Construction method of deep neural network
A deep neural network and construction method technology, which is applied in neural learning methods, biological neural network models, neural architectures, etc. The effect of avoiding convergence interference
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment
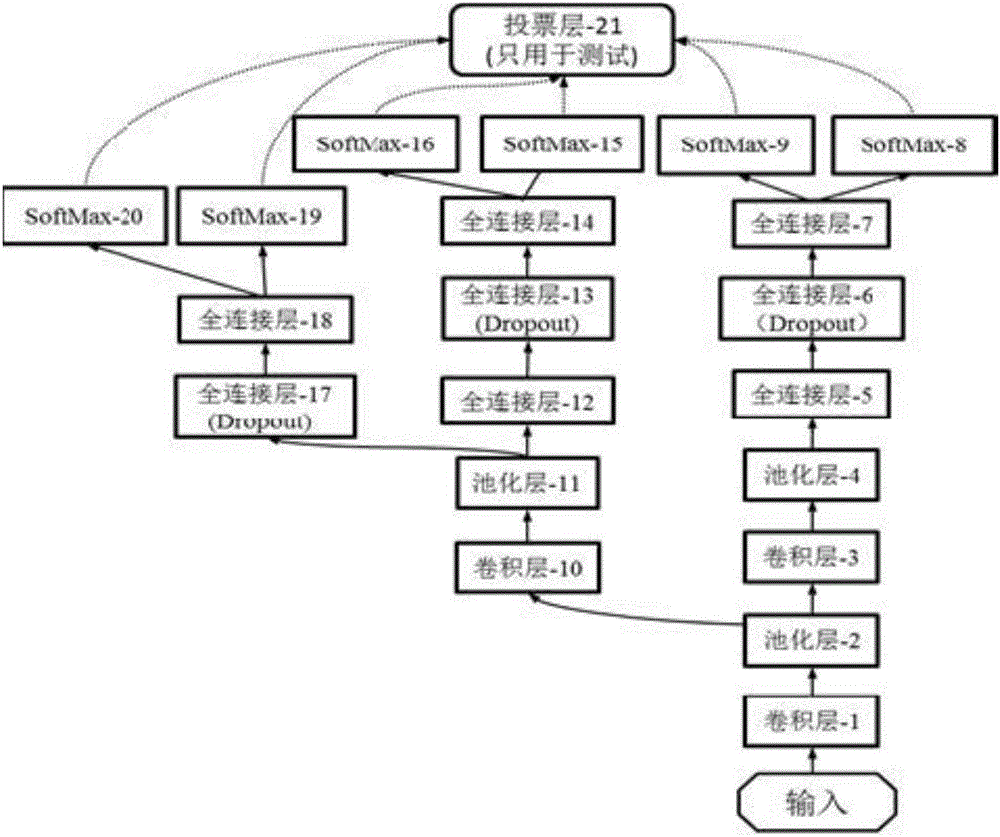
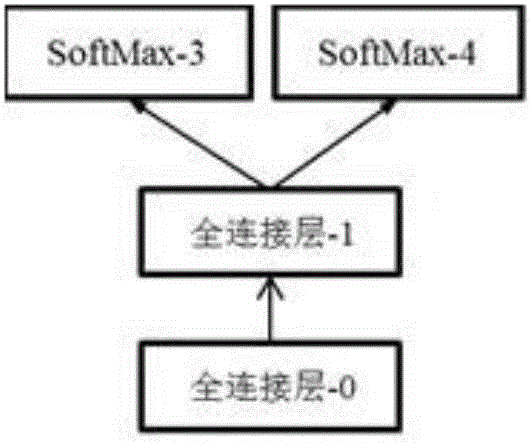
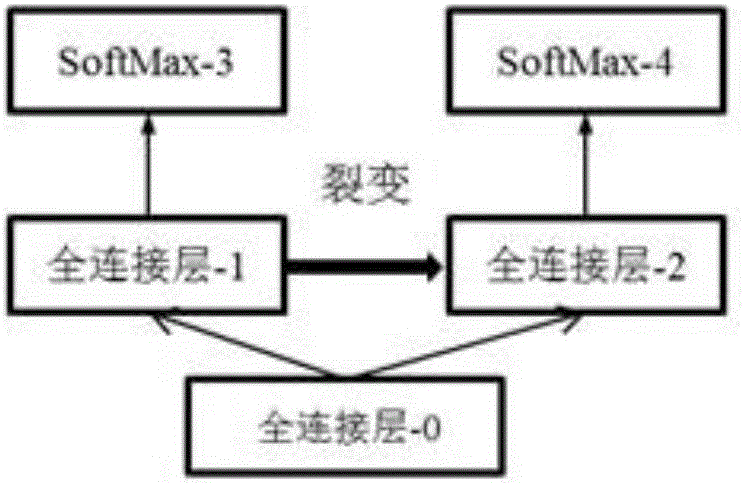
[0026] We propose a new deep neural network architecture named "Fissionable Deep Neural Network". The network structure includes multiple branches sharing parameters and multiple Softmax classifiers; and during training, the structure of the entire network changes dynamically until the entire network structure is split into multiple models.
[0027] The fissile deep neural network structure is a tree structure with shared parameters, such as figure 1 As shown, the whole structure includes input layer, convolution layer, pooling layer, fully connected layer, SoftMax layer and voting layer. The connection between each layer is carried out through data transfer. The root node is the data input layer, all leaf nodes are the Softmax layer, and the voting layer is only used during testing. The numbers following the names of each layer are just to better distinguish each layer and have no other meaning. The path from the root node to a certain leaf node is a neural network with a l...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More 
PatSnap Eureka turns technology decisions into work you can execute. Powered by our Innovation Knowledge Graph, it runs expert workflows across engineering, life sciences, materials and intellectual property. Get your review-ready output in minutes.



