

Improved text similarity solution method
A text similarity, text technology, applied in the improved text similarity solution field, can solve the problems of not considering the difference in importance, low accuracy, no internal connection, etc., and achieve the effect of high accuracy and good applicability
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

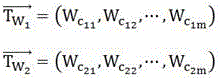
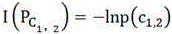
Examples
Embodiment Construction
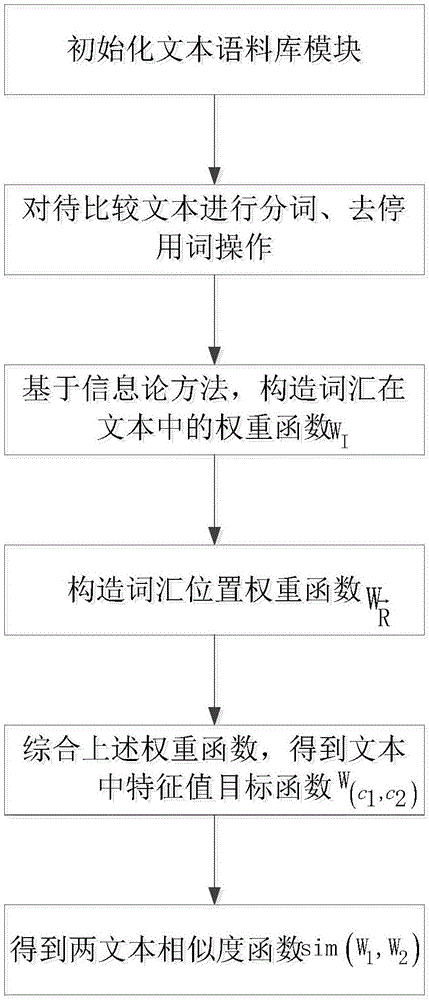
[0015] In order to solve the difference in the importance of different words in the text in the feature words to the text, combined with figure 1 The present invention has been described in detail, and its specific implementation steps are as follows:
[0016] Step 1: Initialize the text corpus module, treat the comparison text (W 1 , W 2 ) for preprocessing, the specific description process is as follows:
[0017] The text (W 1 , W 2 ) for word segmentation and stop word processing.
[0018] Step 2: Based on the information theory method, calculate the weight value W of the vocabulary in the text I , the specific calculation process is as follows:
[0019] The formulas for calculating word frequency based on information theory are:
[0020]
[0021] above formula is the amount of information that the vocabulary has in the document about the word frequency, p(c 1,2 ) respectively for word c 1 、c 2 Probability values in the text.
[0022] The formula for calcu...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More