Key point thermodynamic diagram guided self-supervised monocular visual odometer method
A monocular vision and key point technology, applied in the field of computer vision, can solve the problems of cumulative error, no focus of deep neural network, and no consideration of the consistency of video image sequence pose, etc., to achieve the effect of improving accuracy and reducing cumulative error
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image



Examples
Embodiment Construction
[0059] In order to make the objectives, technical solutions and advantages of the present invention clearer, the embodiments of the present invention will be further described in detail below with reference to the accompanying drawings.
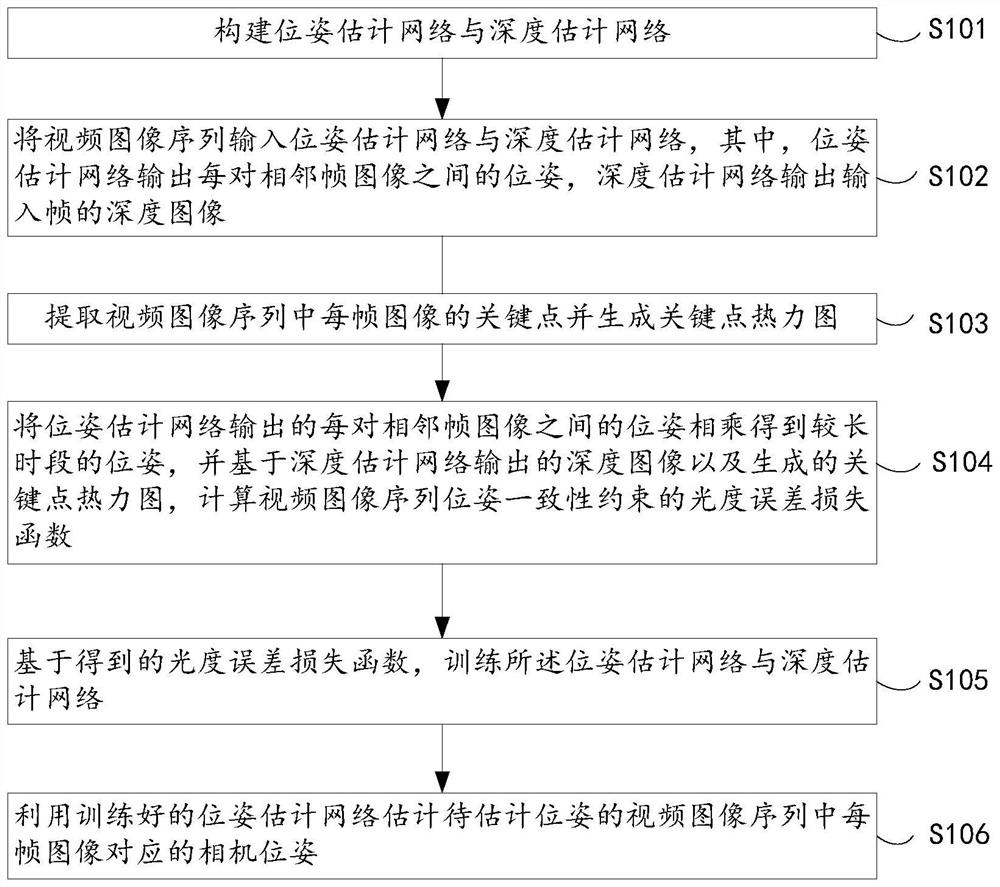
[0060] like figure 1 and figure 2 As shown, an embodiment of the present invention provides a self-supervised monocular visual odometry method guided by a key point heat map, including:
[0061] S101, construct a pose estimation network (PoseNet) and a depth estimation network (DepthNet);
[0062] In this embodiment, in order to control the memory occupation, the input images (referring to RGB images) of the pose estimation network and the depth estimation network are scaled to a size of 416×128.
[0063] In this embodiment, the pose estimation network includes: an encoder and a decoder, wherein ResNet50 can be selected as the encoder, and the encoder outputs 2048 channels of encoded input pose estimation network decoder. The decoder inpu...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More