A method for chip storage applicable motion estimation
A technology of motion estimation and on-chip storage, which is applied in the field of video coding and decoding, and can solve problems such as occupation
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

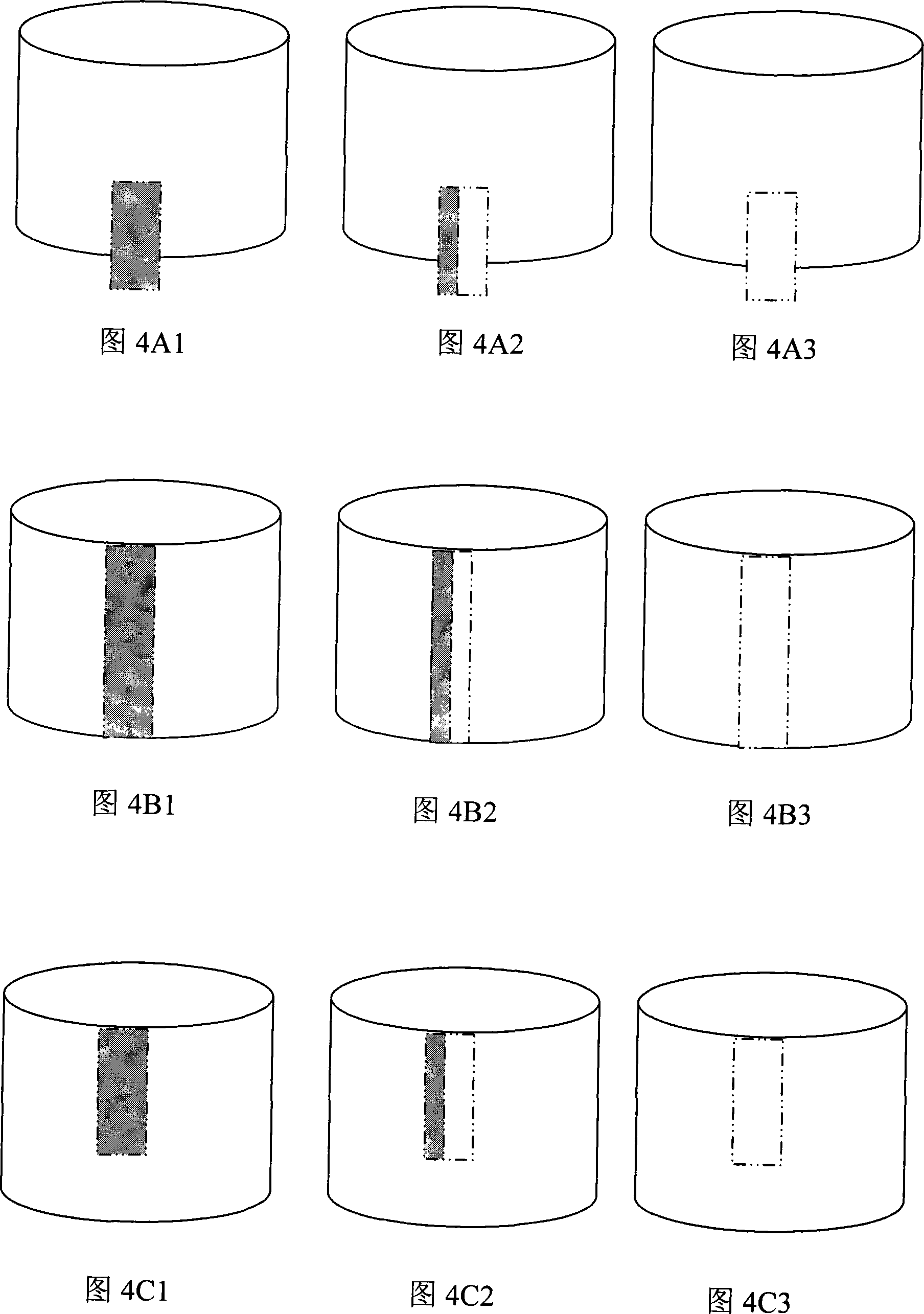
Examples
Embodiment Construction
[0015] Below, according to Fig. 1 to Fig. 7, a preferred embodiment of the present invention is given and described in detail, so that the functions and characteristics of the present invention can be better understood.
