

Working scheduling method and device
A job scheduling and job technology, applied in the field of cloud computing resource management, can solve problems such as low job execution efficiency and low resource utilization, and achieve the effect of solving resource waste, improving resource utilization, and
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
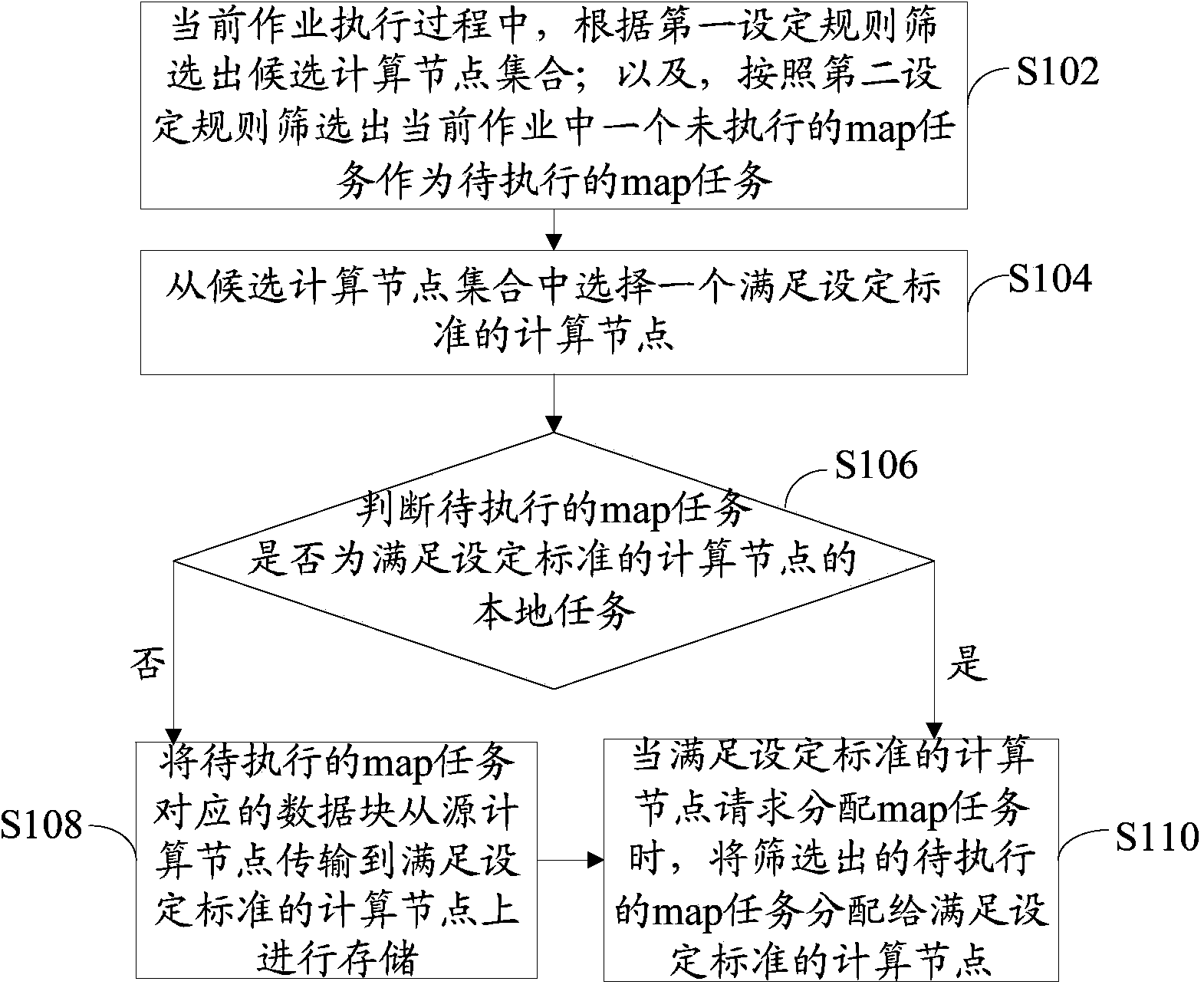
[0025] refer to figure 1, shows a flow chart of steps of a job scheduling method according to Embodiment 1 of the present invention.
[0026] The steps of the job scheduling method in this embodiment are as follows:
[0027] Step S102: During the execution of the current job, filter out a set of candidate computing nodes according to the first set rule; and filter out an unexecuted map task in the current job as the map task to be executed according to the second set rule.
[0028] Wherein, a job includes at least one map task.
[0029] The first setting rule and the second setting rule in this embodiment can be set by those skilled in the art according to actual needs. For example, the first setting rule can be set as follows: when there are idle computing nodes in the Hadoop cluster executing the current task, all idle computing nodes will form a set of candidate computing nodes; when there are no idle computing nodes, map will be executed The computing nodes of the task ...
