

System for transferring personalize matter from one computer to another
a technology of personalization and computer, applied in the field of computer voice recognition enhancements, can solve problems such as machine dependency and speaker dependency, and leave users frustrated with accuracy and performance of voice recognition applications
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Benefits of technology
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
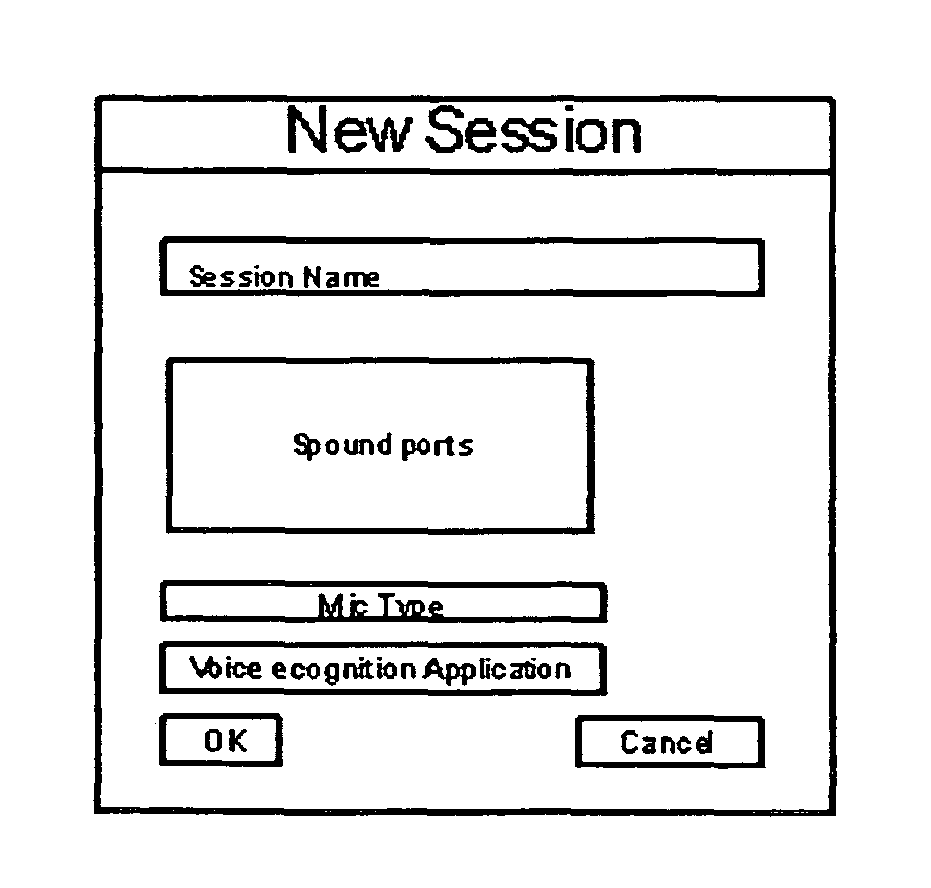
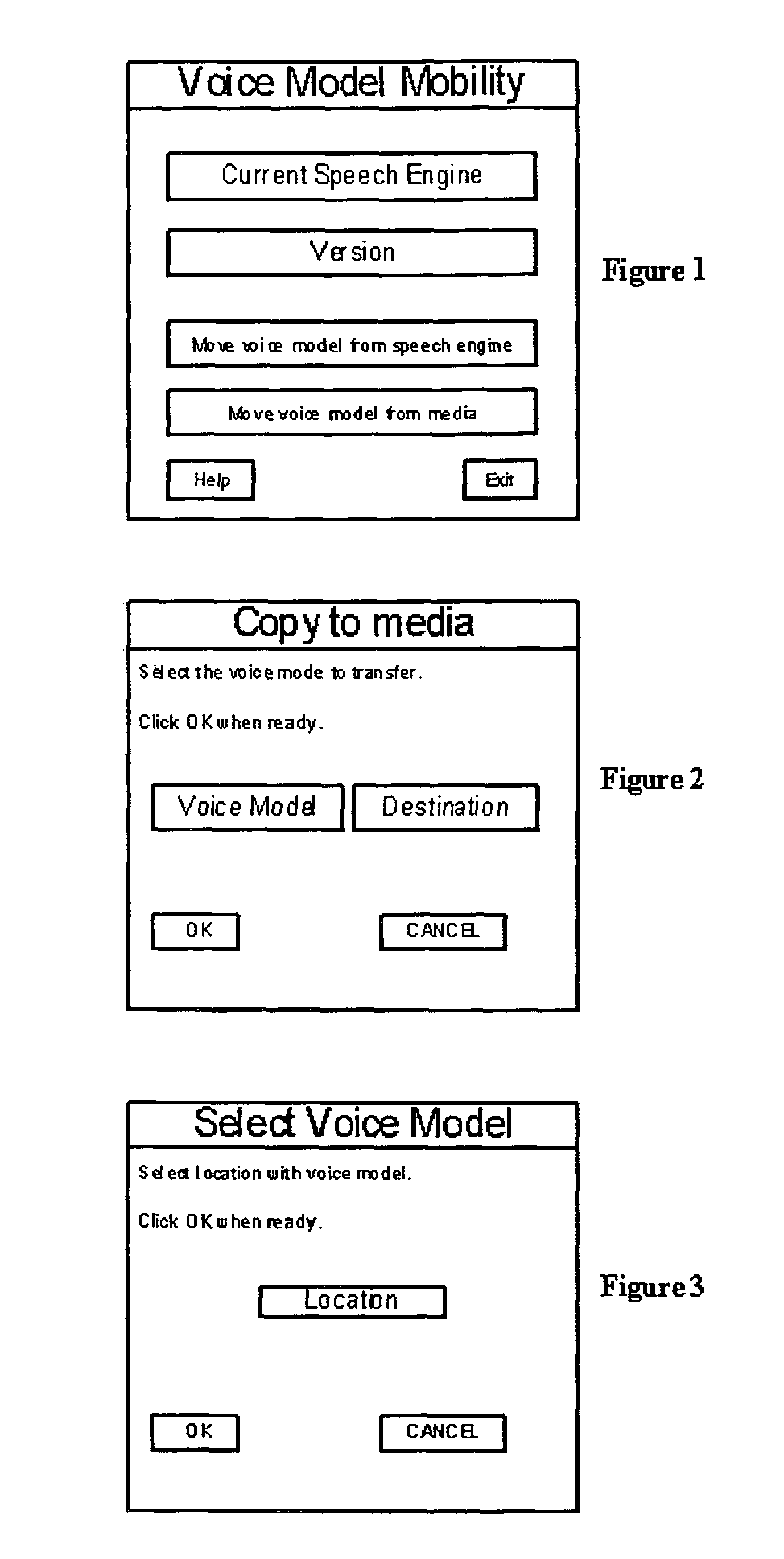
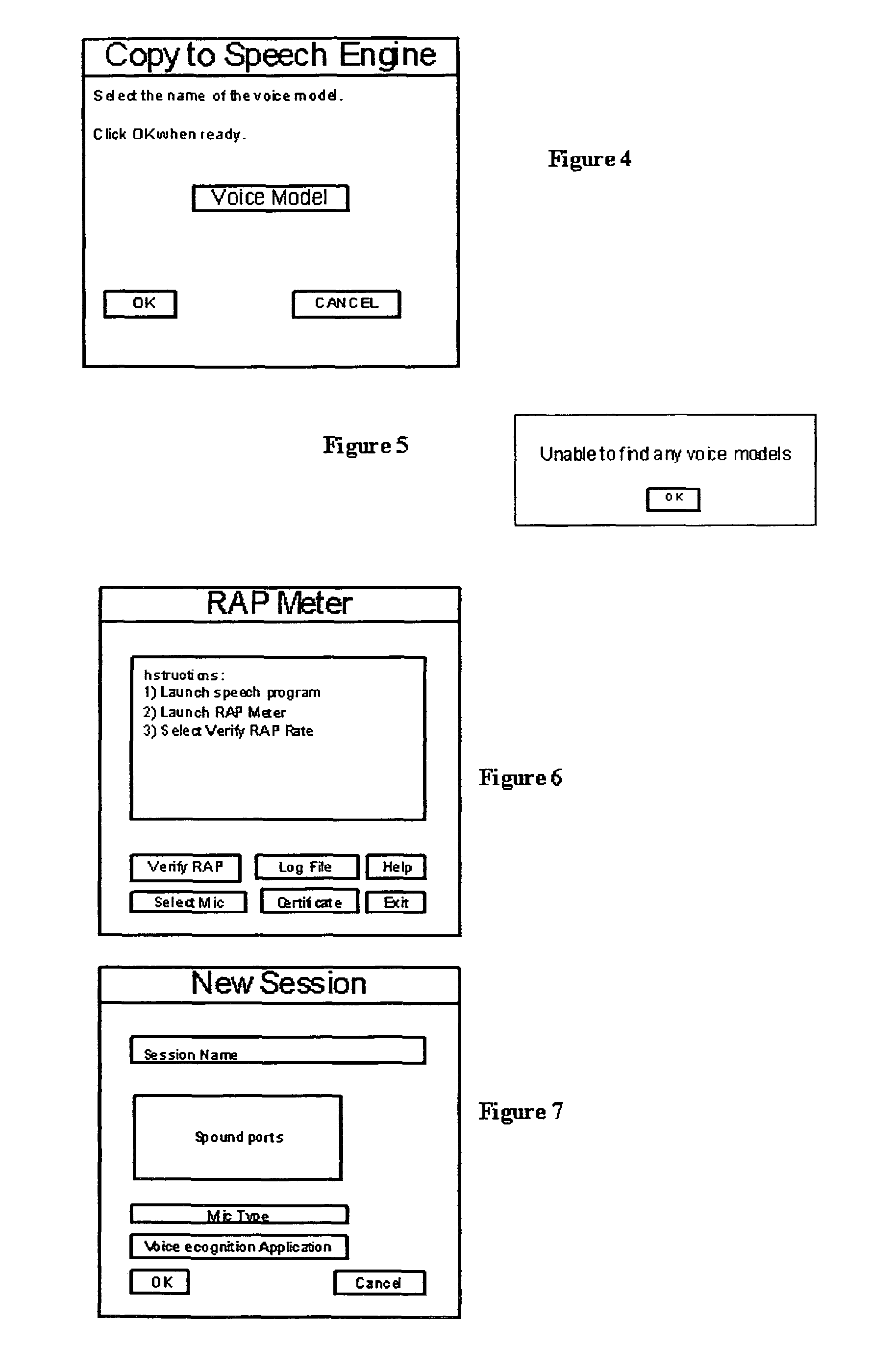
[0031]It is the object of this invention to provide a method for transferring voice models defined as Voice Model Mobility. Voice Model Mobility (VMM) was originally conceived due to the problem of having to train multiple voice recognition dictation machines for a single person's voice. This was discovered when experimenting with voice recognition dictation applications. It was determined that a better way to use multiple machines was to separate the files and parameters that characterize the user, package the files and parameters as a voice model and move them to a medium for transfer and installation into another separate system. Voice models and a means to package, move them, and install them can and should be independent of the voice recognition applications allowing the owner of a voice model the ability to plug into and use any voice recognition machine. Voice models and training are assumed needed and can be time-consuming therefore; voice recognition applications provided b...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More