

Extraction of facts from text
a text and facts technology, applied in the field of text extracting facts, can solve the problems of little if any consistency, the rule development of capitalization patterns common in english language text may fail on languages with different capitalization patterns, and the regular expressions do not recognize some categories of tokens
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Benefits of technology
Problems solved by technology
Method used
Image

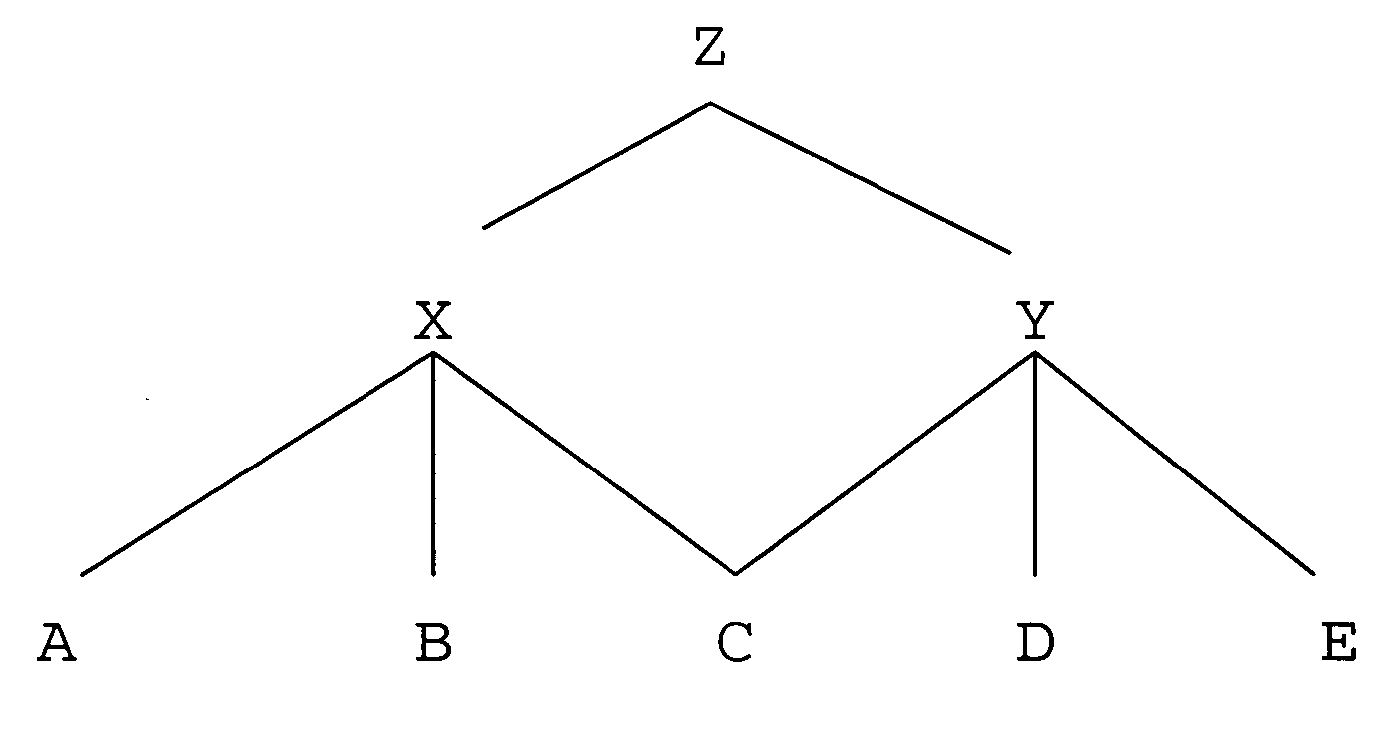
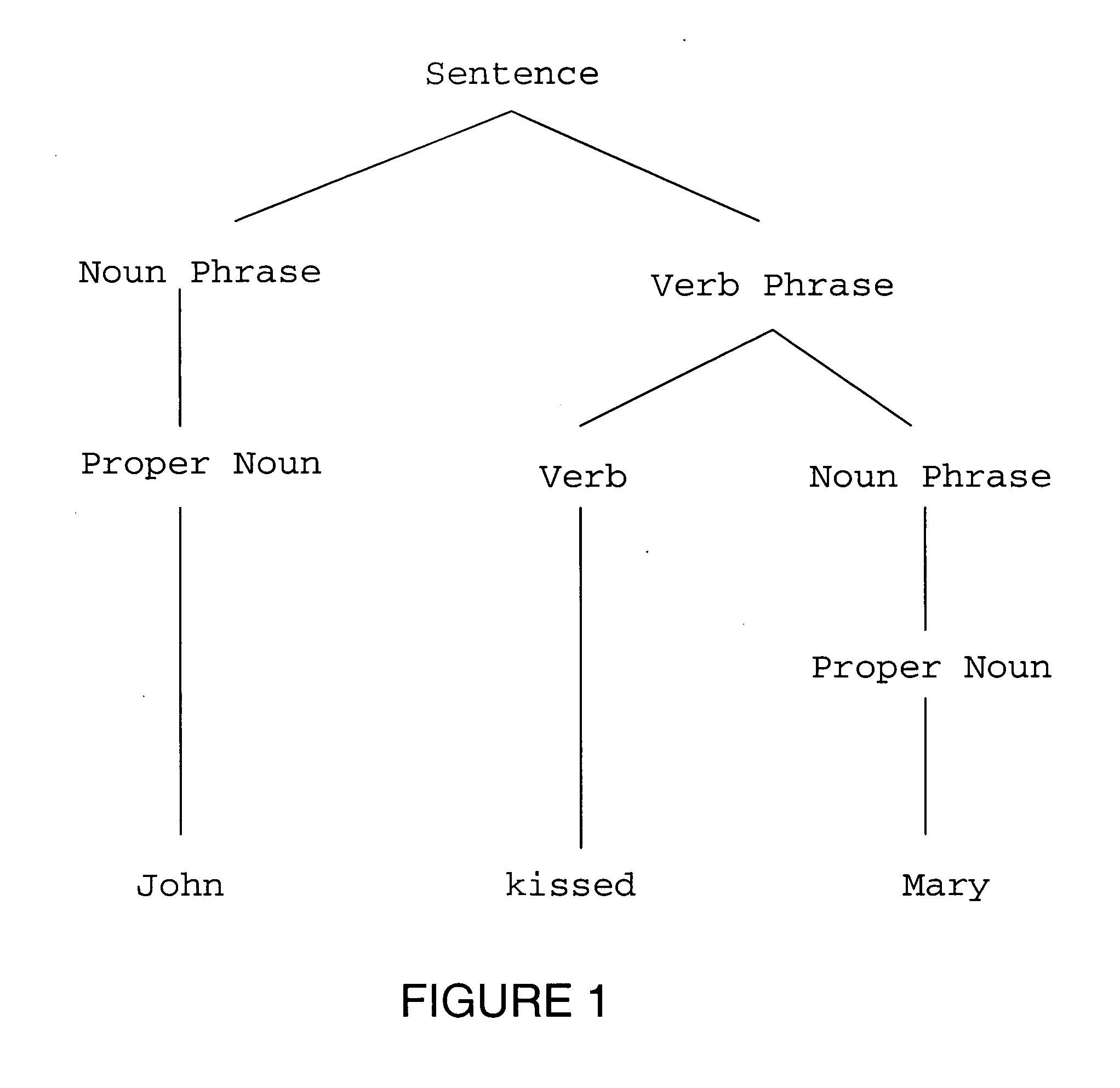