Embodiment 2
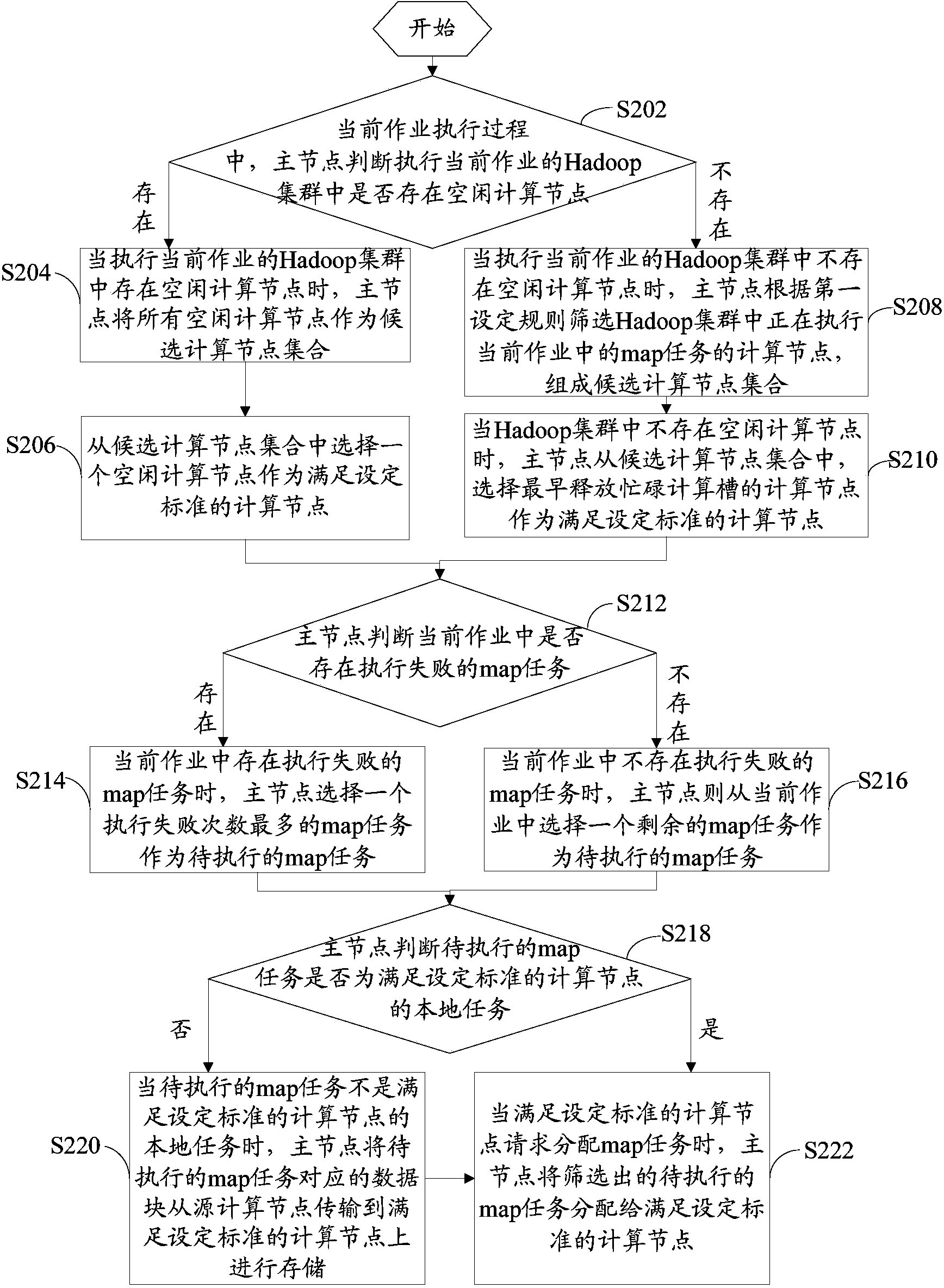
[0044] refer to figure 2 , shows a flow chart of steps of a job scheduling method according to Embodiment 2 of the present invention.
[0045] The specific steps of the job scheduling method in this embodiment include:
[0046] Step S202: During the execution of the current job, the master node judges whether there is an idle computing node in the Hadoop cluster executing the current job. If yes, execute step S204; if not, execute step S208.
[0047] Step S204: When there are idle computing nodes in the Hadoop cluster executing the current job, the master node takes all idle computing nodes as a set of candidate computing nodes.
[0048] Step S206: Select an idle computing node from the set of candidate computing nodes as a computing node meeting the set criteria.
[0049] It should be noted that when selecting an idle computing node as a computing node that meets the set criteria, any idle computing node can be selected, or a local node of a subsequently selected map task ...
