

Data clustering method based on dimensionality reduction and sampling
A data clustering and clustering technology, applied in the field of data processing, can solve problems such as ineffective processing, and achieve the effect of reducing complexity and efficient clustering
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

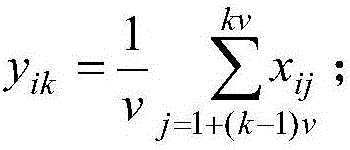
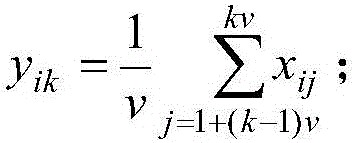
Examples
Embodiment Construction
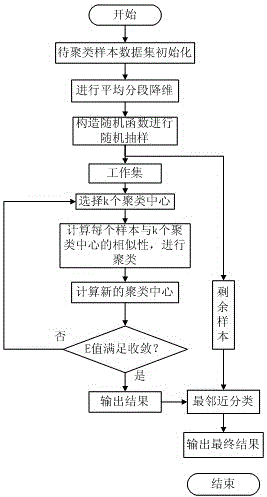
[0021] The present invention will be further described below in conjunction with accompanying drawing.
[0022] The present invention provides a fast large-scale data clustering analysis method with data clustering analysis capability. The method firstly performs dimensionality reduction processing on the data set through the segmented mean method, and secondly constructs a random function from the large-scale clustering data set. Perform random sampling to obtain a smaller working set, and perform traditional k-means clustering on the working set to obtain the cluster center, complete the sampling process, and obtain the sampling result. Then classify the remaining samples by measuring the relationship between the remaining clustered samples and the obtained sampling results. Since this method greatly reduces the scale of problems involved in k-means clustering through random sampling, it effectively improves the clustering efficiency.
[0023] Let data set X={x 1 ,x 2 ,.....
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More