

Method for processing cross task data in distributive network system
A distributed network and task data technology, which is applied in the field of processing cross-task data, can solve the problems of not considering the locality of cross-task data and limiting the calculation speed of tasks, so as to avoid repeated loading of input data and realize the effect of repeated use
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

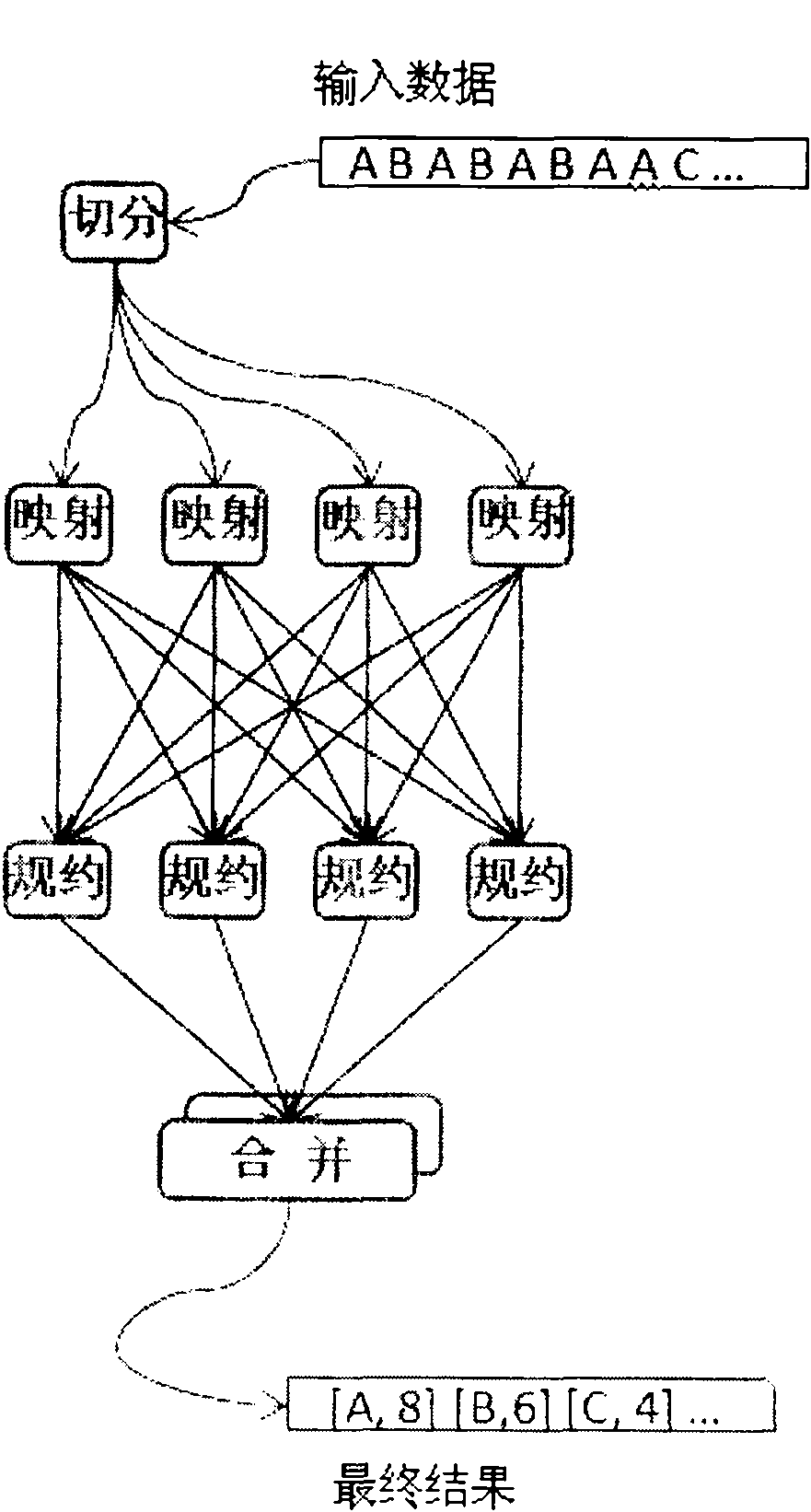
