

Automatic voice recognizing method and system
An automatic speech recognition and speech technology, applied in speech recognition, speech analysis, instruments, etc., can solve problems such as difficulty in obtaining recognition results, data offset, and low recognition accuracy, so as to improve recognition accuracy and reduce data offset The effect of the probability
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

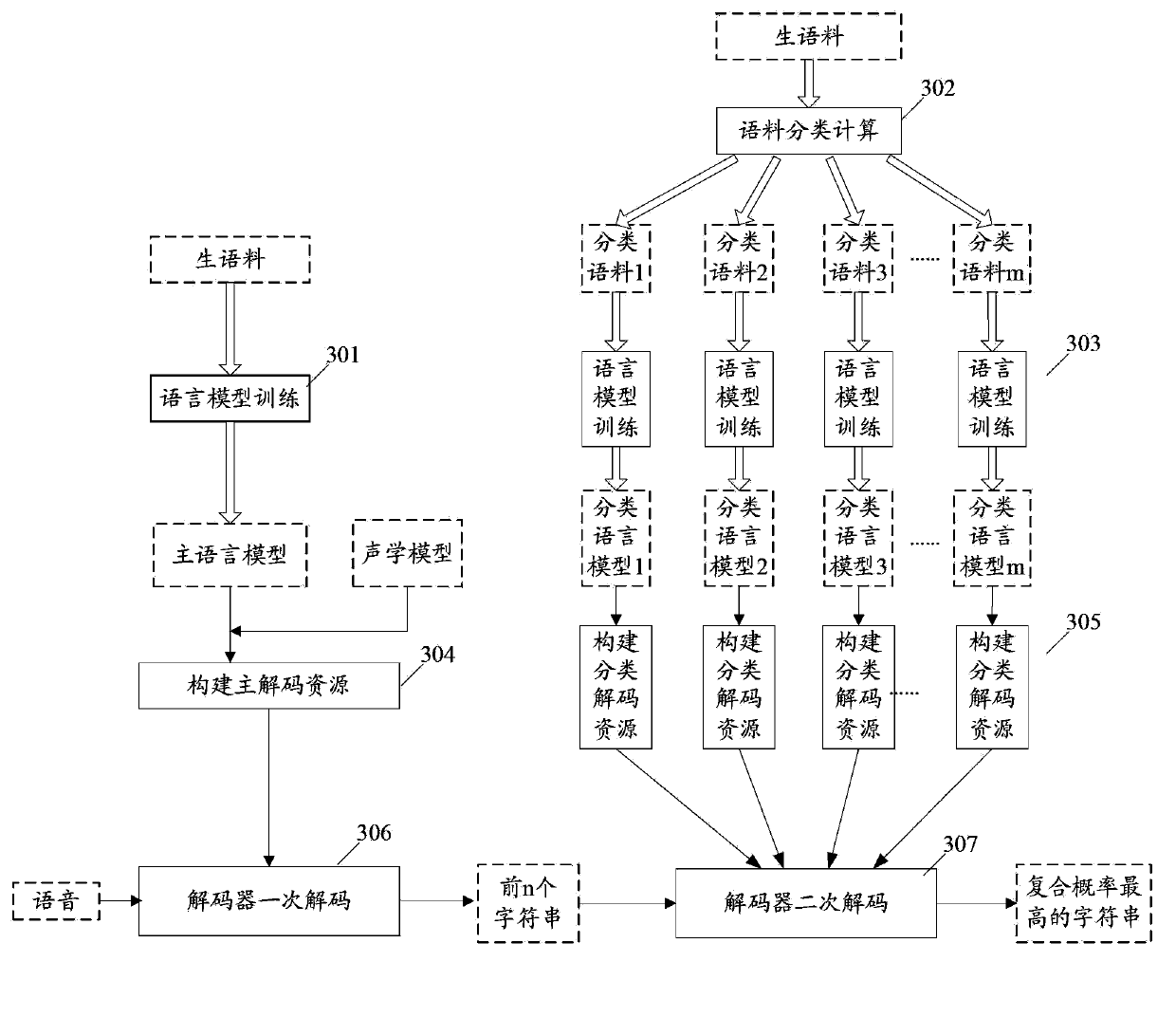
Examples
Embodiment Construction
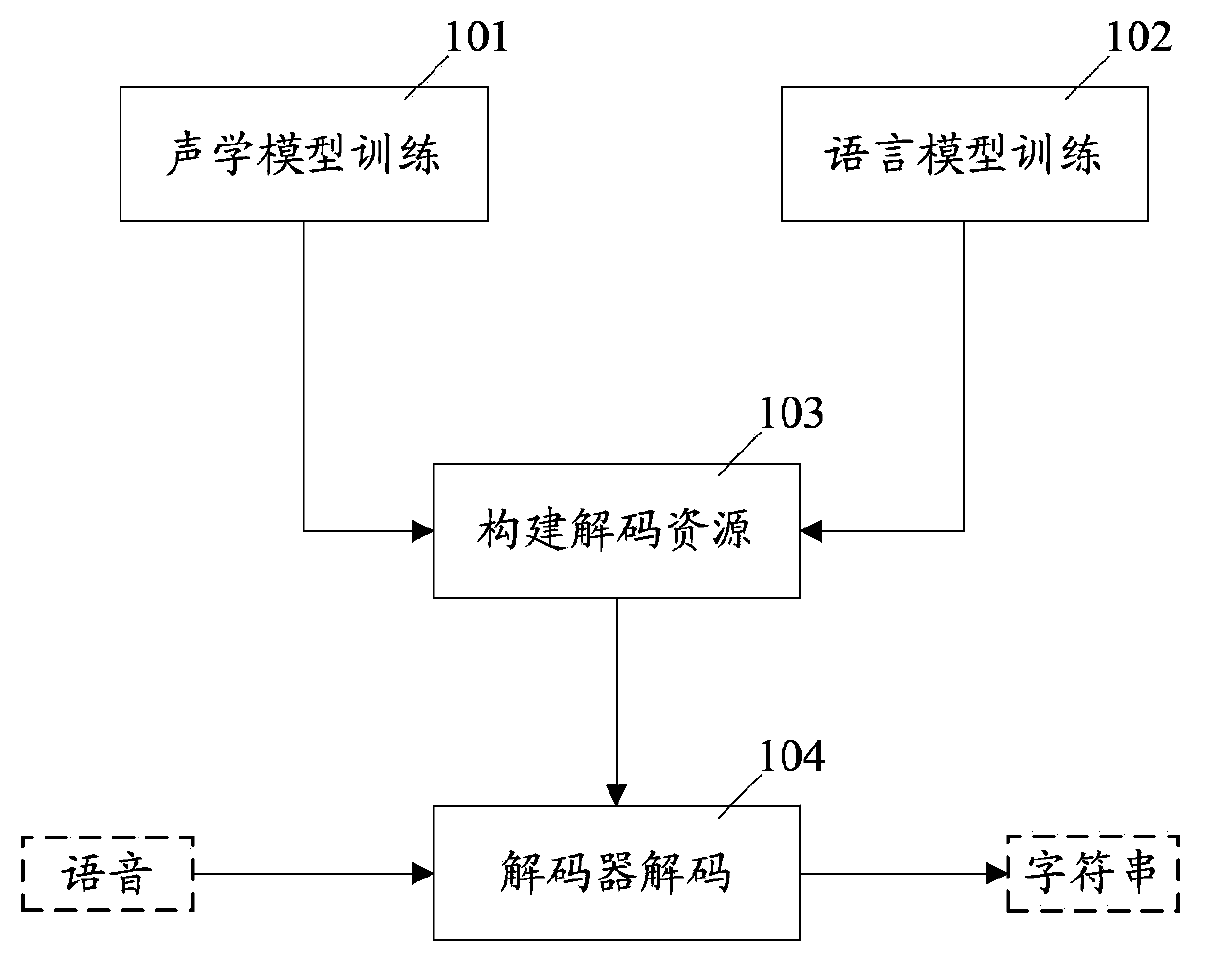
[0050] The present invention will be further described in detail below in conjunction with the drawings and specific embodiments.
