

Fault tolerance optimizing method of intermediate data in cloud computing environment
A cloud computing environment, intermediate data technology, applied in data exchange networks, digital transmission systems, electrical components, etc., can solve problems such as reducing the overall performance of the system, affecting the completion time of tasks, occupying network resources, etc., to solve the problem of network resource contention. use, ensure low interference, and the effect of high backup overhead
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
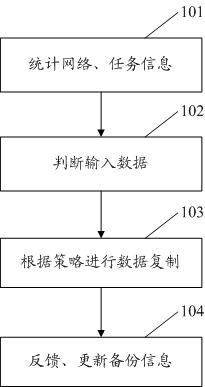
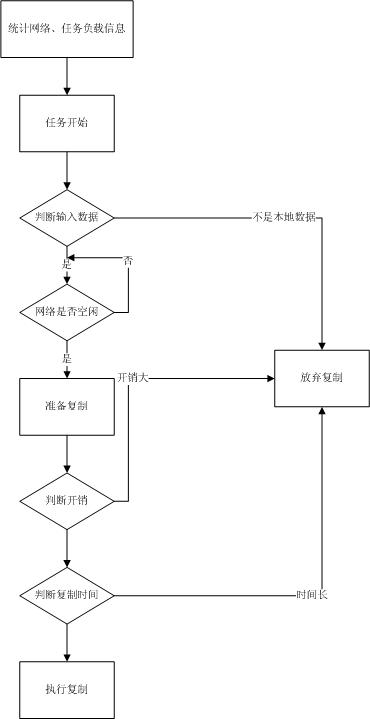
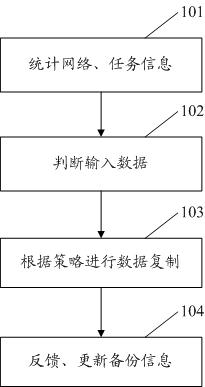
[0018] In order to make the object, technical solution and advantages of the present invention more clearly, the present invention will be further described in detail below in conjunction with the accompanying drawings and specific embodiments.
[0019] The main idea of the present invention is to dynamically adjust the replication of intermediate data according to the network load, task execution progress and resource usage status during task execution in the cloud computing environment, and to carry out real-time control of intermediate data replication by combining statistical network load and task execution conditions, In order to ensure the replication of intermediate data without interfering with the execution of foreground tasks.
[0020] Data is sorted first, reducing replication overhead. The data generated locally will be automatically deleted after use in the next stage, while the data generated by other nodes will be automatically saved after use by different nod...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More