

Data governance method based on datax
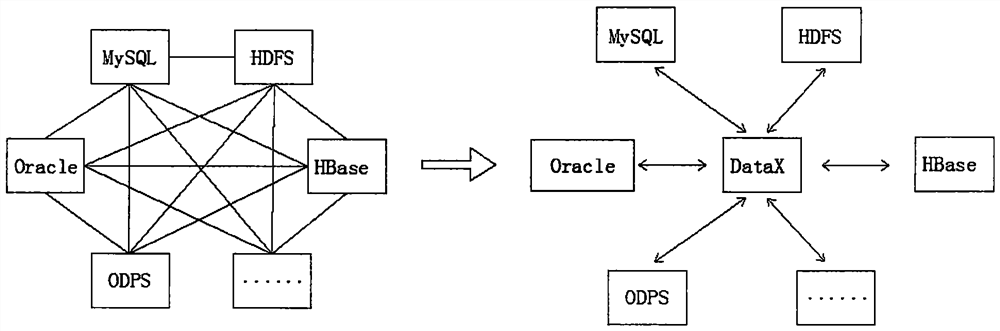
A data and data synchronization technology, applied in the field of data governance, can solve problems such as inability to process data and manage decision-making report presentation, do not support concurrent processing of massive tasks, and tools do not support real-time data processing, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment
[0041] see Figure 1-3 , a datax-based data governance method according to an embodiment of the present invention includes:
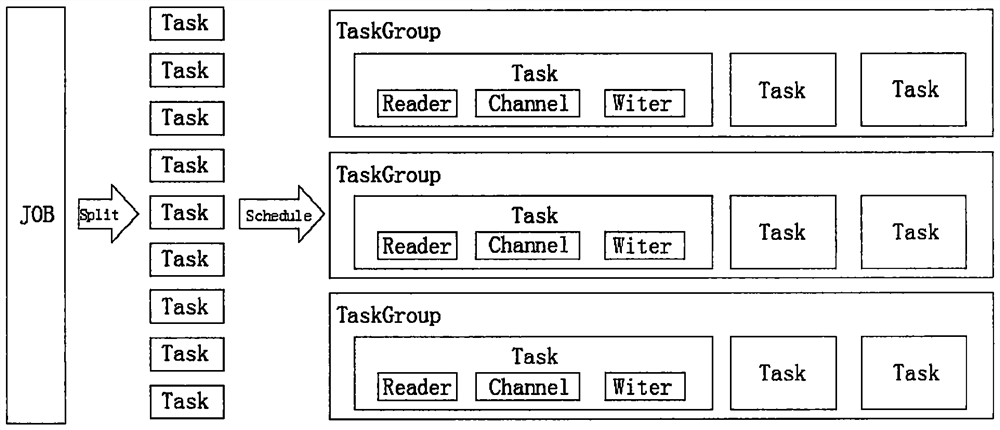
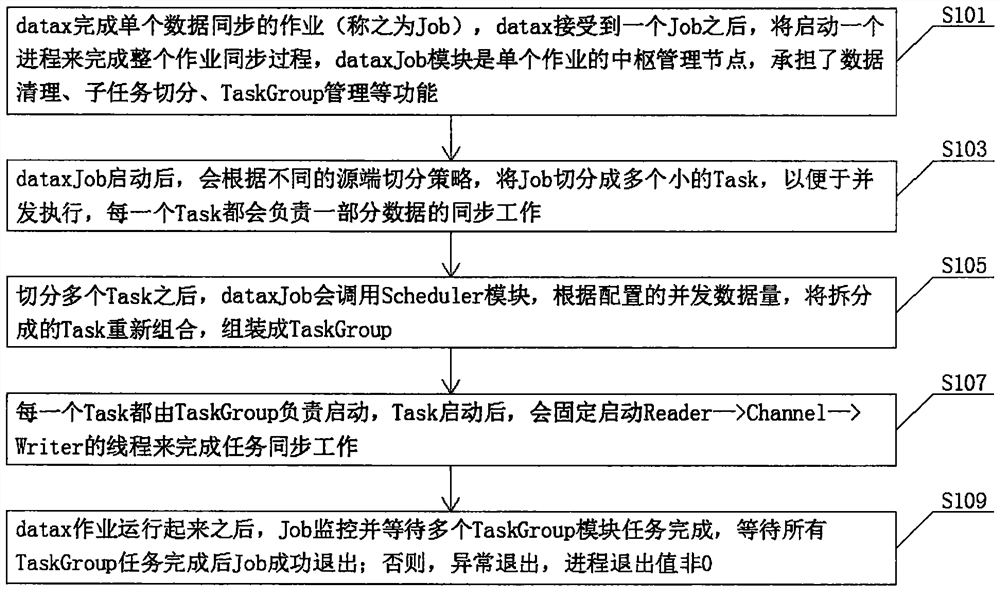
[0042] S101. The job that datax completes a single data synchronization is called a job. After datax receives a job, it will start a process to complete the entire job synchronization process. The dataxJob module is the central management node of a single job, which is responsible for data cleaning, subtask switching Functions such as division, TaskGroup management, etc.;
[0043] After S103 and dataxJob are started, the job will be divided into multiple small tasks according to different source-end segmentation strategies to facilitate concurrent execution, and each task will be responsible for the synchronization of a part of the data;
[0044] S105. After dividing multiple tasks, dataxJob will call the Scheduler module, and recombine the divided tasks according to the configured amount of concurrent data, and assemble them into a TaskGroup;
[0045...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More