Examples
Embodiment Construction
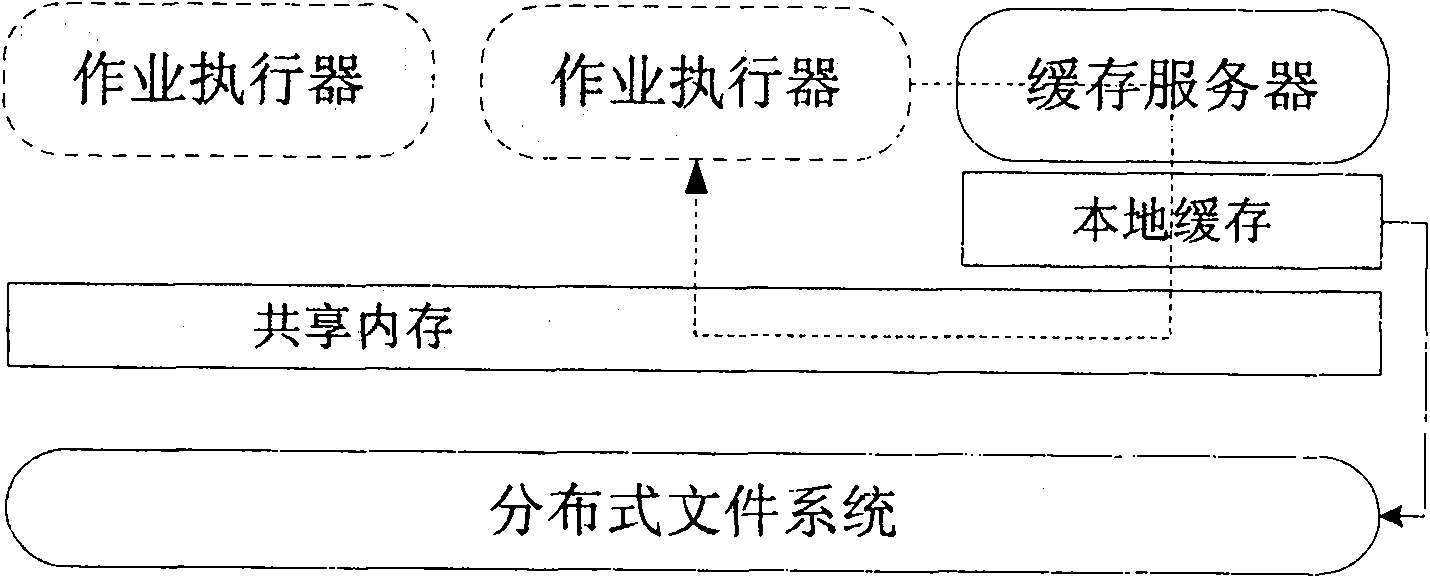
[0019] Such as figure 2 As shown, the network distributed file system architecture operated according to the method of the present invention includes a named node, namely the master node, and multiple working nodes, namely the slave nodes. On a cluster, each job executor corresponds to a worker node, and the master node (not shown in the figure) is responsible for scheduling all worker nodes.
