

Chinese zero anaphora resolution method based on LSTM
A technology of referring to resolution and Chinese, applied in semantic analysis, natural language data processing, special data processing applications, etc., can solve the problems of low accuracy of Chinese zero-reference resolution tasks and low accuracy of semantic information understanding
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
specific Embodiment approach 1
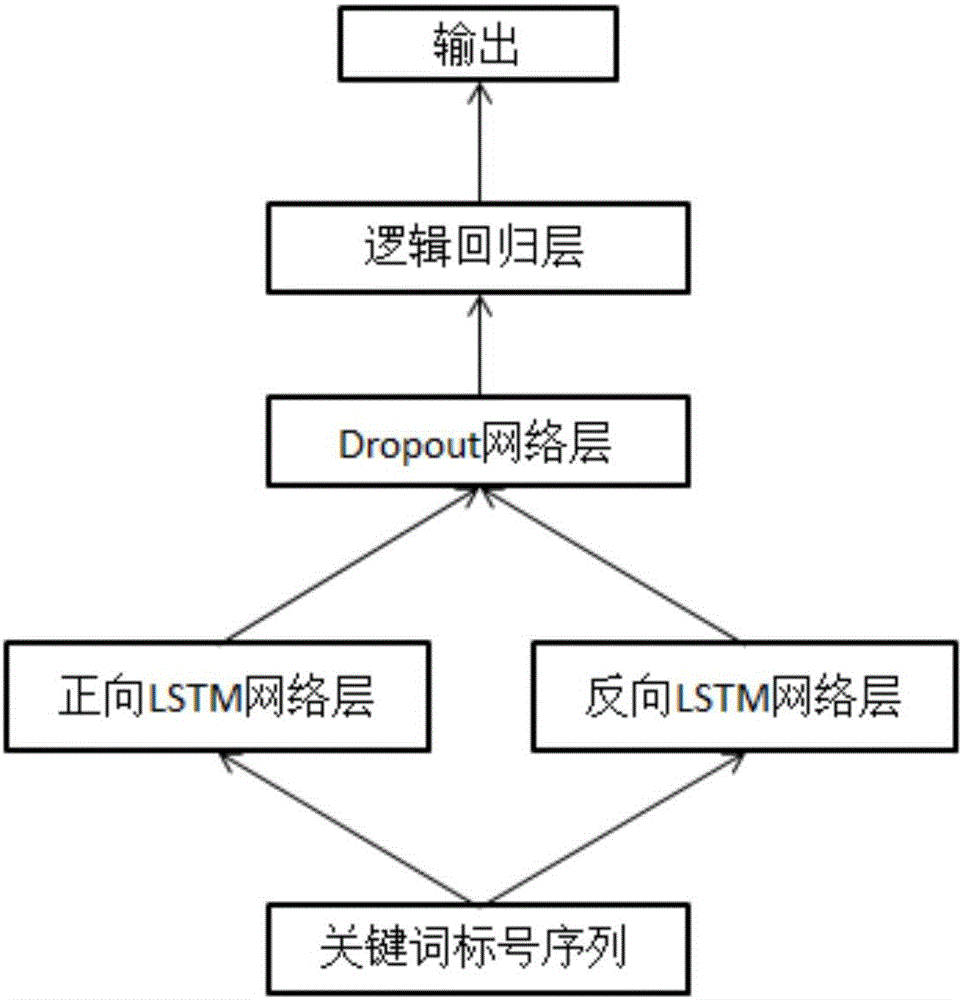
[0028] Specific implementation mode one: combine figure 1To illustrate this embodiment, a Chinese zero-reference resolution method based on word vectors and bidirectional LSTM in this embodiment is specifically prepared according to the following steps:
[0029] Step 1. Simply process each word in the existing text data, and use the word2vec tool to train each word in the processed text data (word2vec is an open source software, which is specially used to convert the text of good words Through the internal model, the words are converted into corresponding vectors), and a word vector dictionary is obtained, in which each word corresponds to a word vector;
[0030] Step 2. Use the Chinese part of the data in the OntoNotes5.0 corpus. The zero reference and its antecedent of the sentence in the Chinese part of the data are clearly marked; for the sentence text that has marked the zero reference position, first use the syntax analysis tool (A tool that converts sentences into a tr...
specific Embodiment approach 2
[0036] Specific embodiment 2: the difference between this embodiment and specific embodiment 1 is: the process of simple processing of existing text data in the step 1 is: use word segmentation program to carry out word segmentation to sentences in existing text data, Remove special characters, and only keep Chinese characters, English and punctuation (special characters such as Greek letters, Russian letters, phonetic symbols, special symbols, etc.).
specific Embodiment approach 3
[0037] Specific embodiment three: the difference between this embodiment and specific embodiment one or two is that: the processing method of the antecedent candidate set in the step two is:
[0038] Set the maximum number of words in the antecedent candidate set to n, 1≤n≤maxW, where maxW represents the maximum number of words in a sentence;
[0039] If the number of words in the antecedent candidate set is less than n, fill it with the symbol * until the number of words is equal to n;
[0040] If the number of words in the antecedent candidate set is greater than n, only the last n words are kept;
[0041] In the stage of word mapping into word vectors, * is mapped into zero vectors.
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More