Method for removing repeating data before data storage
A technology for data storage and data duplication, applied in the input/output process of data processing, electrical digital data processing, special data processing applications, etc. problem, to achieve the effect of improving effective utilization, reducing the probability of deleting false positives, and reducing bandwidth utilization.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
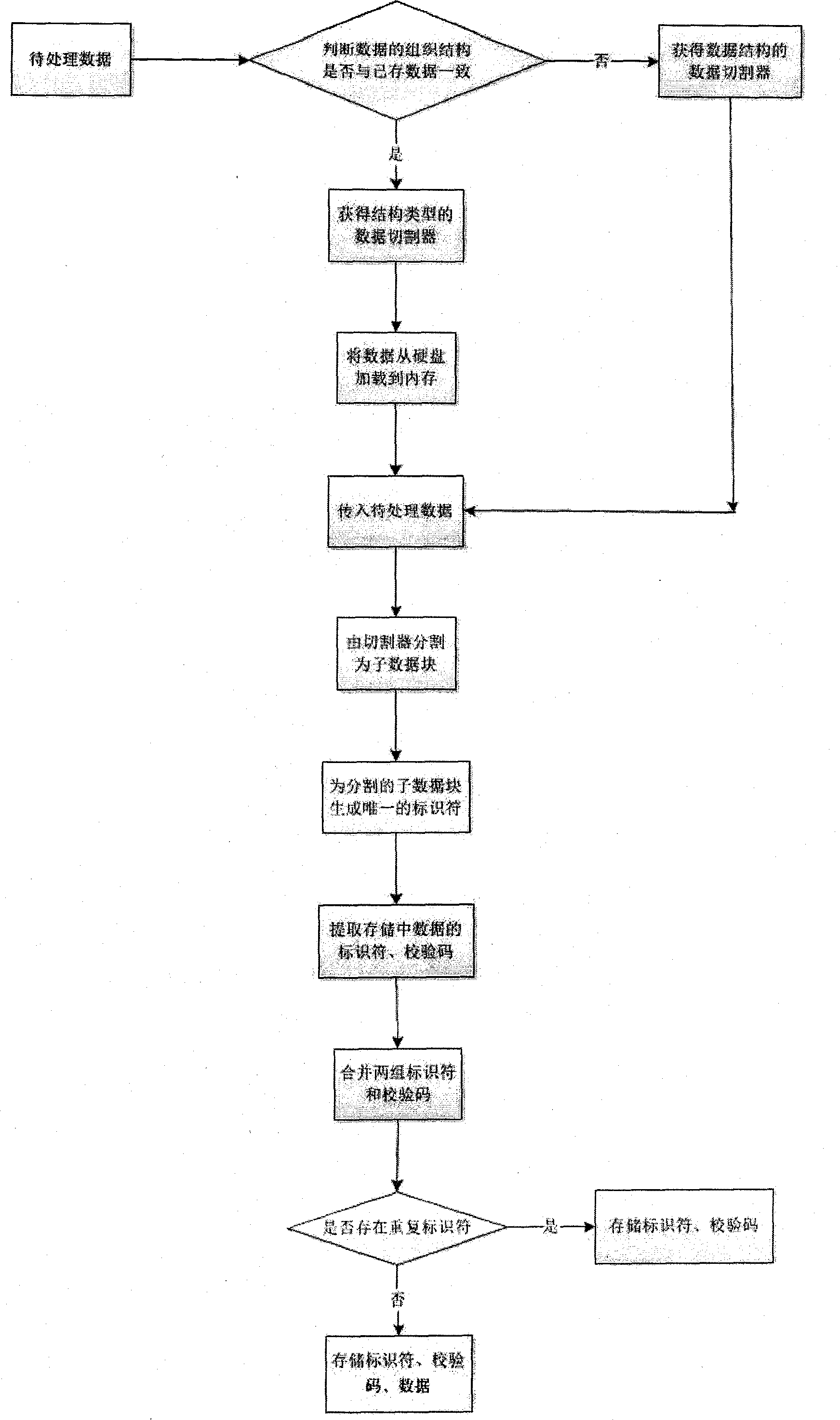
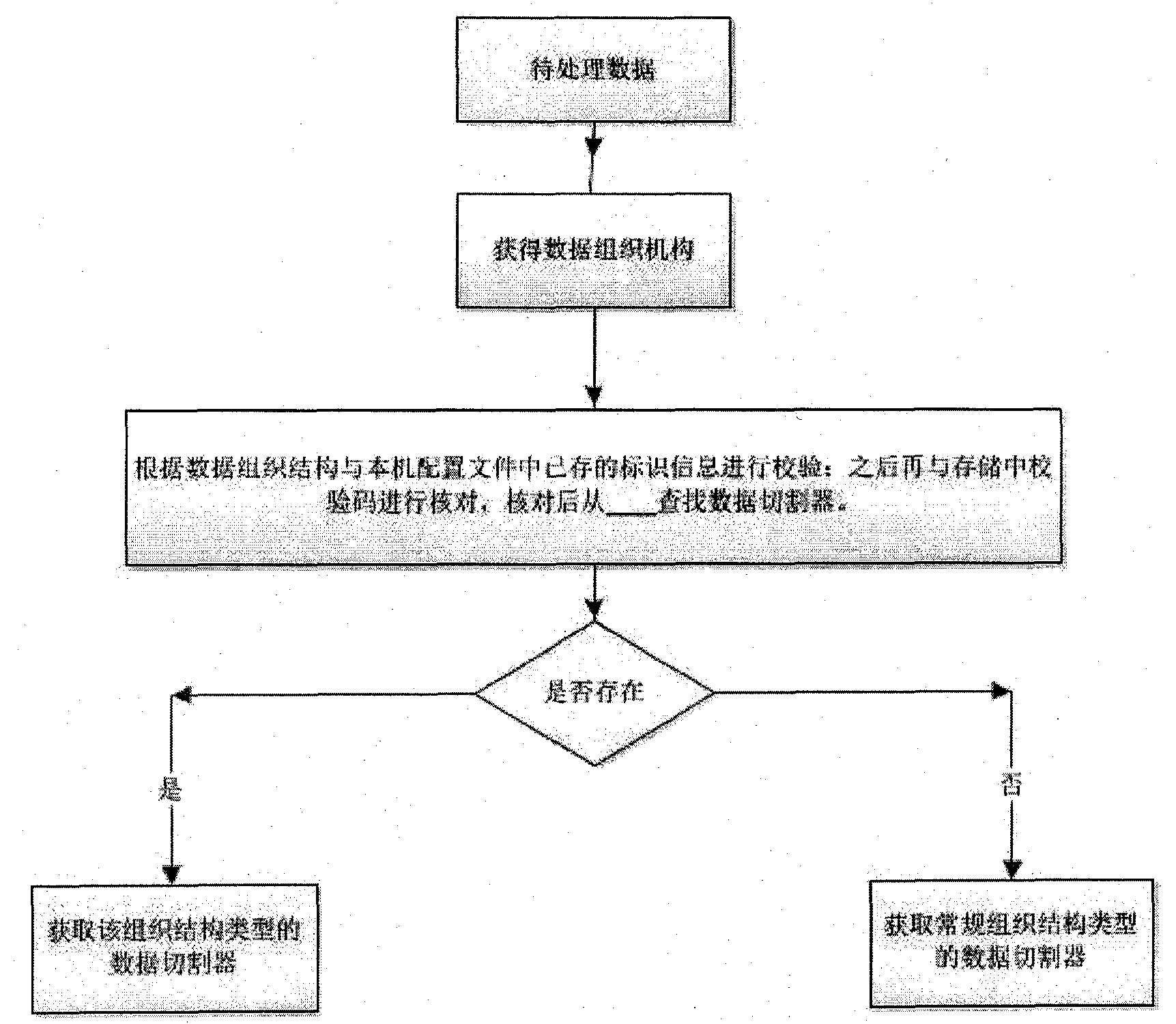
[0021] The present invention proposes a method for removing duplicate data before data storage, and the specific data storage process is as follows figure 1 , first obtain the data to be stored, which we call the data to be processed, and judge whether the organization structure of the data to be processed is consistent with the existing data. If it is consistent, obtain the data cutter of its structure type, then load the data from the hard disk to the memory, and pass in the data to be processed; if not, obtain the data cutter of the data structure, and pass in the data to be processed. The essence of the data cutter is an algorithm for dividing data into blocks. The size of the data block is set. A variable-sized data block can be divided by a sliding window. When the Hash value of the sliding window matches a reference value , a block is created. The data to be processed is divided into sub-data blocks by the cutter, and the MD5 value of the data block is calculated to ge...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More