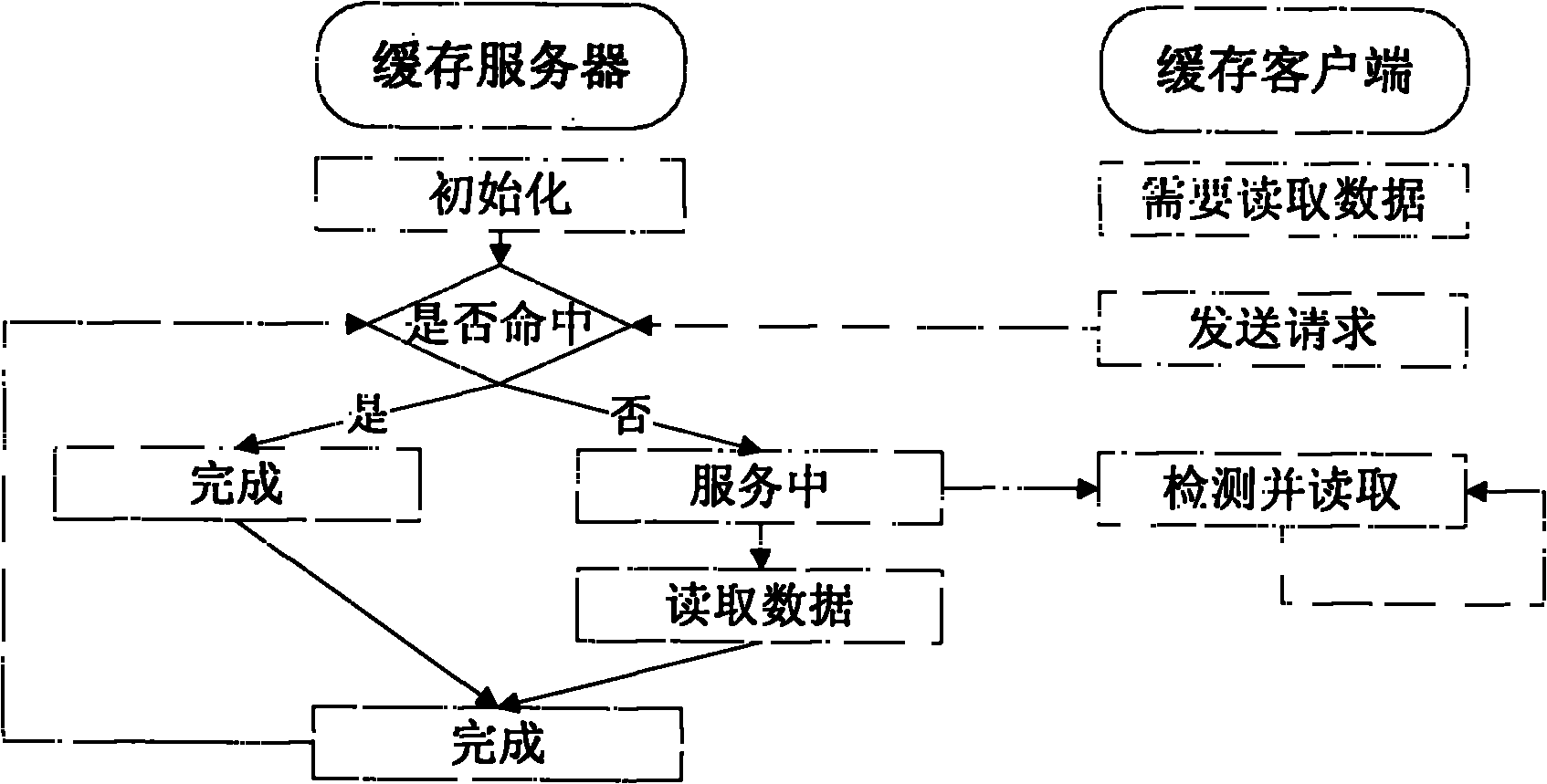
[0020] According to the method of the present invention, a cache system is set up at each distributed slave node, including a cache server and a cache client, and works in an access proxy mode similar to a distributed file system. As shown in the figure, all read requests from the job executor are forwarded by the cache client to the cache server; the cache server will read the requested data from the distributed file system, save it in the local cache in the shared memory, and pass the signal The amount is notified to the master node. The cache system can save the data read by the t...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More