Dynamic detection method for multi-data concentrated and repeated records
A technology of repeated recording and dynamic detection, which is applied in the direction of electrical digital data processing, special data processing applications, instruments, etc., and can solve problems such as not suitable for multiple data sets, low efficiency, and inability to incrementally detect changes in repeated records
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

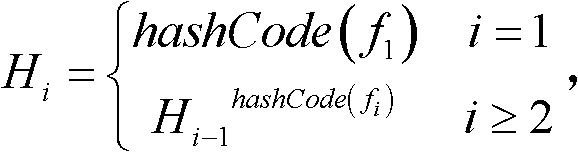
Examples
Embodiment
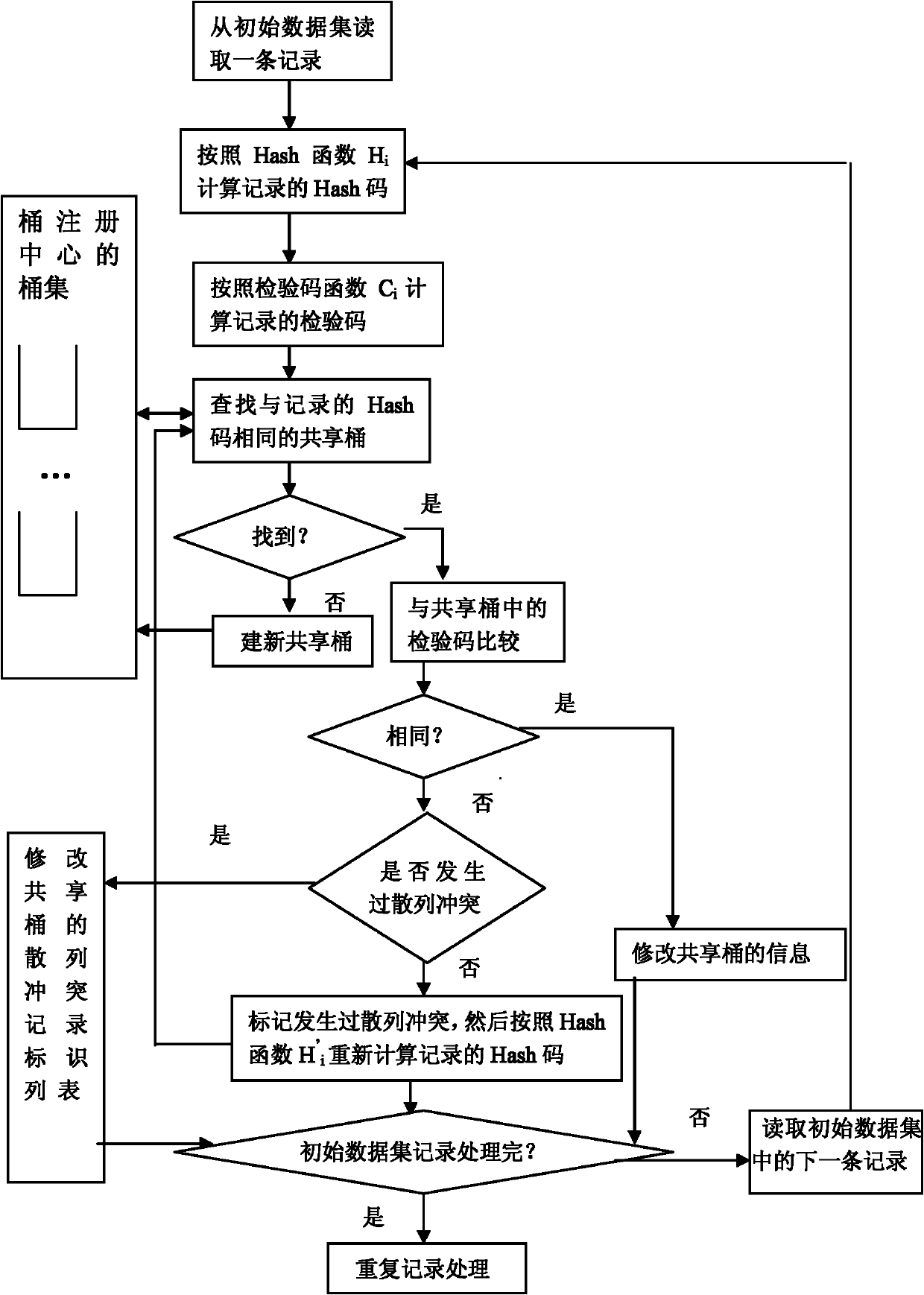
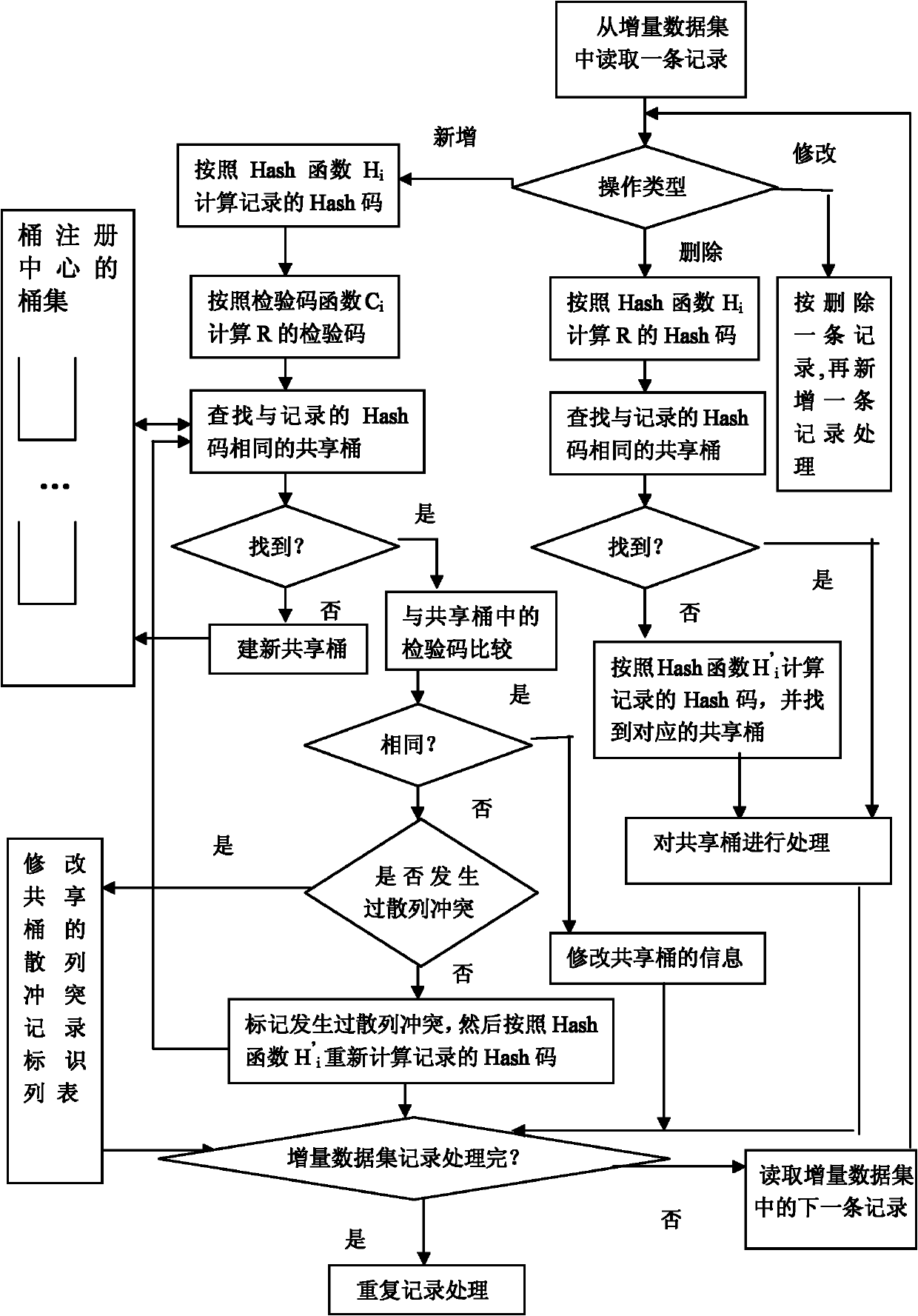
[0082] As shown in Figure 1, a hash-based method for dynamically checking duplicate records in multiple datasets includes the following steps:
[0083] A method for dynamic detection of duplicate records in multiple datasets, comprising the following steps:
[0084] (1) Read a record from the initial data set, suppose the record is composed of N intrinsic fields, and the i-th intrinsic field is f i , where 1≤i≤N;
[0085] (2) Calculate the recorded Hash code, the calculation method of the recorded Hash code is:
[0086] The Hash function is as follows:
[0087] H i = hashCode ( f 1 ) i = 1 H i ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com