Automatic personalized abstracting method in digital library system
A digital book and automatic summarization technology, applied in the field of information processing, can solve the problem of low coverage of main information in documents, and achieve the effects of strong anti-interference ability, flexible acquisition, and high accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
[0049] The most basic implementation mode of the present invention comprises the following steps:
[0050] a. Input query information, the query information includes keywords and personalized information of users;
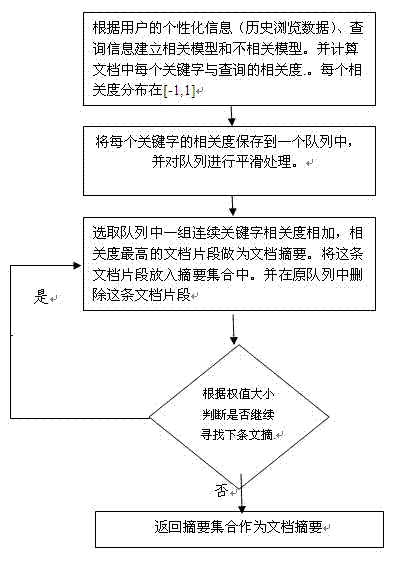
[0051] b. Establish a relevant model and an irrelevant model according to the input query information, the relevant model refers to the probability distribution function of the natural language model of the query statement, and queries the digital book system with keywords to obtain the top 5-50 documents ;
[0052] The irrelevant model is a supplementary probability distribution function of the related model, which refers to all document collections in the digital library system;
[0053] Because in the language model built with the entire document set, the query related documents have only a small value, and the query irrelevance occupies the main factor, so the entire document set can be used to build an irrelevant model
[0054] c. For each word in the docume...
Embodiment approach
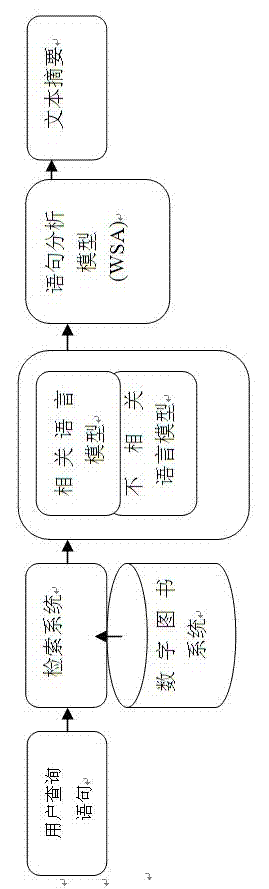
[0062] The automatic summarization system we introduced uses language model-related technologies in document processing and weighting, and uses word frequency statistics to weight sentences. The processing flow of the automated summary is as follows figure 1 . It shows the process of establishing a relevant model and an irrelevant model according to the query information input by the user after the user inputs the query information, and generating a personalized summary through the word sequence analysis model (WSA for short).
[0063] The process of summary extraction by related model and unrelated model:
[0064] We extract summary information based on statistical language models. In our research, two language models are constructed: one is a correlation model, which is defined as ;The other is an uncorrelated model, which is defined as . related model is the probability distribution function of the natural language model of the query statement. In contrast, uncor...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com