

Unbalanced data classification method
A data classification and balancing technology, applied in database models, relational databases, electrical digital data processing, etc., can solve problems such as unfavorable classification effects, large randomness, and limited hyperplane adjustment
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment
[0115] The present invention is described in further detail in conjunction with accompanying drawing and specific embodiment:
[0116] First, some symbols are defined. Given a set L of all labeled data, the n data points closest to non-similar points form the initial training set T.
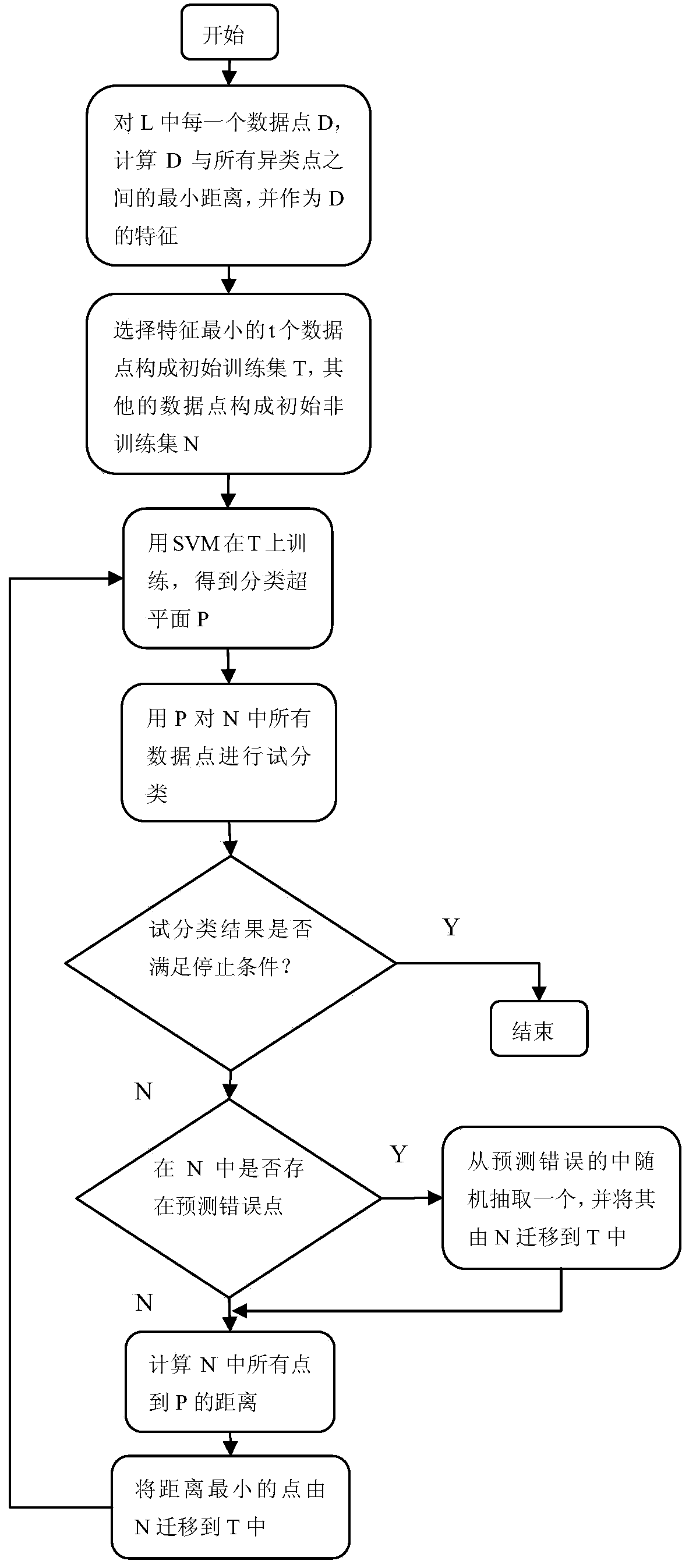
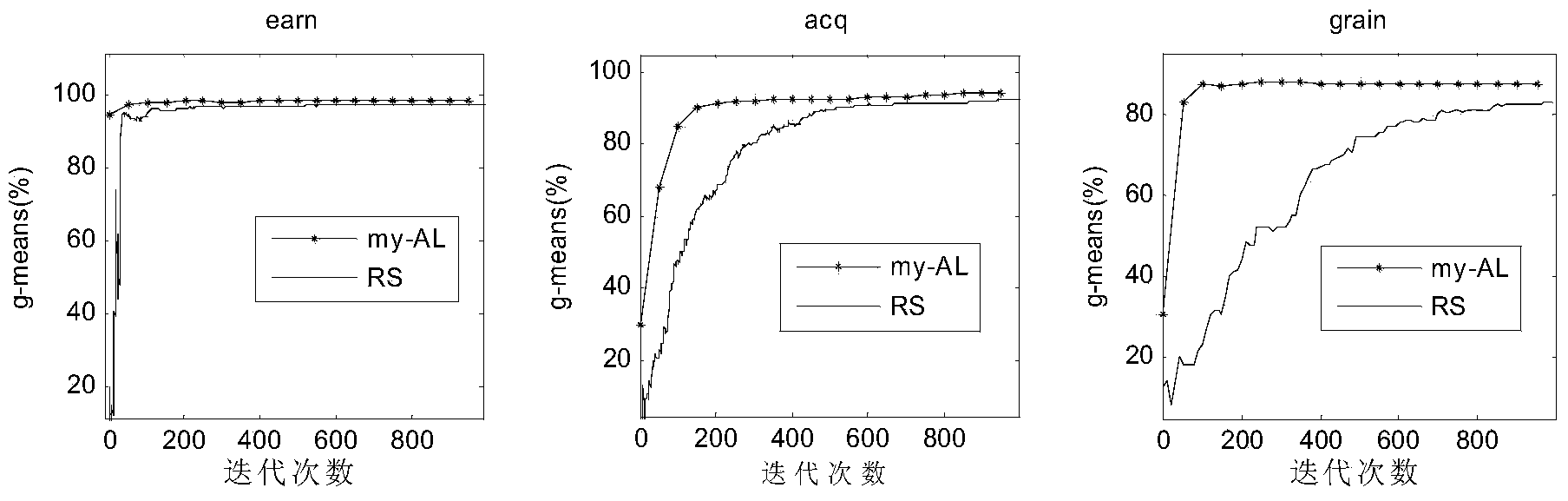
