

A data storage method for massive unstructured data
A technology for unstructured data and data storage, which is used in electrical digital data processing, special data processing applications, instruments, etc. It can solve the problem of unpredictable sources, total data size, large metadata scale, and inability to guarantee large files, etc. problems, to improve retrieval efficiency, reduce complexity, and reduce data merging and migration.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
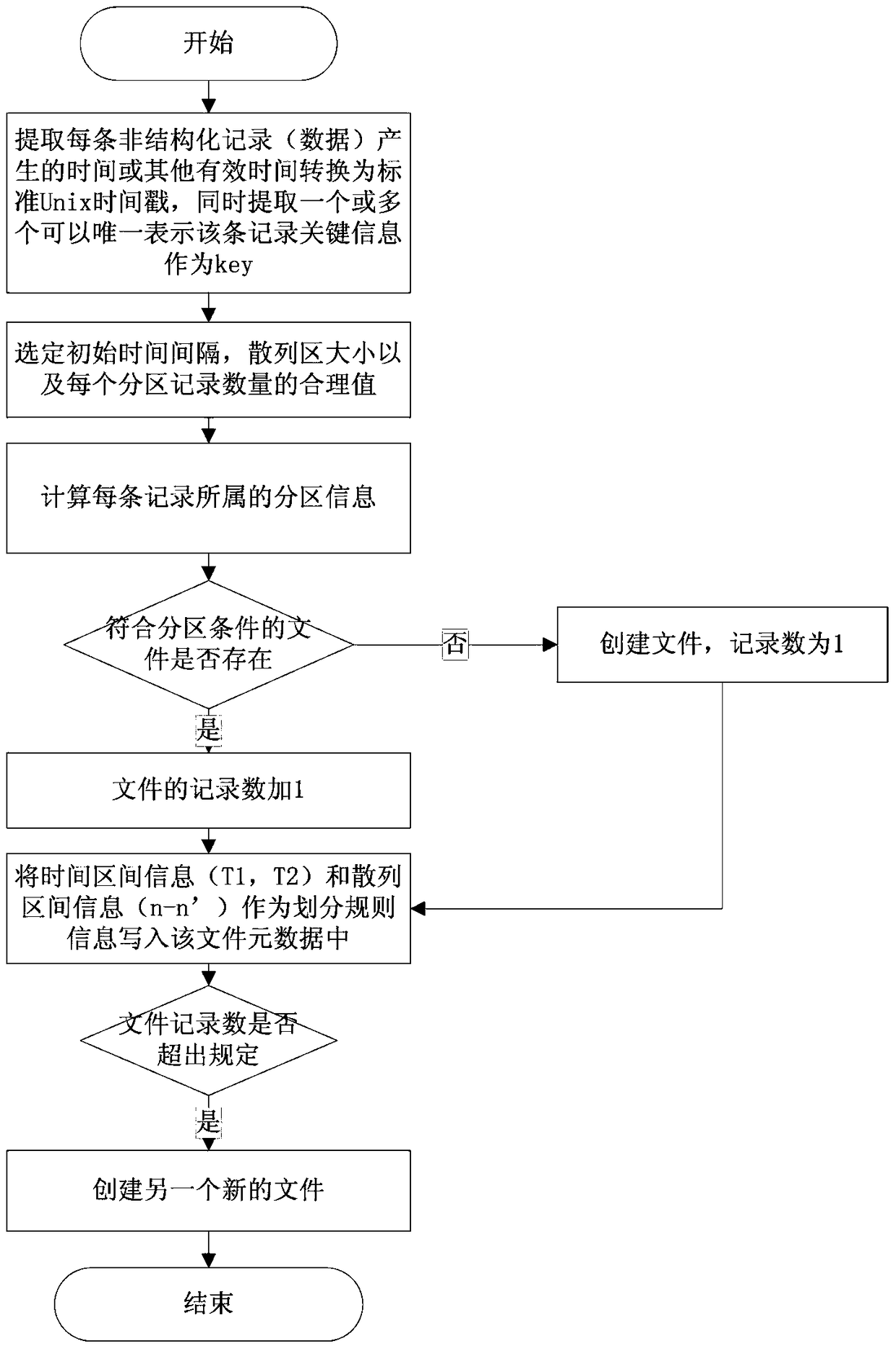
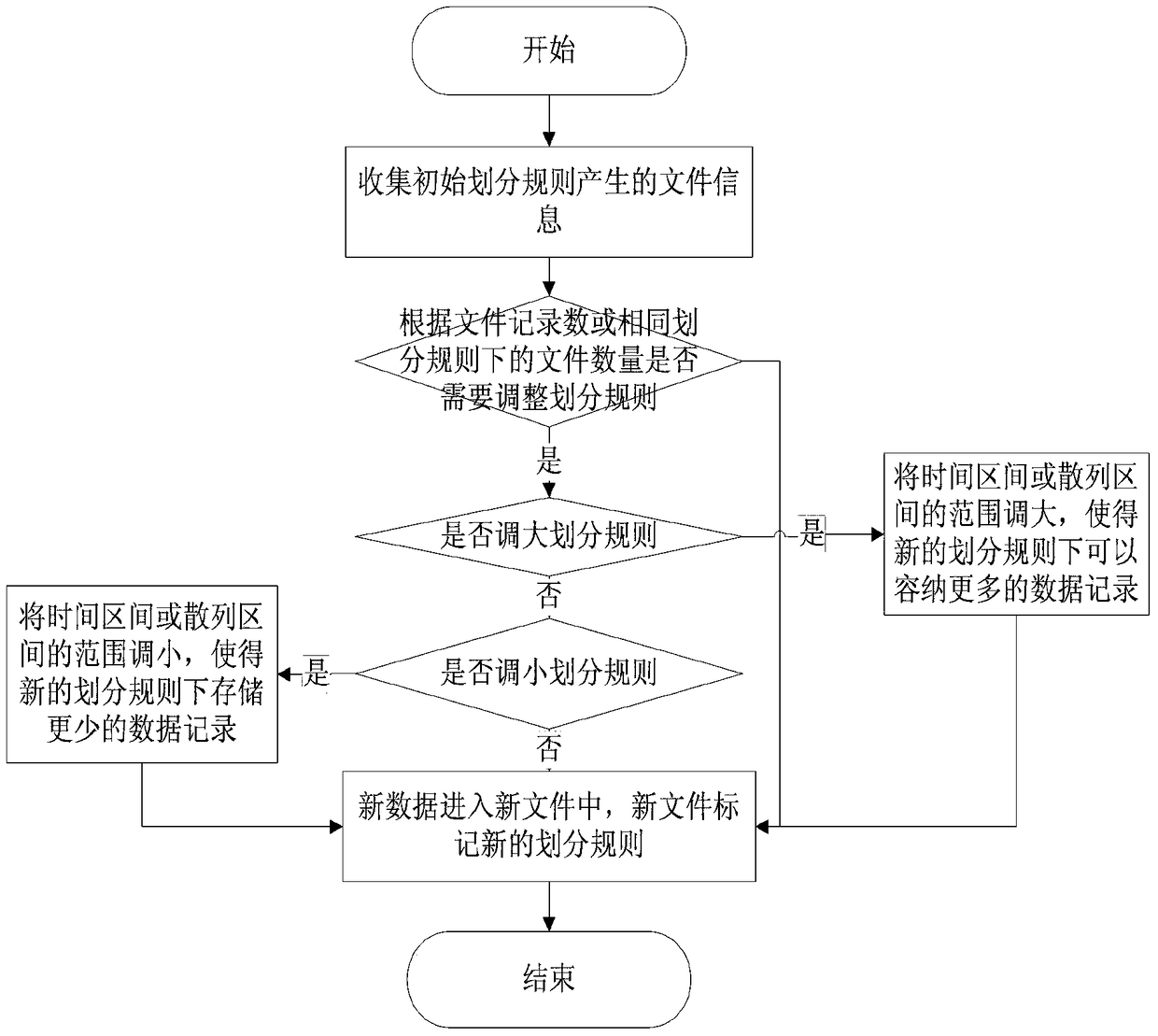
[0056] In order to make the purpose, technical solution and advantages of the present invention clearer, the hierarchical and segmented backup data organization and management method according to an embodiment of the present invention will be further described in detail below in conjunction with the accompanying drawings.
