

High sliding window data stream anomaly detection method based on layered clustering
A multi-data stream and sliding window technology, which is applied in the field of multi-data stream anomaly detection, can solve the problems of reduced accuracy of data stream anomaly detection results, and achieve the effect of effective storage
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
specific Embodiment approach 1
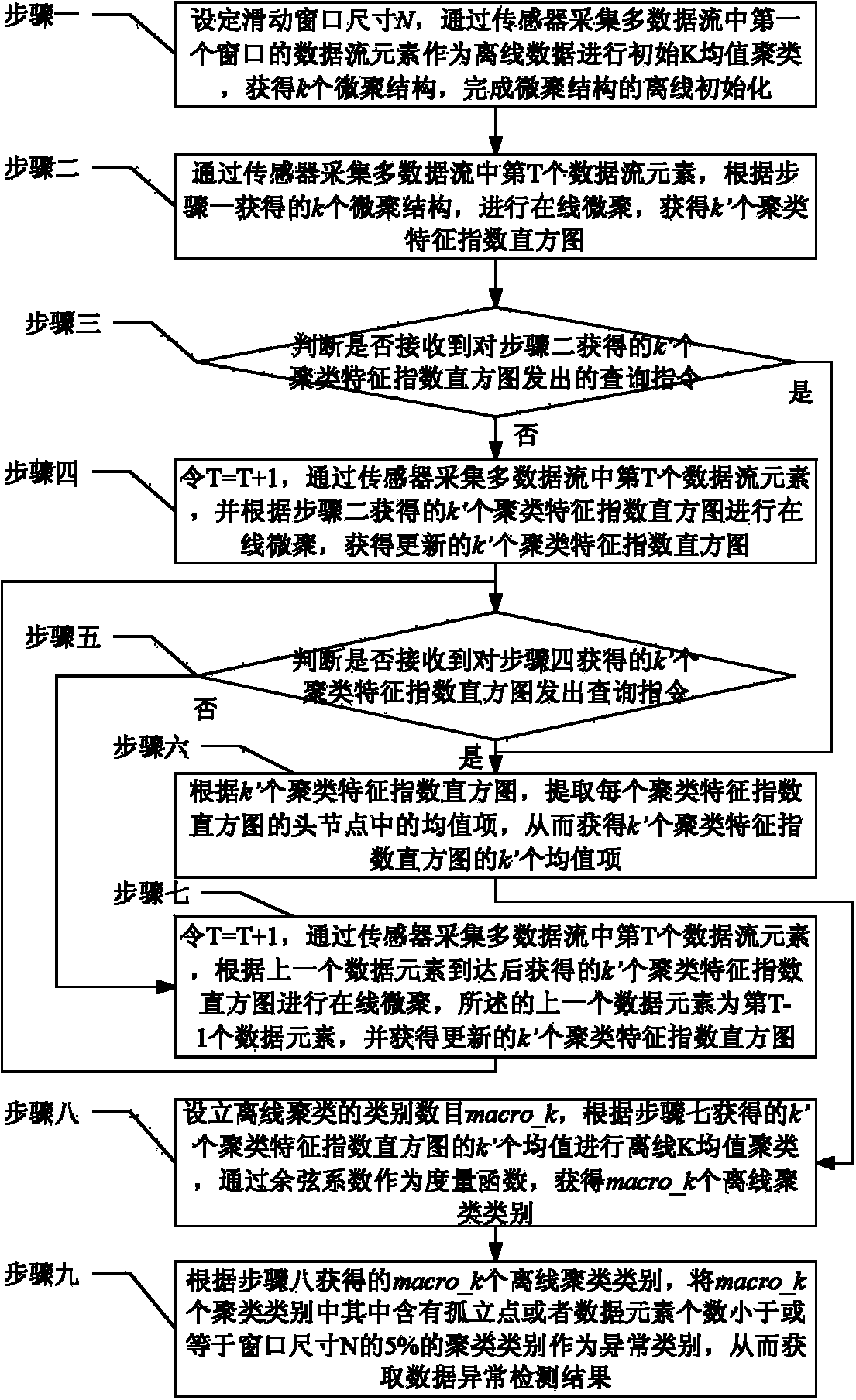
[0046] Specific implementation mode 1. Combination figure 1 This embodiment is specifically described. The hierarchical clustering-based sliding window multi-data stream anomaly detection method described in this embodiment includes the following steps:
[0047] Step 1. Set the sliding window size N, collect the data flow elements of the first window in the multi-data flow through the sensor as offline data for initial K-means clustering (K-means clustering), obtain k clustering structures, and complete To do offline initialization of the aggregate structure, perform step 2;
[0048] Among them, N is a positive integer, N is greater than or equal to 1000 (users can draw up by themselves), k is the maximum value of the set cluster feature index histogram for online clustering,
[0049] Step 2: collect the Tth data stream element in the multi-data stream through the sensor, perform online clustering according to the k clustering structures obtained in step 1, obtain k' cluster ...
