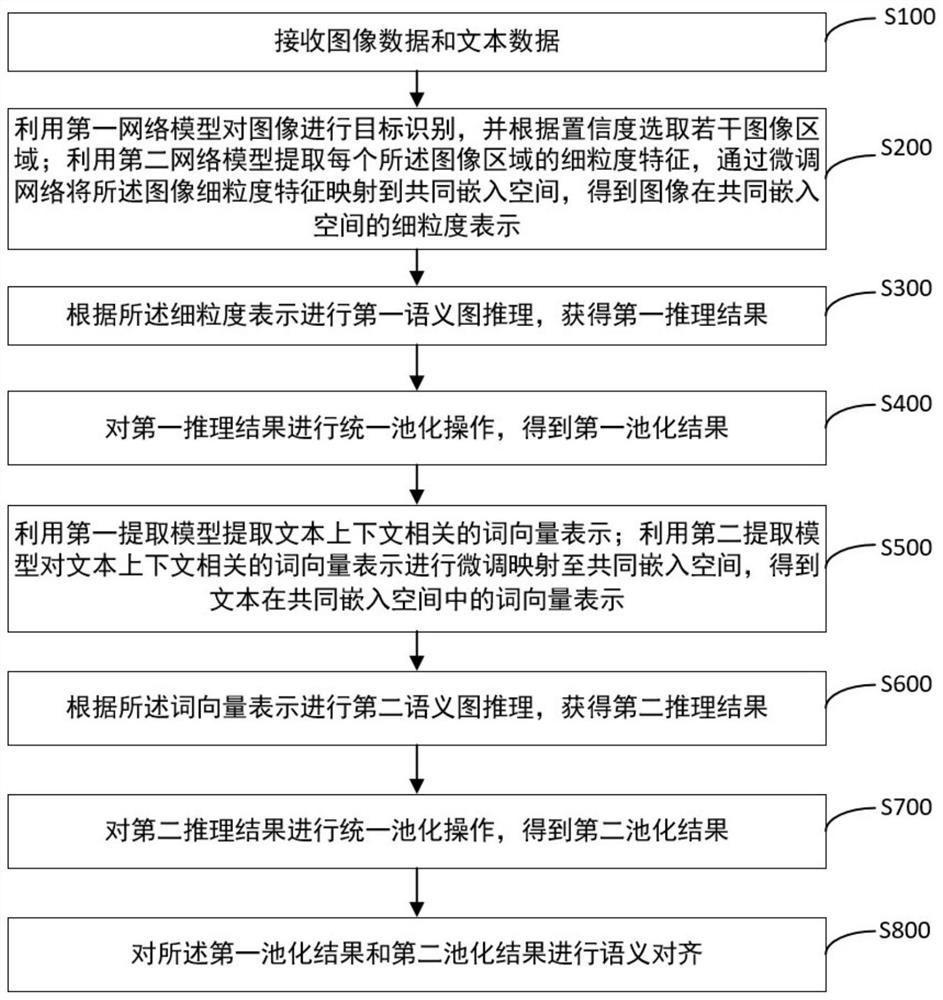
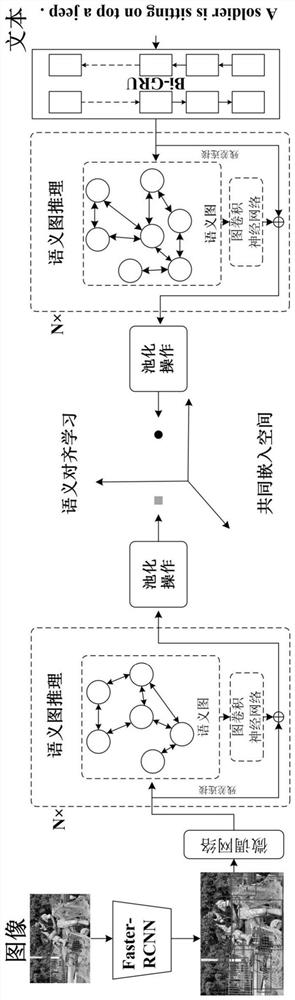
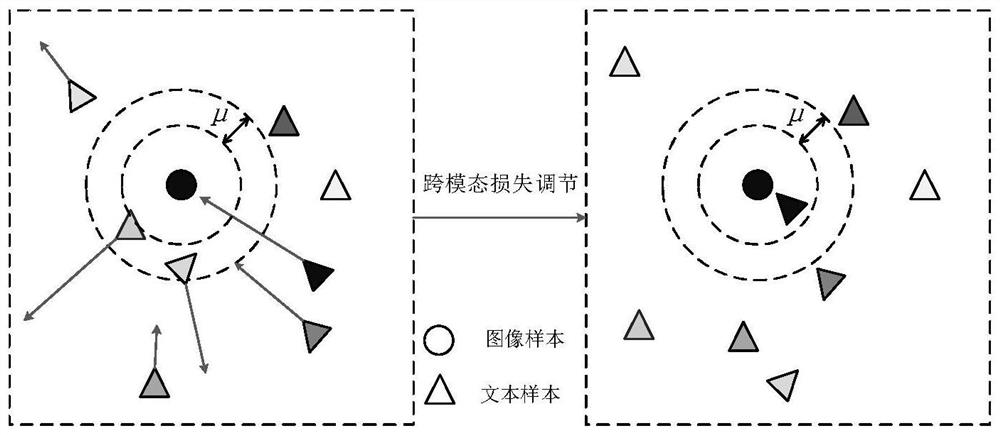
[0050] The present invention will be further described below in conjunction with embodiment and accompanying drawing. figure 1 A flow chart showing a visual semantic embedding method based on data enhancement in an embodiment of the present invention; figure 2 A structural diagram of the visual semantic embedding model composed of all models in the embodiment of the present invention is shown. combine figure 1 and figure 2 As shown, the method includes:
[0051] Step S100: Receive image data and text data.
[0052] Step S200: Use the first network model to perform target recognition on the image, and select several image regions according to the confidence; use the second network model to extract the fine-grained features of each of the image regions, and fine-tune the network to fine-grain the image features Mapped to the common embedding space, a fine-grained representation of the image in the common embedding space is obtained.
[0053] In one embodiment ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More