

Method for conducting words reading sequence recovery for newspaper pages
A technology of reading order and text, applied in the fields of electronic digital data processing, instrumentation, calculation, etc., can solve the problem of unfavorable information reuse and deep processing such as retrieval, utilization, transaction, rewriting, supplementing, sorting, time complexity increase, and lack of chapter independence. Issues such as reading order and structure
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
[0049] The present invention will be further described below in conjunction with the accompanying drawings and examples.
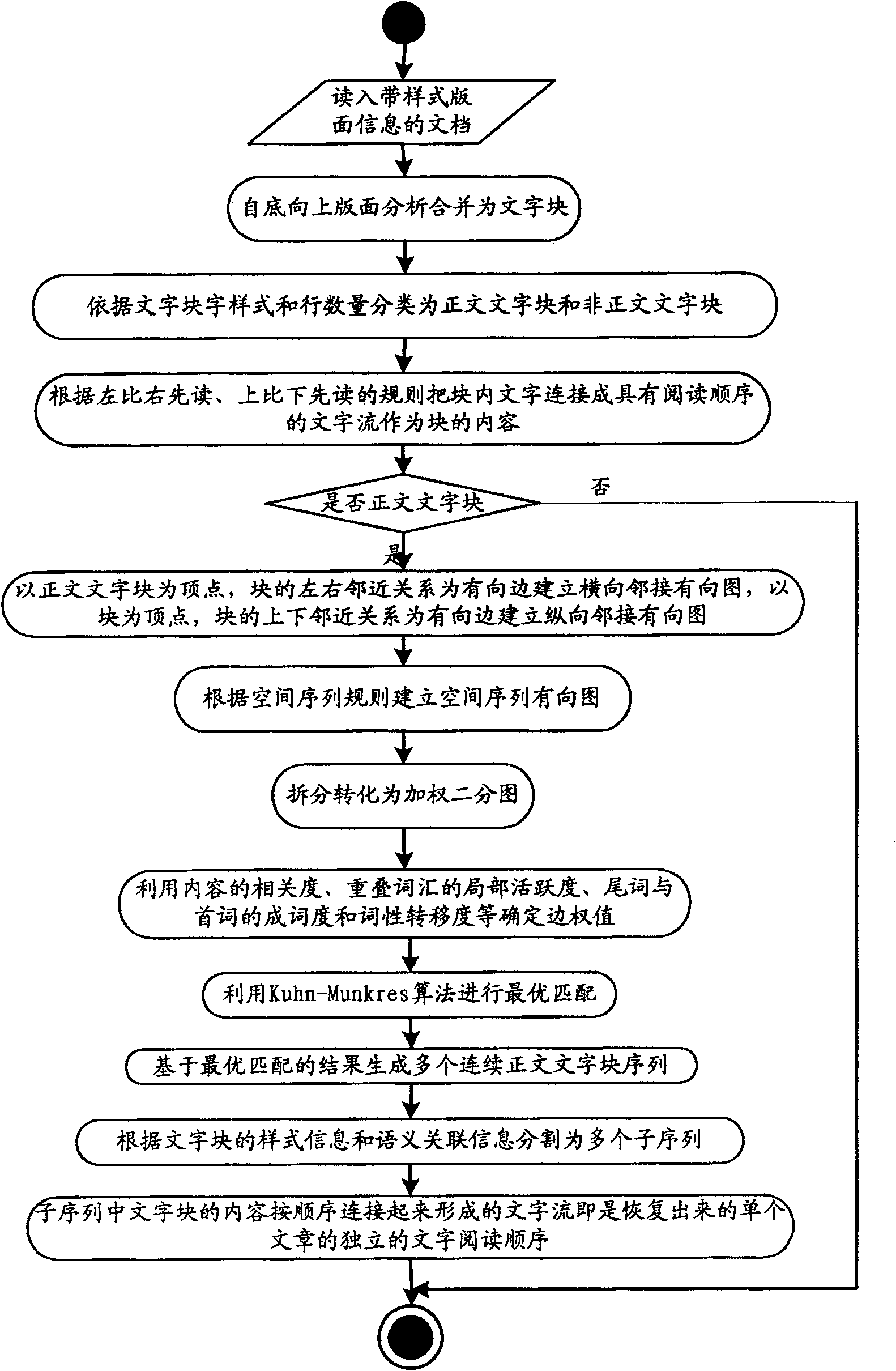
[0050] In this embodiment, we have selected the newspaper document scanned by OCR as the example data, such as figure 1 As shown, a method for restoring the text reading order of a newspaper layout includes the following steps:
