

Subject area identifying method based on weight of text structure
A technology of subject area and text structure, applied in the field of Web information extraction, can solve problems such as affecting the application effect, slow extraction speed, usage restrictions, etc., to save time and energy, run fast, and achieve simple effects
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0096] The technical solution of the present invention will be described in detail below in conjunction with the drawings and embodiments.
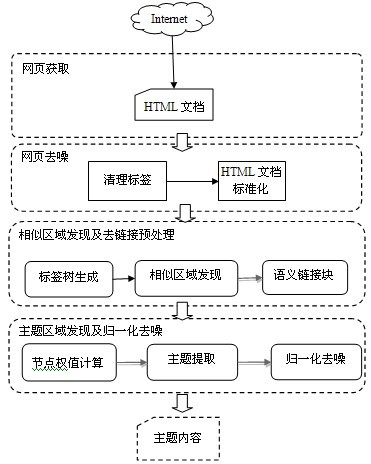
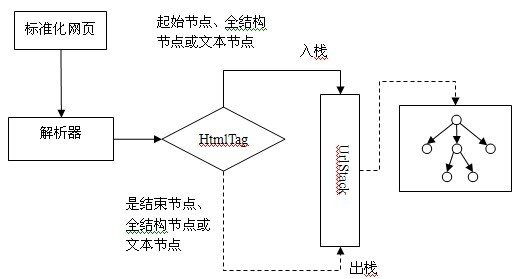
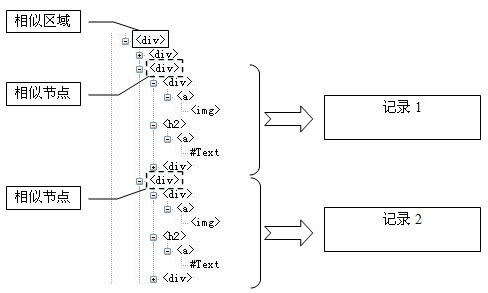
[0097] Such as figure 1 As shown, in the embodiment, the web page is acquired first, and then the web page is denoised, so as to obtain the web page to be identified. Web page acquisition is the most original data source and is responsible for providing Web pages to be identified. Concrete implementation can adopt a simple and easy breadth priority crawler to realize webpage acquisition, at first obtain webpage from Internet (Internet) by seed URL address, analyze wherein link then, fresh link is stored in the queue, then cycle takes out link from queue, until Stop when the user goal is reached or the queue is empty. Web page denoising is to standardize the obtained web pages, which can improve the recognition accuracy. During the specific implementation, the HTML document of the web page to be identified can be standardized acco...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More