[0117] Such as figure 1 As shown, this embodiment discloses a method for classifying unbalanced data, including the following steps:
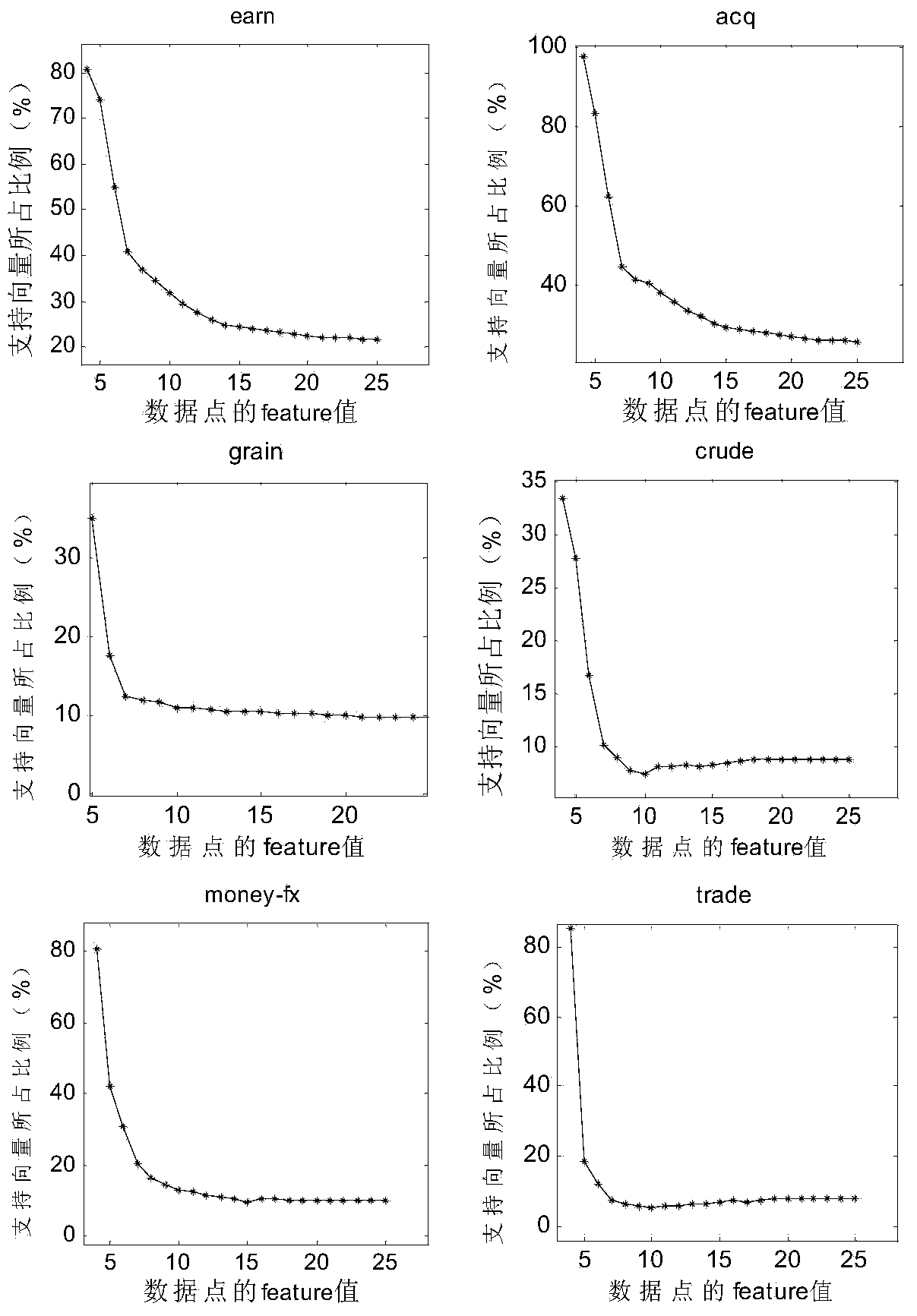
[0118] Step 1. For a given class-labeled data set L, calculate the distance between each data point and all non-similar points. For each data point, record the minimum distance between it and non-similar points as the point feature;
[0119] Step 2: Arrange the features of all data points in increasing order, select the first t data points with the smallest features as the training set T at the beginning, and the rest of the data points form the non-data set N, t theoretically ranges from 2 to m The natural number of , where m is the total number of data points...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More