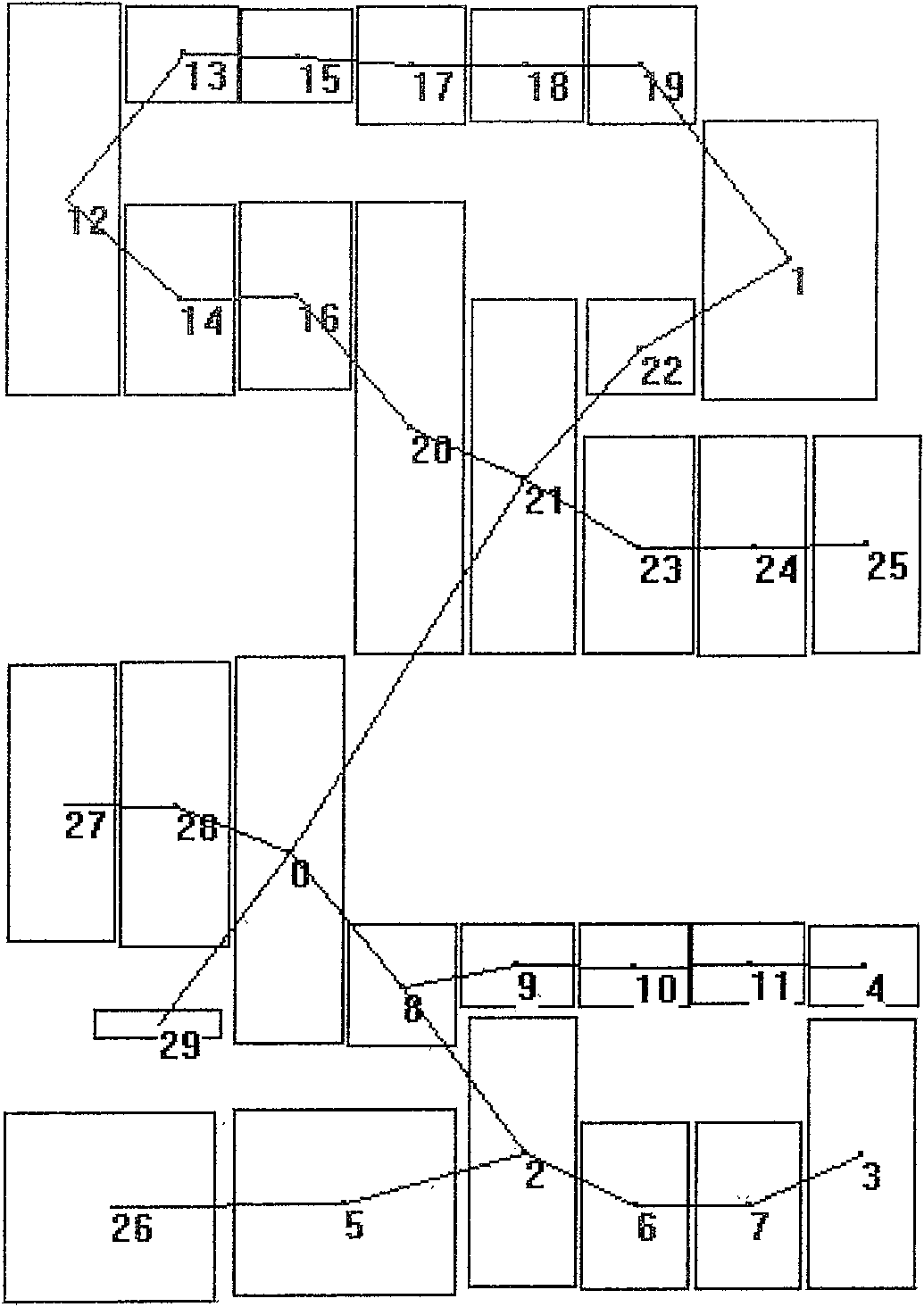
[0051] 1. Read in documents with style layout information, including scanned paper newspapers and OCR-recognized documents, PDFs, documents generated by professional typesetting software such as Founder Feiteng, etc. Style information mainly refers to the position and size information of each word . Layout analysis merges text with the same style into text blocks from bottom to top according to the principle of partial style homogeneity; the classification of text blocks is divided into text blocks and non-text blocks according to the style of text blocks and the number of lines, such as figure 2 As shown in , the solid line re...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More