Embodiment 3
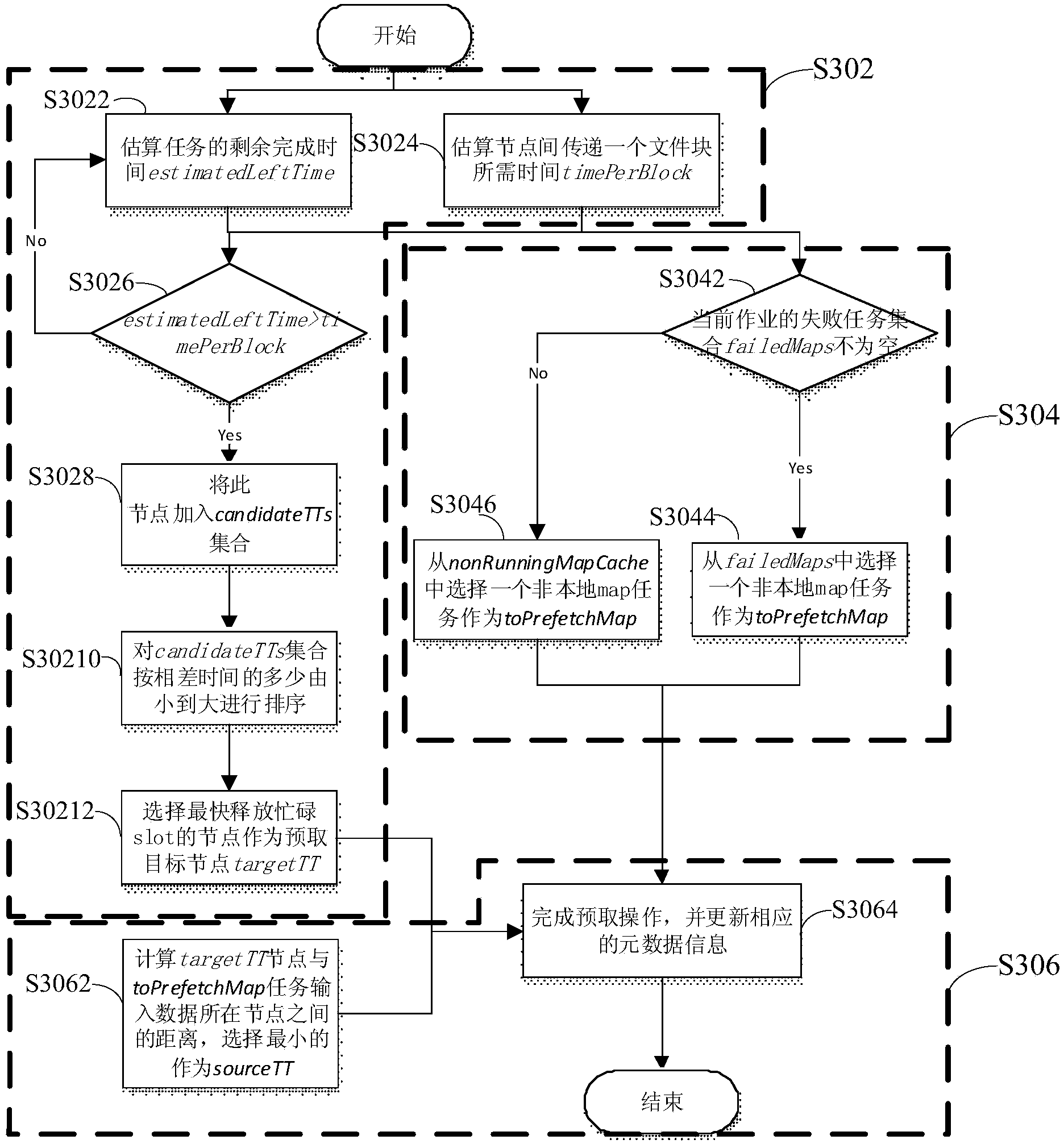
[0079] refer to image 3 , shows a flow chart of steps of a job scheduling method according to Embodiment 3 of the present invention.
[0080] In this embodiment, the job scheduling method in the present invention is described in detail on the premise that each computing node in the Hadoop cluster is executing the map task in the current job.
[0081] In this embodiment, it is assumed that there is a Hadoop cluster C, which is composed of N TT (TaskTracker, computing node) and a JT (JobTracker, master node), the cluster can be expressed as C={JT,TT i |i∈[0,N)}. Suppose a job J consists of m map (mapping) tasks and r reduce tasks. Since it is generally believed that the reduce task does not have data locality problems, it is not considered in this embodiment. A job can be simplified as J={M i |i∈[0,m)}. For the input data of a job, Hadoop defaults to a map task corresponding to an input data block, then the input data of the job can be expressed as I={B i |i∈[0,m)}. Then ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More