

Self-adaption web crawler method based on machine learning
An adaptive network and machine learning technology, applied in the computer field, to improve the efficiency of information retrieval and reduce time costs
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
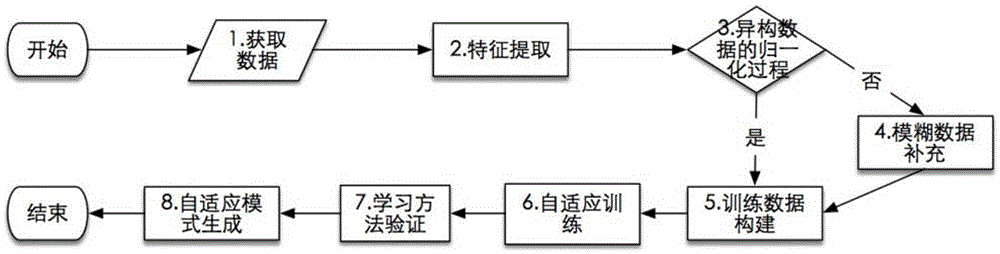
[0029] Some embodiments of the accompanying drawings of the present invention are described in more detail below. In this example: the HTML codes of webpages A and B are known, and the crawler mode in webpage C is adaptively output.
[0030] according to figure 1 , the present invention is built on the basis of data mining and machine learning technology, and specific implementation method has:
[0031] 1. Get data:
[0032] Get the entire page code provided by the browser plug-in and the position of the part of the code that needs to be crawled on the entire page. The position is expressed as an array, and each number in the array indicates the number of the line of code in the entire page code. the number of . For example, the position array [1,2,6,3,1,2,1,3,2,2,1], the first 1 in the array represents the outermost first-level label in the entire page code, that is html; the second 2 means the second tag body under the upper html tag; the third 6 means the sixth tag unde...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More