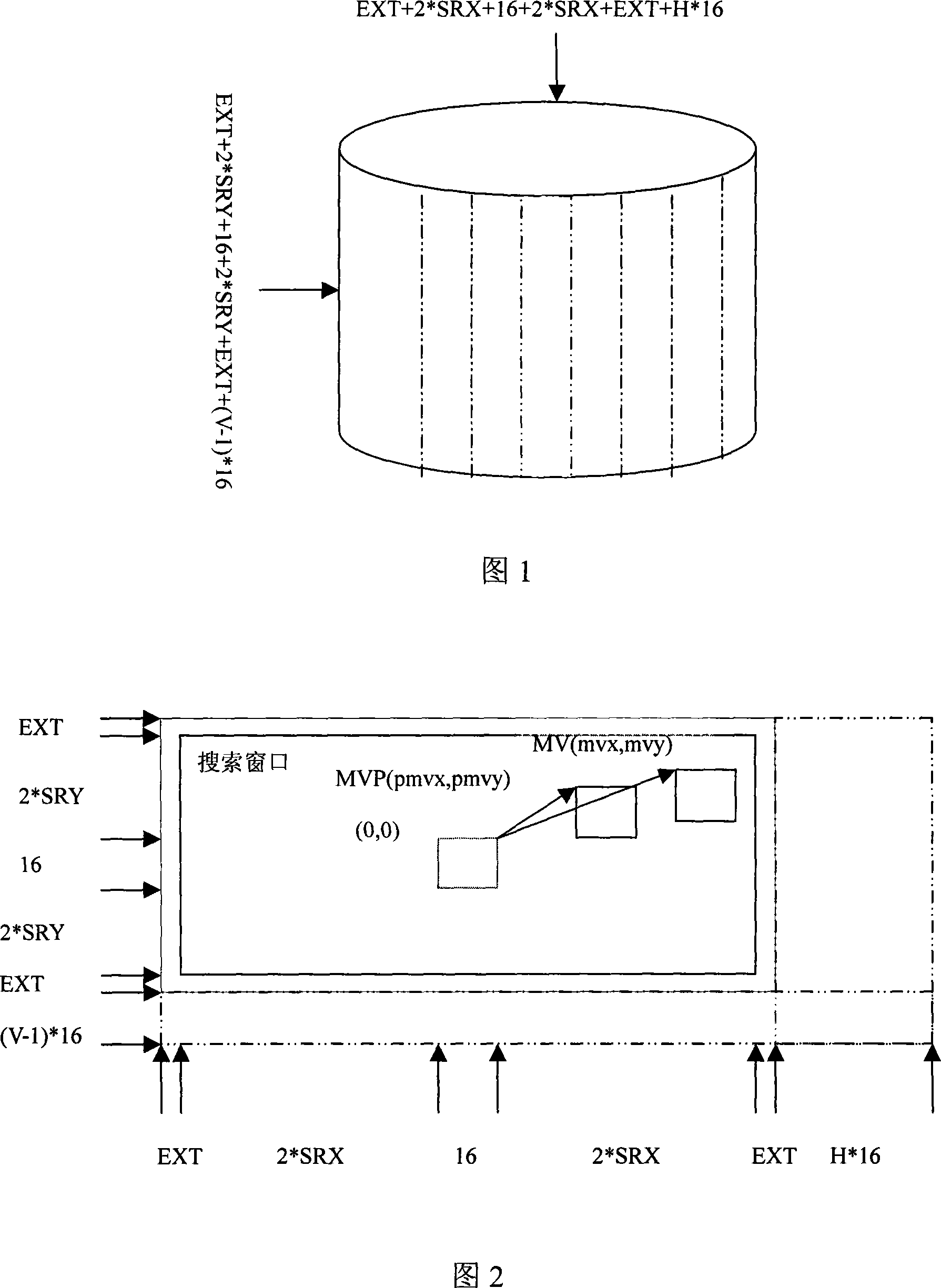
[0016] The present invention designs a circular columnar on-chip space to realize data prefetching, data reuse, space reuse, whole pixel motion estimation, sub-pixel motion estimation, and motion compensation, so as to speed up, reduce bandwidth, The purpose of saving storage.