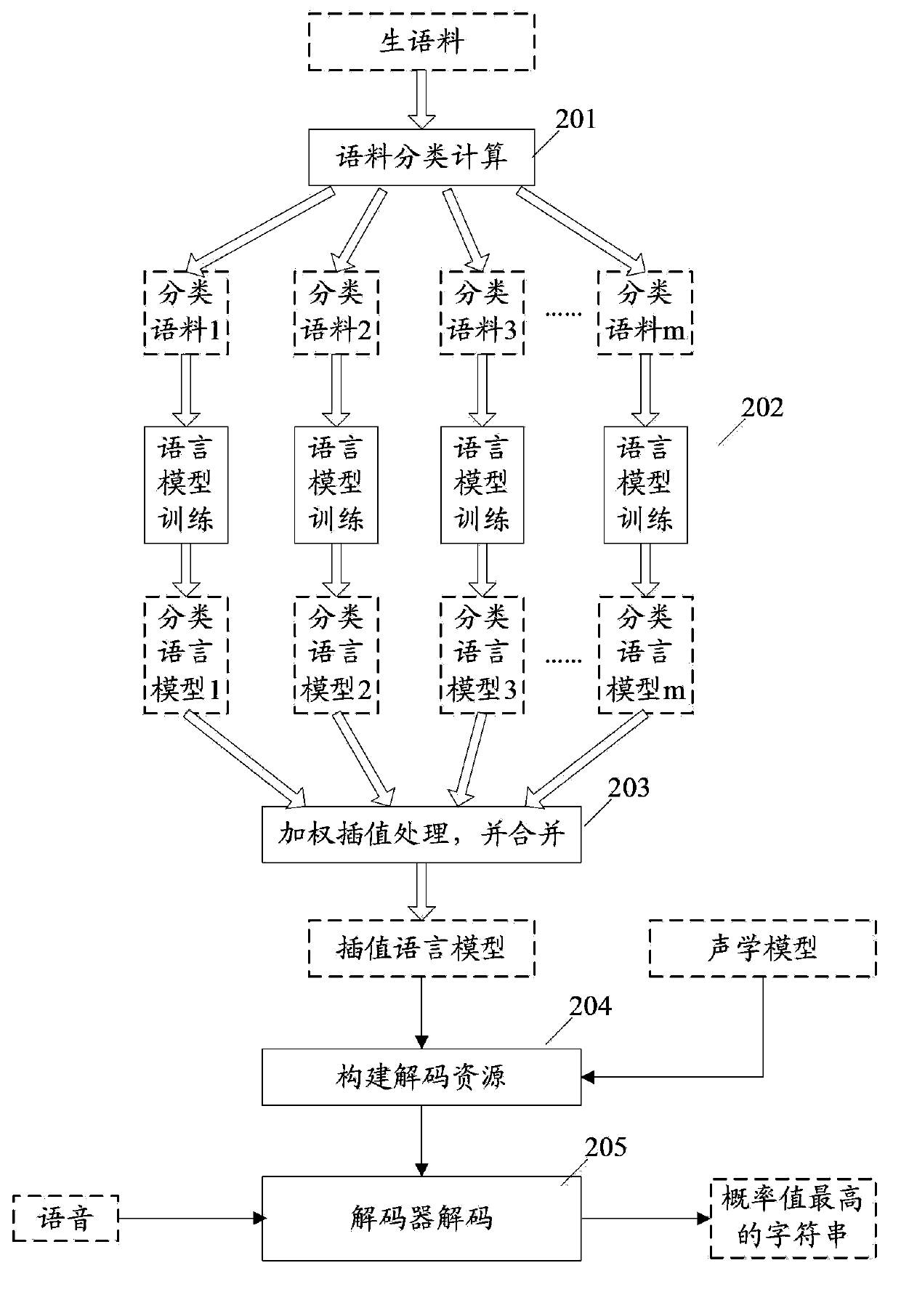
[0051] figure 2 It is a processing flow chart of the automatic speech recognition method of the present invention. See figure 2 , The process includes:
[0052] Step 201: Perform corpus classification calculation on the raw corpus to obtain more than one classified corpus of different categories. For example, the classification corpus can be divided into person name category, place name category, computer term category, medical term category and so on. For example, "Banlangen" belongs to the medical term category. A word may also belong to multiple categories.
[0053] Step 202: Perform language model training calculations for each classified corpus to obtain more than one corresponding classified language model.
[0054] Step 203: Perform weighted interpolation processing for each of the classification language models according to the degree of unco...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More