

Understanding-assisted dialogue system artificial evaluation method and device and storage medium
A dialogue system and artificial technology, applied in the fields of electrical digital data processing, natural language data processing, instruments, etc., can solve problems such as the lack of systematic consideration and understanding process, and the quality of evaluation results reliability evaluation data needs to be improved, so as to improve reliability. , the effect of enhancing understanding
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
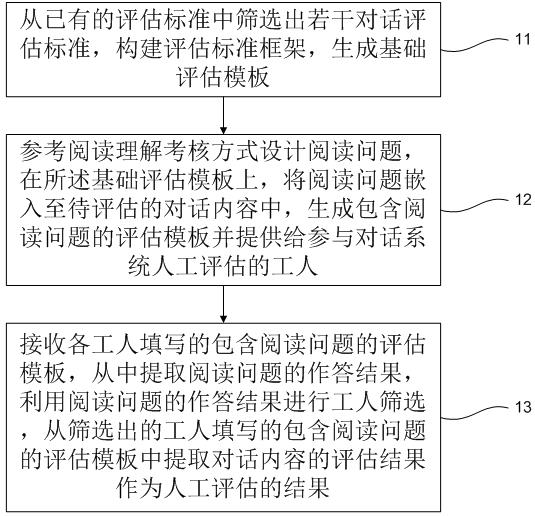
[0032] like figure 1 As shown in the figure, a manual evaluation method for a dialogue system to assist understanding mainly includes the following steps:
[0033] Step 11: Screen out several dialog evaluation criteria from the existing evaluation criteria, construct an evaluation criteria framework, and generate a basic evaluation template.
[0034] Step 12: Design reading questions with reference to the reading comprehension assessment method, embed the reading questions into the dialogue content to be assessed on the basic assessment template, generate an assessment template containing the reading questions, and provide them to workers participating in the manual assessment of the dialogue system.
[0035] In the embodiment of the present invention, a missing sentence selection strategy and a dialogue content sorting strategy are designed. These two strategies correspond to different reading problems. A corresponding strategy can be selected according to the dialogue conten...
Embodiment 2
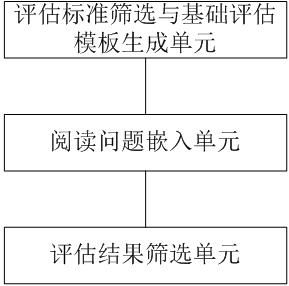
[0082] An embodiment of the present invention provides a device for artificial evaluation of a dialogue system to assist understanding, which is mainly implemented through the solution provided in the first embodiment, such as Figure 5 As shown, it mainly includes:
[0083] Evaluation criteria screening and basic evaluation template generation unit, used to filter out several dialogue evaluation criteria from the existing evaluation criteria, construct an evaluation criteria framework, and generate a basic evaluation template;
[0084] The reading question embedding unit is used to design reading questions with reference to the reading comprehension assessment method. On the basic assessment template, the reading questions are embedded into the dialogue content to be assessed, and an assessment template containing the reading questions is generated and provided to each participating dialogue system. Manually assessed workers;
[0085] The evaluation result screening unit is ...
Embodiment 3
[0089] The present invention also provides a processing device, such as Image 6 As shown, it mainly includes: one or more processors; a memory for storing one or more programs; wherein, when the one or more programs are executed by the one or more processors, the One or more processors implement the method provided in the first embodiment.
[0090] Further, the processing device further includes at least one input device and at least one output device; in the processing device, the processor, the memory, the input device, and the output device are connected through a bus.
[0091] In this embodiment of the present invention, the specific types of the memory, the input device, and the output device are not limited; for example:
[0092] The input device can be a touch screen, an image capture device, a physical button or a mouse, etc.;
[0093] The output device can be a display terminal;
[0094] The memory may be random access memory (Random Access Memory, RAM), or may be...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More