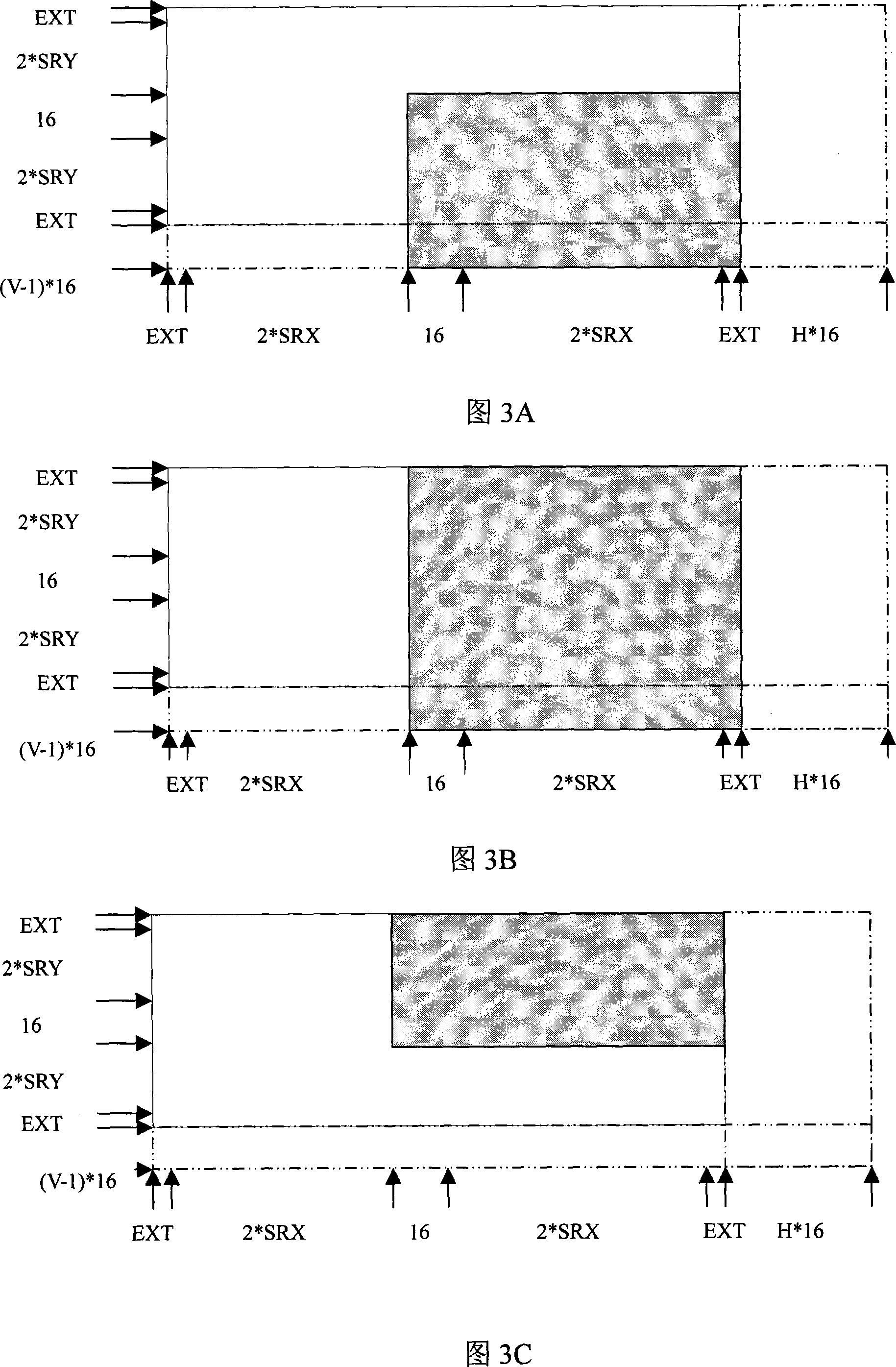
[0017] The space inside the ring column is like this: the circumference of the ring column=EXT+2*SRX+16+2*SRX+EXT+H*16, the height of the ring column=EXT+2*SRY+16+2*SRY+ EXT+(V-1)*16, 16 is the width and height of the macroblock. SRX is the search range in the X direction, and SRY is the search range in the Y direction. EXT is the number of integer pixels above, below, left, and right of the optimal integer pixel required for 1 / 4 pixel interpolation. For AVS and h.264, EXT=3. H=1,2...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com