

Text similarity measuring system based on multi-feature fusion
A text similarity and multi-feature fusion technology, applied in the field of semantic-based text similarity measurement method and system, can solve the problems of lack of semantics, large difference in text length, and low accuracy of similarity results
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

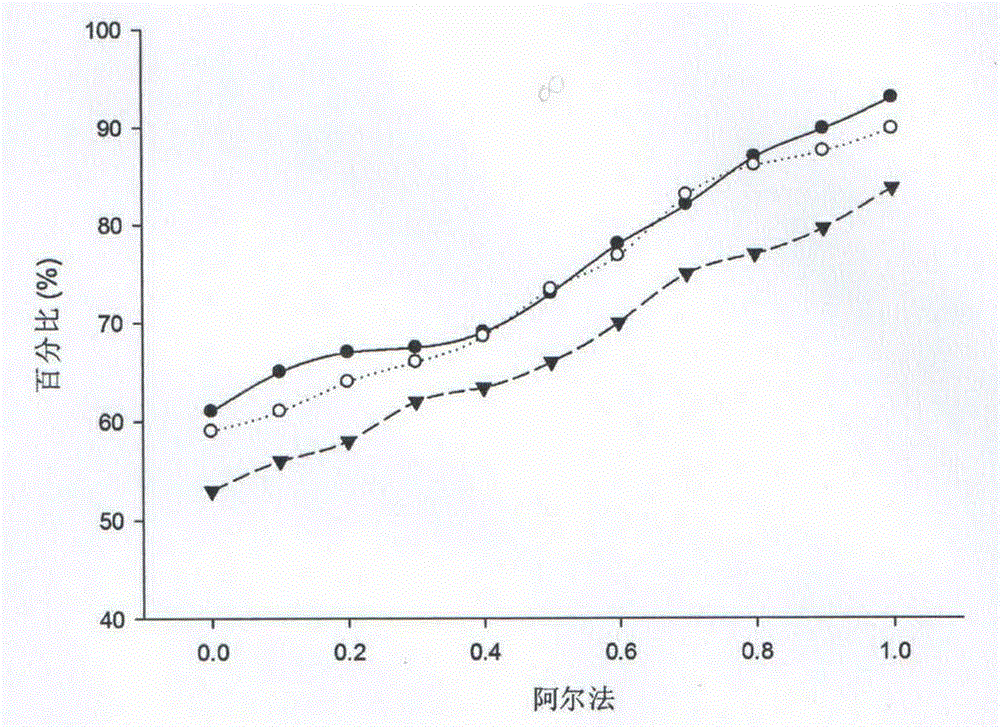
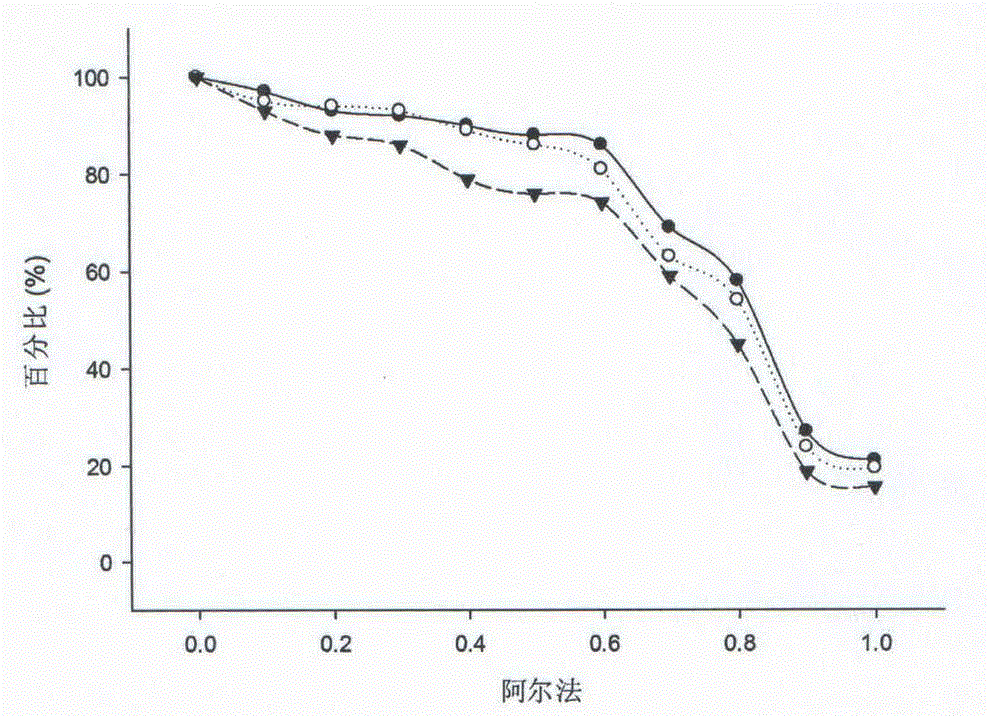
Examples
Embodiment
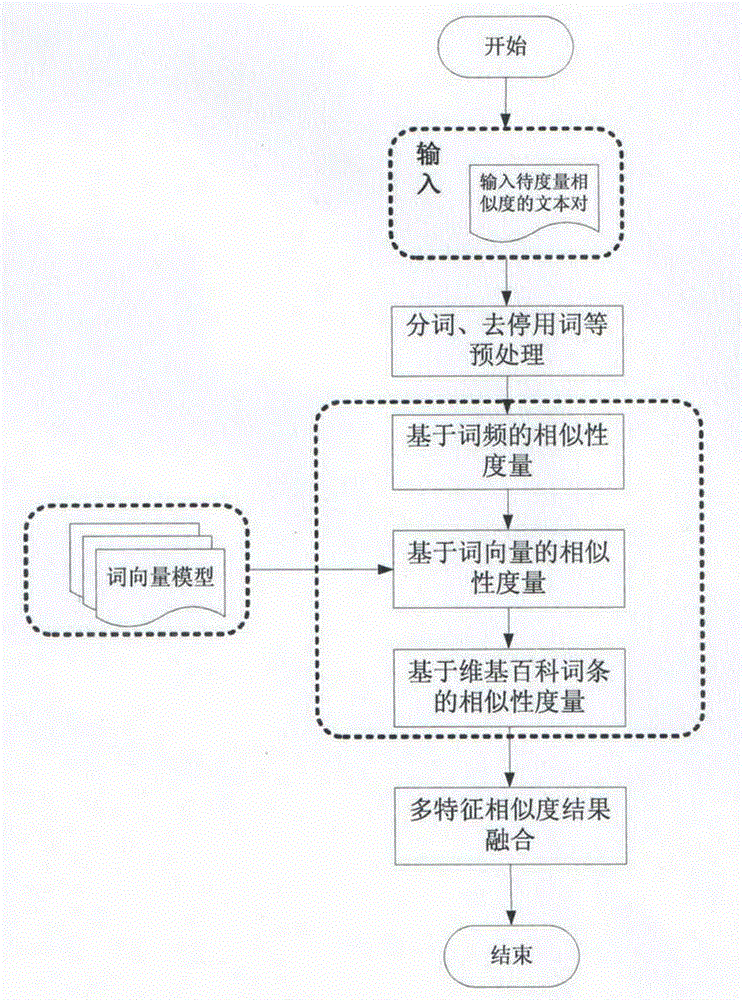
[0066] In order to make those skilled in the art better understand the present invention, the present invention will be described in further detail below in conjunction with the accompanying drawings:
[0067] as attached figure 1 Shown, the present invention comprises the following steps:
[0068] Training text preprocessing: Preprocessing the training text, word segmentation, removing stop words, and removing punctuation marks; for example, for sentence A: "The leader reprimanded the staff" and sentence B: "The employee was criticized by the boss", after word segmentation, After removing stop words and removing punctuation marks, it is expressed as A: [leadership, reprimand, employee] and B: [employee, boss, criticism];
[0069] Word vector model training: In order to obtain the semantic features between words in the text, the deep learning method is used to perform multiple iterations to train the text, and each vocabulary in the training text set is represented as a 200-d...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More