

Partitioning and thread-aware based performance optimization method of last level cache (LLC)
A technology of last-level cache and optimization method, which is applied in the direction of memory system, memory address/allocation/relocation, instrument, etc., and can solve problems such as difficulty in improving the performance of multi-processor global cache
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

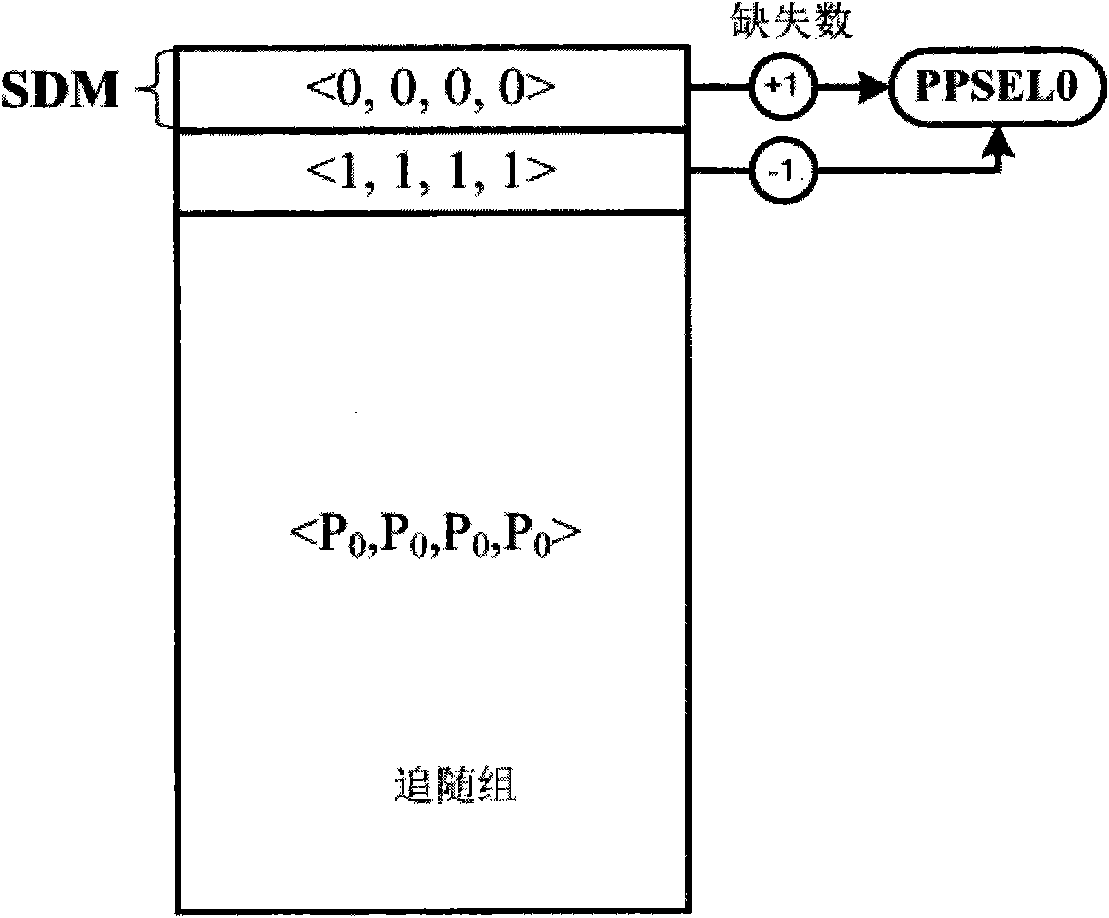
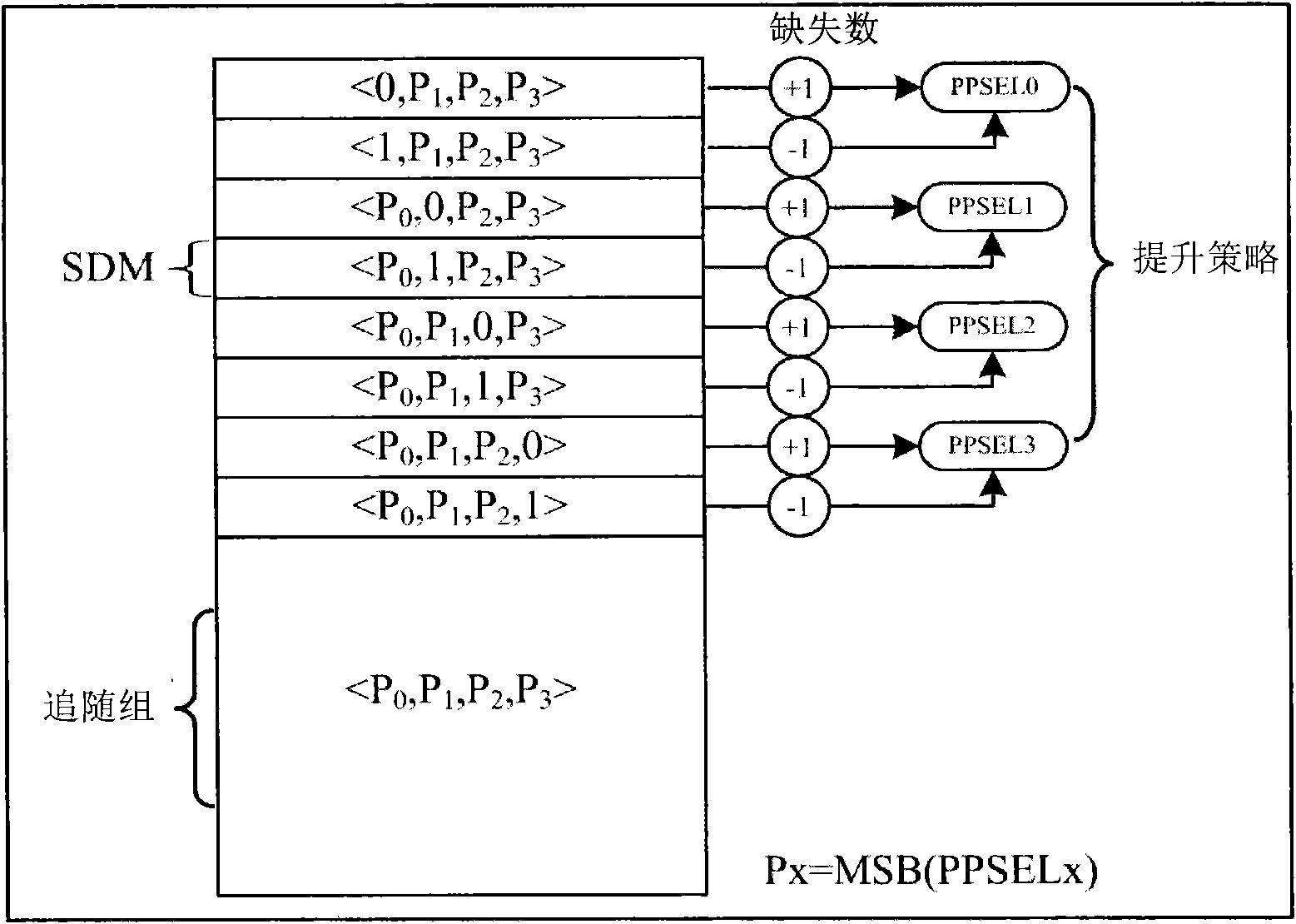
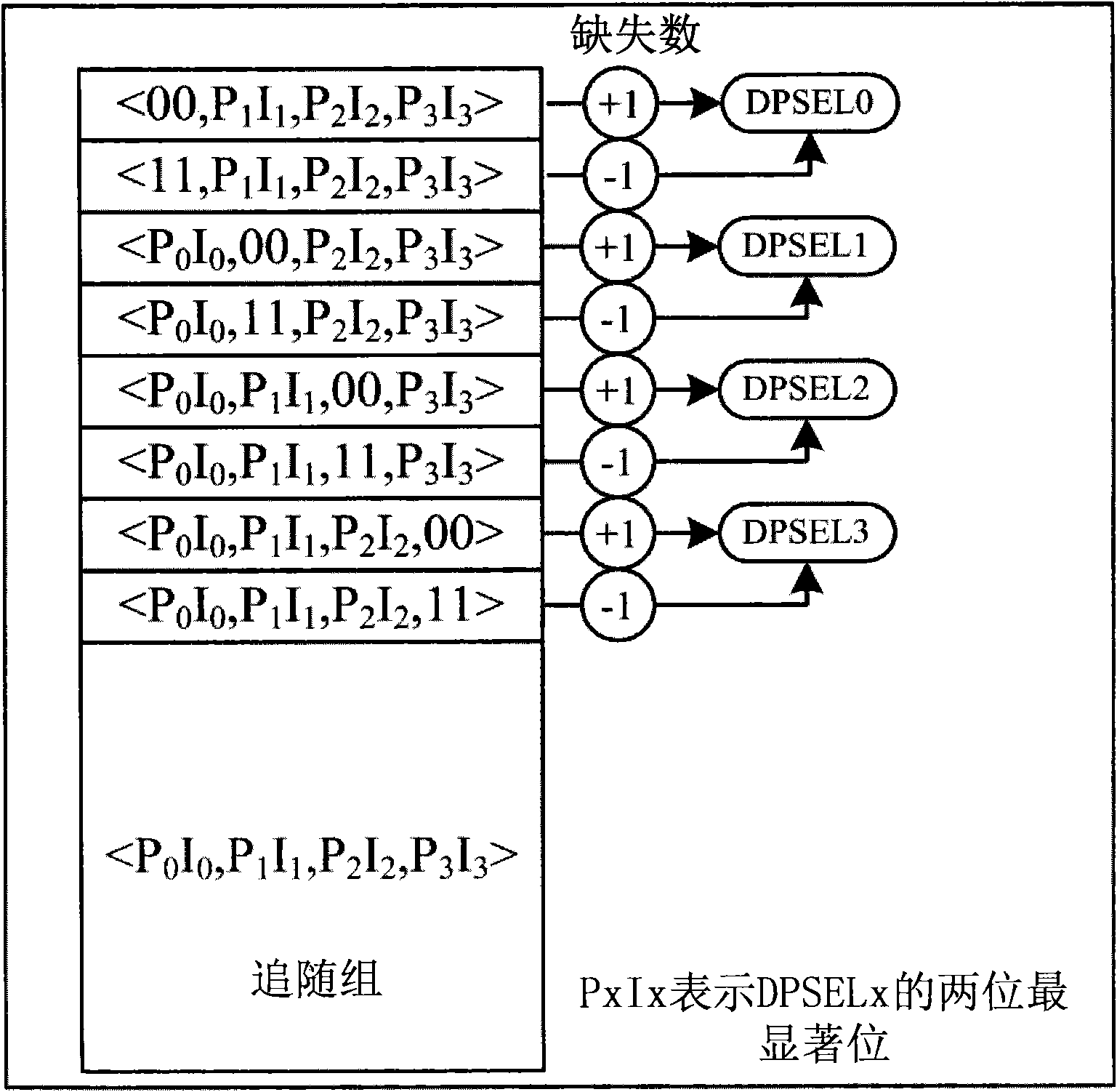
Examples
Embodiment Construction
[0055] The above solution will be further described below in conjunction with specific embodiments. It should be understood that these examples are used to illustrate the present invention and not to limit the scope of the present invention. The implementation conditions used in the examples can be further adjusted according to the conditions of specific manufacturers, and the implementation conditions not indicated are usually the conditions in routine experiments.
[0056] Embodiment This embodiment uses an event-driven, cycle-accurate multi-core simulator Multi2sim based on x86 instruction set architecture to evaluate the effectiveness of the PAE-TIP method. The target simulation platform is a 4-way multi-core processor, and all processor cores share a 4MB, 16-way set-associative secondary cache. Each processor core is a 4-issue, out-of-order superscalar structure, and has a private first-level instruction and data cache. See Table 2 for detailed configuration information...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More