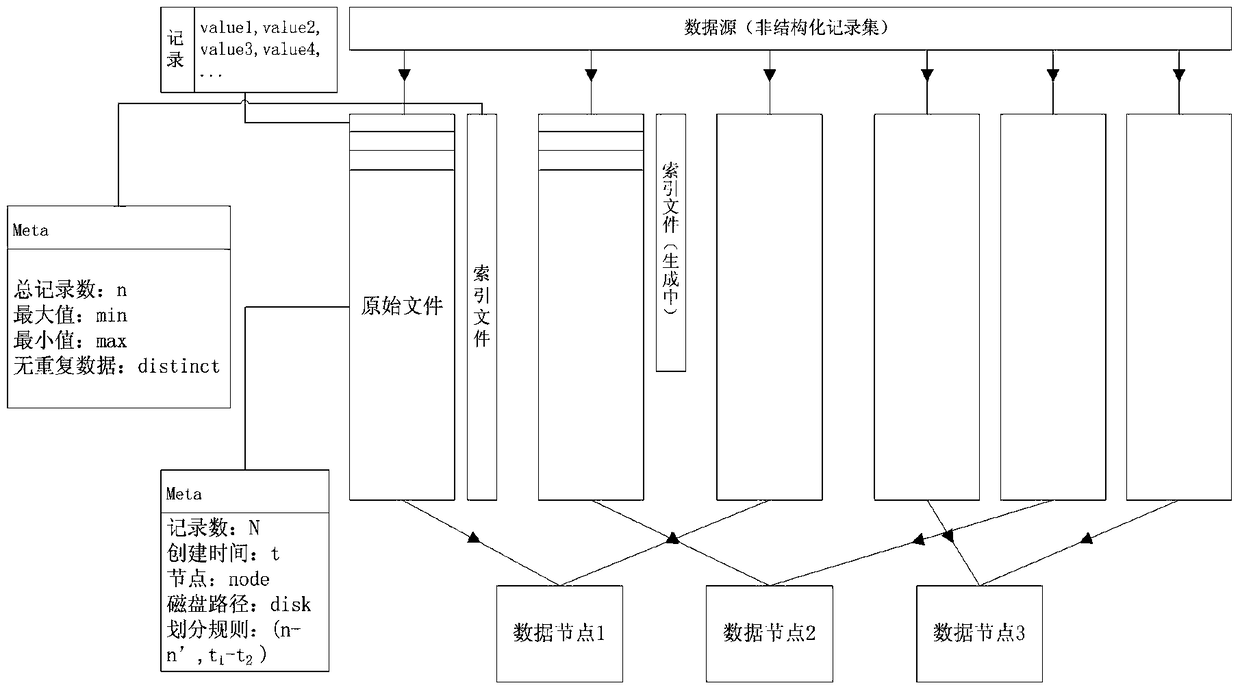
[0057] figure 1 A schematic diagram of the data model that supports the time interval and hash two-level division method is given. Under this data model, the metadata information of the original file mainly includes the file name, the number of records in the file, the division rule to which the file belongs, the node where the file is located, and the file The disk, file creation time and other information, the metadata of the index file includes information such as maximum value, minimum value, total number of records, number of non-duplicate records, etc. Through the setting of the above elements, it effectively provides various information needed in the...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More