specific Embodiment approach 2
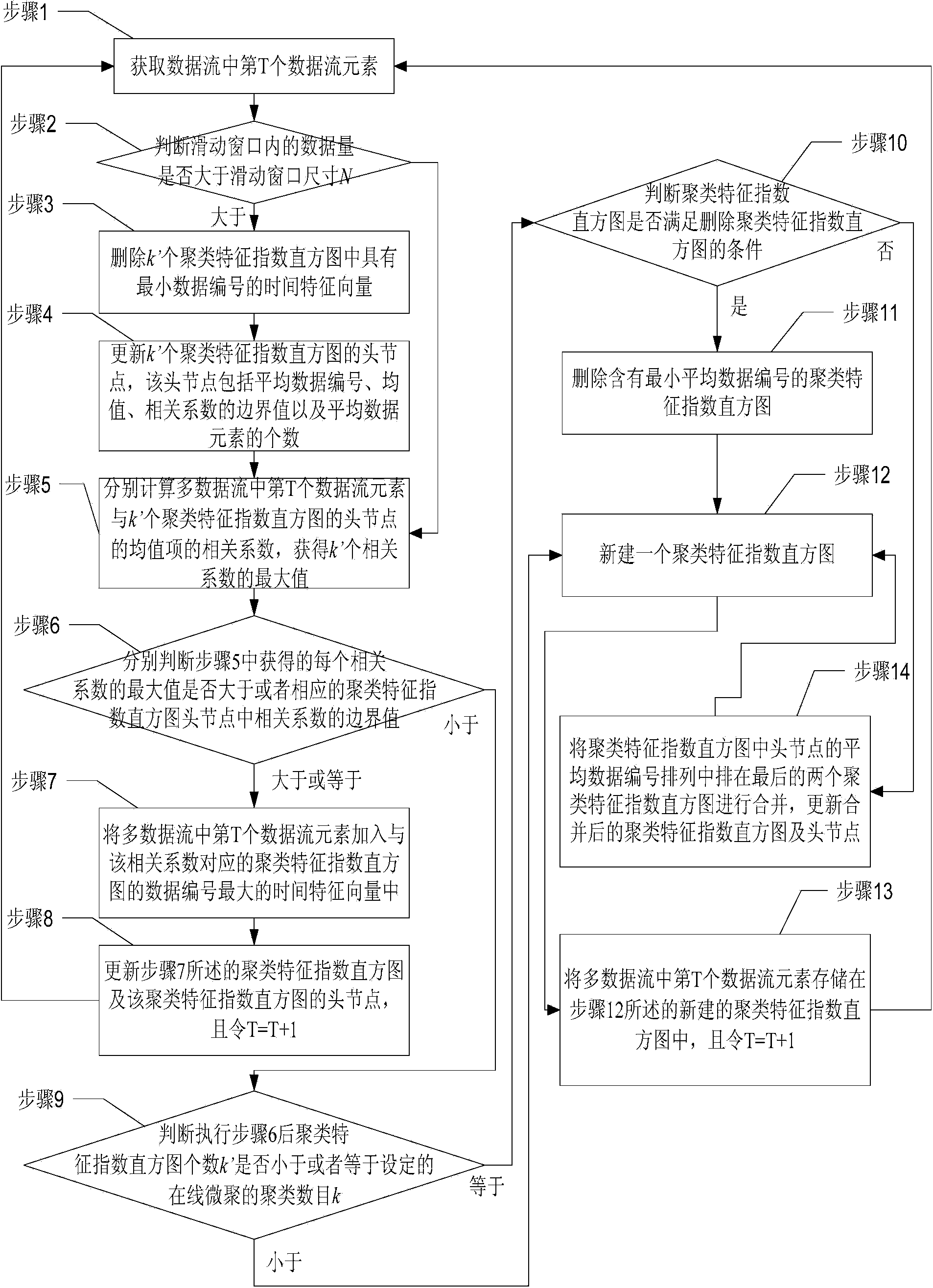
[0128] Embodiment 2. The difference between this embodiment and the hierarchical clustering-based sliding window multi-data stream anomaly detection method described in Embodiment 1 is that in step 7, k' obtained after the arrival of the last data element The histograms of clustering feature indices are clustered online, the last data element is the T-1th data element, and the specific process of obtaining the updated k' clustering feature index histograms is as follows:
[0129] Step 1. Obtain the Tth data flow element in the data flow, and execute step 2;
[0130] Step 2. Determine whether the amount of data in the sliding window is greater than the size N of the sliding window. If it is larger, perform step 3. If it is less than or equal, perform step 5;
[0131] Step 3, delete the time feature vector with the minimum data number (that is, the bucket with the minimum data number) in the k' clustering feature index histogram, and perform step 4;
[0132] Step 4. Update the ...
specific Embodiment approach 3
[0176] Embodiment 3. The difference between this embodiment and the hierarchical clustering-based sliding window multi-data stream anomaly detection method described in Embodiment 1 is that the offline K-means clustering described in step 8 is:
[0177] In multiple data streams, online clustering obtains k' cluster feature index histograms, and the mean value of its head nodes is used as data for offline clustering, and the mean values of k' head nodes for clustering structure are respectively {EHCF 1 .mean, EHCF 2 .meam,...,EHCF k’ .mean}, the mean value of k' nodes is used as the input of the K-means clustering algorithm (that is, as the original data that needs to be clustered), macro_k is the number of categories of offline clustering, and the similarity measure in the K-means clustering algorithm The function takes the Euclidean distance and the cosine of the included angle respectively.
[0178] In order to verify the detection performance of the sliding window multi...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More