

Video prediction method based on time sequence correction convolution
A prediction method and timing correction technology, applied in the field of computer vision, can solve problems such as insufficient description of spatial features, large computing overhead, and obstacles to the description of model space features, so as to enhance the ability to capture long-term dependencies and enhance the ability of relationships , Enhance the effect of depicting ability
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0043] The present invention will be further described below with reference to the accompanying drawings.
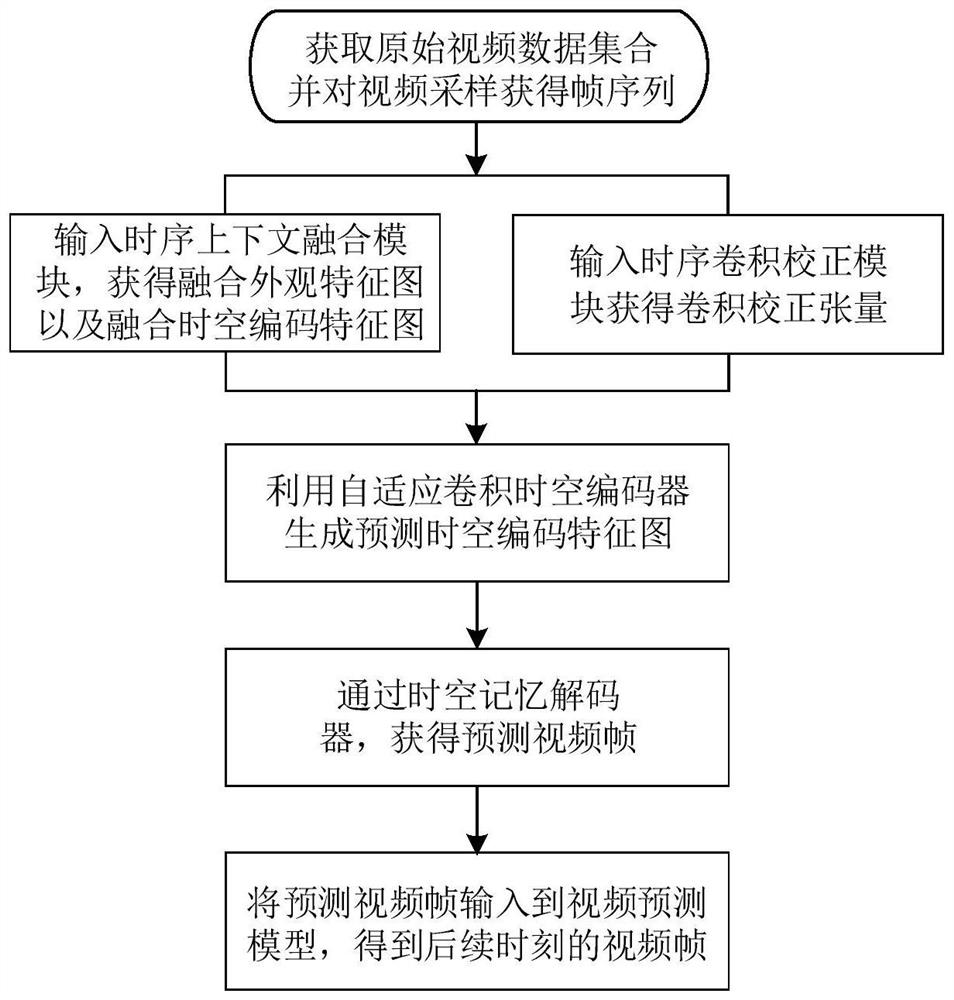
[0044] like figure 1 , a video prediction method based on time series correction convolution, first obtain the original video data set, and then perform the following operations in turn: first, uniformly sample the original video to obtain a video frame sequence; build a time series context fusion module to obtain fusion appearance features and fusion spatio-temporal coding features Then construct the time series convolution correction module and output the convolution correction tensor; then input the fusion appearance feature, fusion spatiotemporal coding feature map and convolution correction tensor into the adaptive convolutional spatiotemporal encoder to obtain the predicted spatiotemporal coding feature map; Finally, the predicted spatiotemporally encoded feature maps are decoded into predicted video frames using a spatiotemporal memory decoder; this method uses th...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More