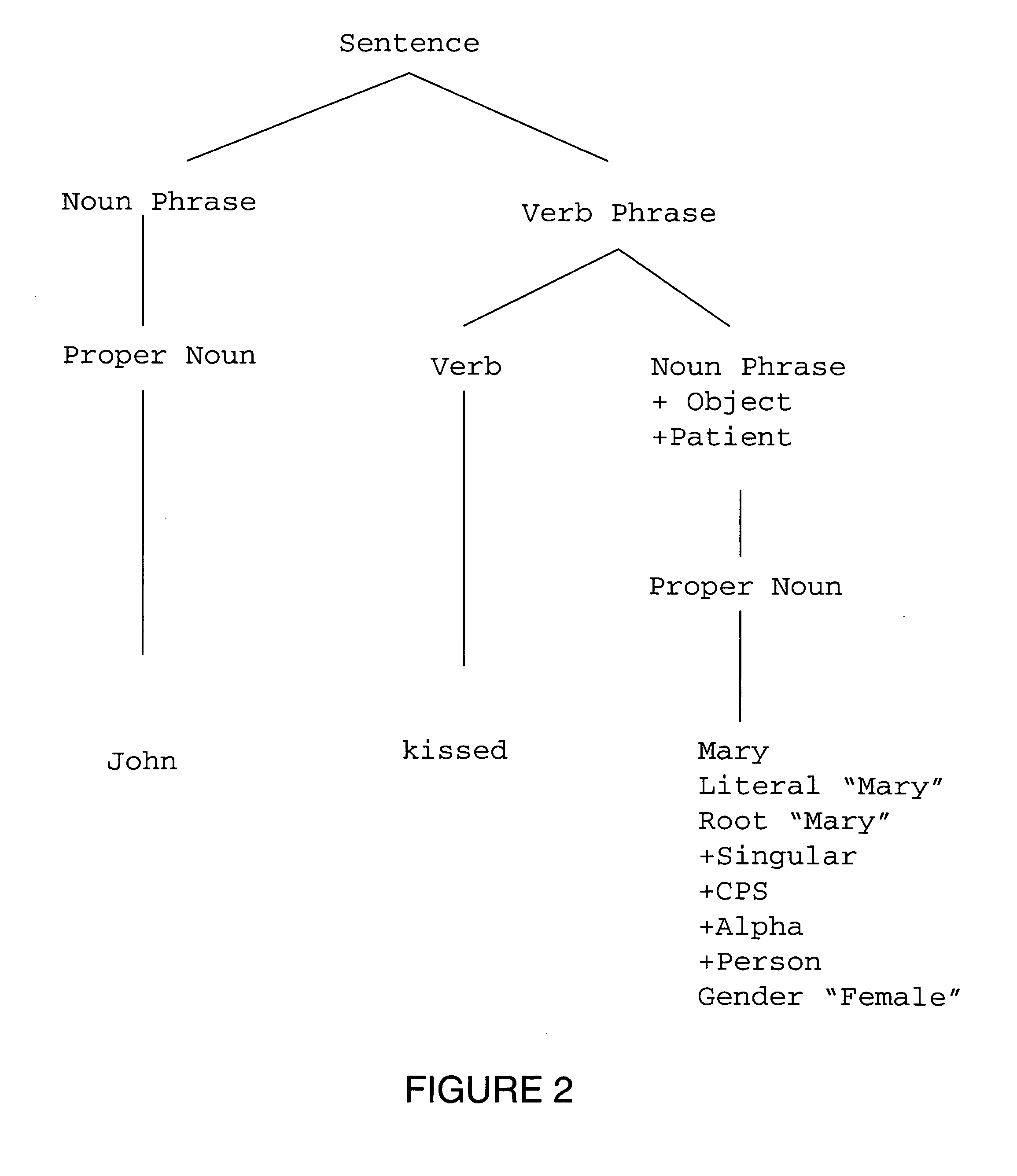
Examples
example
(b)
[0189]
ssssjjjj cccc nnnn
[0190] Step 1: Given a crossed XML document as in Example (a), convert contiguous character-sequences of the document to a Document Object Model (DOM) array of three object-types of contiguous document markup and content: START-TAGs, END-TAGs, and OTHER. Here START-TAGs and END-TAGs are markup defined by the XML standard, for example, is a START-TAG and is its corresponding END-TAG. START-TAGs and their matching END-TAGs are also assigned a NESTING-LEVEL such that a parent-node's NESTING-LEVEL is less than (or, alternatively, greater than) its desired children's NESTING-LEVEL. All other blocks of contiguous text, whether markup, white space, textual content, or CDATA are designated OTHER. For example, in one instantiation of this invention, Example (a) would be represented as follows:
(OTHER )(START nesting-level=‘1’)(START nesting-level=‘2’)(OTHER ssss )(START nesting-level=‘5’)(OTHER jjjj)(START nesting-level=‘3’)(OTHER cccc)(START nesting-lev...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More