

A Suspicious Point Discrimination Method Based on Measured Data
A technology of measured data and discrimination method, applied in the direction of electrical digital data processing, special data processing applications, instruments, etc., can solve the problems of low accuracy, slow speed, unreal data, etc., to reduce maintenance, reduce economic losses, save money artificial effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
specific Embodiment approach 1
[0028] Specific implementation mode one: combine figure 1 Describe this embodiment, a method for discriminating suspicious points based on measured data in this embodiment is specifically carried out in accordance with the following steps:
[0029] cluster analysis method
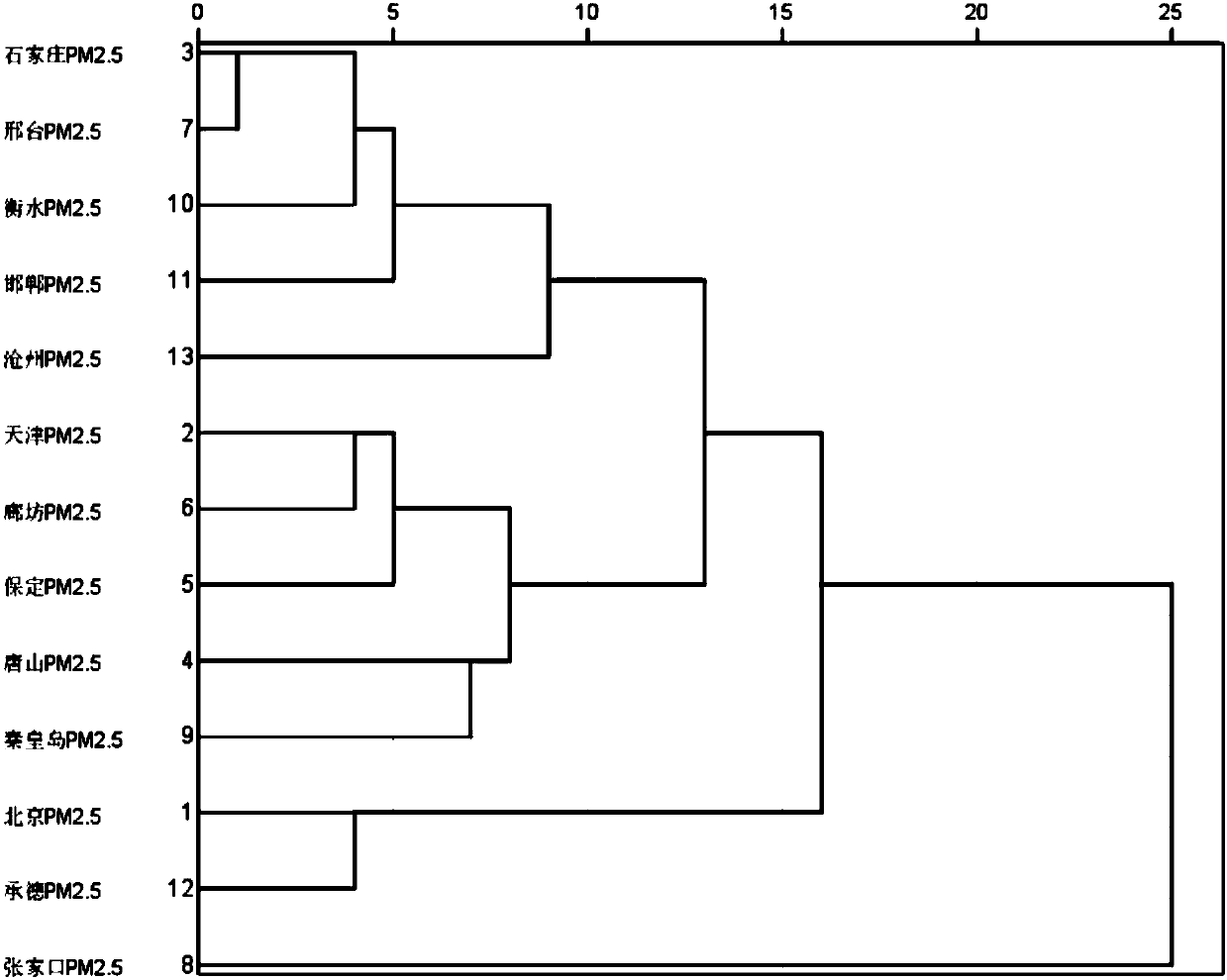
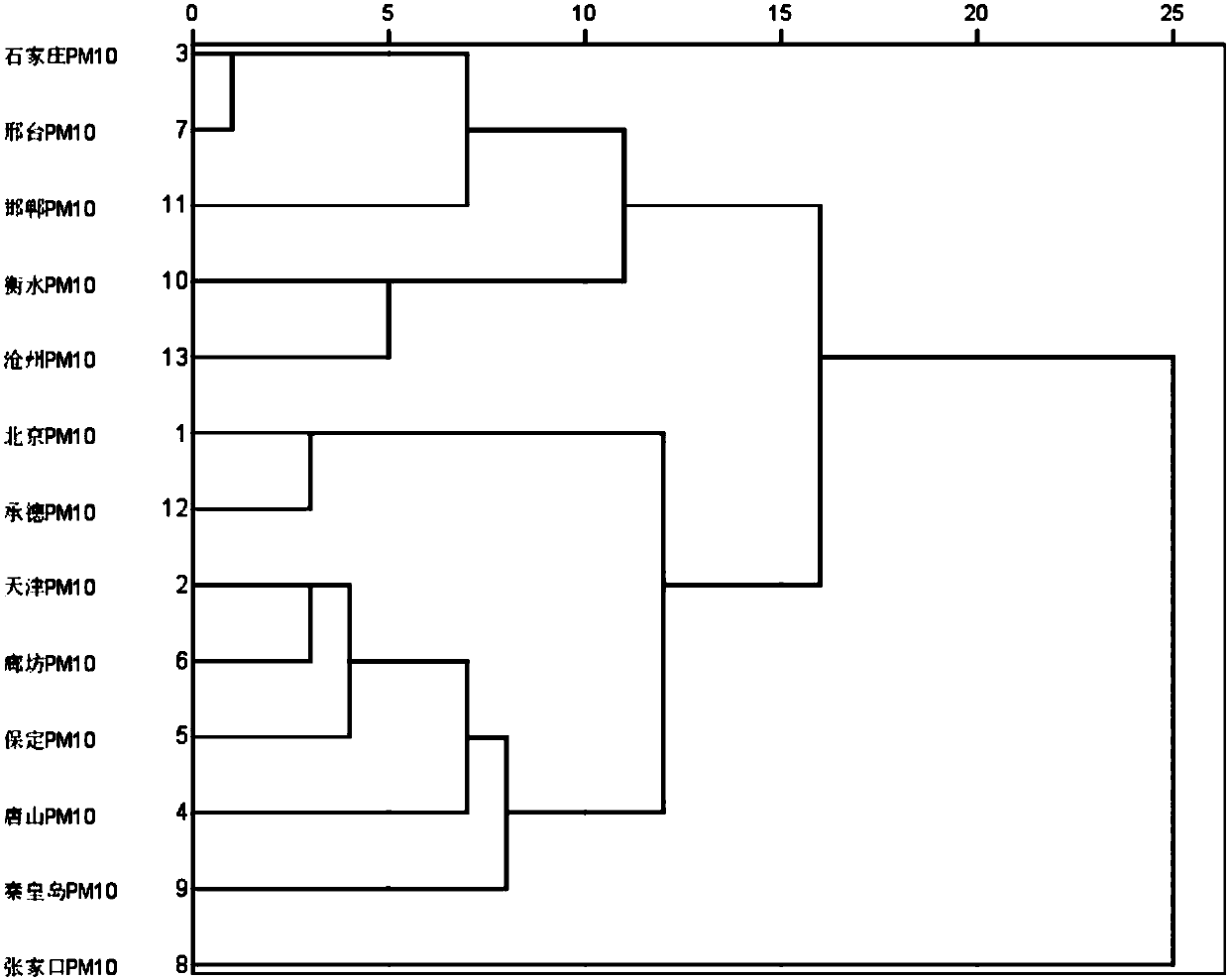
[0030] Cluster analysis, also known as group analysis, is a multivariate statistical method to study and classify samples or indicators according to the characteristics of errors themselves. The so-called "class", in layman's terms, is a collection of similar elements. The principle of cluster analysis is to directly compare the properties of various things, classify those with similar properties into one class, and classify those with large differences in properties into different classes.
[0031] Cluster analysis is a new branch of practical multivariate statistical analysis. It is in the development stage. Although it is not perfect in theory, it can solve many practical problems. Therefore, this met...
specific Embodiment approach 2
[0101] Specific embodiment 2: The difference between this embodiment and specific embodiment 1 is that in the step 1, the distance between any two measured data positions in the n measured data positions is calculated to obtain the n measured data positions The distance matrix between, the value range of n is a positive integer; the specific process is called:
[0102] The distance between any two measured data locations among the n measured data locations is obtained through the Pearson correlation coefficient distance.
[0103] Other steps and parameters are the same as those in Embodiment 1.
specific Embodiment approach 3
[0104] Specific embodiment three: this embodiment is different from specific embodiment one or two in that: when i=2 in the step three, the two classes with the smallest inter-class distance obtained in step two are merged to form a new class, here When the number of classes k=n-1; calculate the distance between the new class and other classes to obtain a new inter-class distance matrix; the specific process is called:
[0105] The distance between the new class and other classes is calculated by the default method of the SPSS (Statistical Product and Service Solution) software, the inter-class average chain method, and a new inter-class distance matrix is obtained.
[0106] Using the Hierarchical Cluster method of SPSS software, cluster analysis was performed on a data value data of different samples. The specific clustering method is the Between-groups linkage method, and the Pearson correlation coefficient (Pearson correlation) is selected for the distance measurement. T...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More